Automated machine learning (AutoML)?
APPLIES TO:  Python SDK azureml v1
Python SDK azureml v1
Automated machine learning, also referred to as automated ML or AutoML, is the process of automating the time-consuming, iterative tasks of machine learning model development. It allows data scientists, analysts, and developers to build ML models with high scale, efficiency, and productivity all while sustaining model quality. Automated ML in Azure Machine Learning is based on a breakthrough from our Microsoft Research division.
Traditional machine learning model development is resource-intensive, requiring significant domain knowledge and time to produce and compare dozens of models. With automated machine learning, you'll accelerate the time it takes to get production-ready ML models with great ease and efficiency.
Ways to use AutoML in Azure Machine Learning
Azure Machine Learning offers the following two experiences for working with automated ML. See the following sections to understand feature availability in each experience (v1).
For code-experienced customers, Azure Machine Learning Python SDK. Get started with Tutorial: Use automated machine learning to predict taxi fares (v1).
For limited/no-code experience customers, Azure Machine Learning studio at https://ml.azure.com. Get started with these tutorials:
Experiment settings
The following settings allow you to configure your automated ML experiment.
| The Python SDK | The studio web experience | |
|---|---|---|
| Split data into train/validation sets | ✓ | ✓ |
| Supports ML tasks: classification, regression, & forecasting | ✓ | ✓ |
| Supports computer vision tasks: image classification, object detection & instance segmentation | ✓ | |
| Optimizes based on primary metric | ✓ | ✓ |
| Supports Azure Machine Learning compute as compute target | ✓ | ✓ |
| Configure forecast horizon, target lags & rolling window | ✓ | ✓ |
| Set exit criteria | ✓ | ✓ |
| Set concurrent iterations | ✓ | ✓ |
| Drop columns | ✓ | ✓ |
| Block algorithms | ✓ | ✓ |
| Cross validation | ✓ | ✓ |
| Supports training on Azure Databricks clusters | ✓ | |
| View engineered feature names | ✓ | |
| Featurization summary | ✓ | |
| Featurization for holidays | ✓ | |
| Log file verbosity levels | ✓ |
Model settings
These settings can be applied to the best model as a result of your automated ML experiment.
| The Python SDK | The studio web experience | |
|---|---|---|
| Best model registration, deployment, explainability | ✓ | ✓ |
| Enable voting ensemble & stack ensemble models | ✓ | ✓ |
| Show best model based on non-primary metric | ✓ | |
| Enable/disable ONNX model compatibility | ✓ | |
| Test the model | ✓ | ✓ (preview) |
Job control settings
These settings allow you to review and control your experiment jobs and its child jobs.
| The Python SDK | The studio web experience | |
|---|---|---|
| Job summary table | ✓ | ✓ |
| Cancel jobs & child jobs | ✓ | ✓ |
| Get guardrails | ✓ | ✓ |
| Pause & resume jobs | ✓ |
When to use AutoML: classification, regression, forecasting, computer vision & NLP
Apply automated ML when you want Azure Machine Learning to train and tune a model for you using the target metric you specify. Automated ML democratizes the machine learning model development process, and empowers its users, no matter their data science expertise, to identify an end-to-end machine learning pipeline for any problem.
ML professionals and developers across industries can use automated ML to:
- Implement ML solutions without extensive programming knowledge
- Save time and resources
- Leverage data science best practices
- Provide agile problem-solving
Classification
Classification is a common machine learning task. Classification is a type of supervised learning in which models learn using training data, and apply those learnings to new data. Azure Machine Learning offers featurizations specifically for these tasks, such as deep neural network text featurizers for classification. Learn more about featurization (v1) options.
The main goal of classification models is to predict which categories new data will fall into based on learnings from its training data. Common classification examples include fraud detection, handwriting recognition, and object detection. Learn more and see an example at Create a classification model with automated ML (v1).
See examples of classification and automated machine learning in these Python notebooks: Fraud Detection, Marketing Prediction, and Newsgroup Data Classification
Regression
Similar to classification, regression tasks are also a common supervised learning task.
Different from classification where predicted output values are categorical, regression models predict numerical output values based on independent predictors. In regression, the objective is to help establish the relationship among those independent predictor variables by estimating how one variable impacts the others. For example, automobile price based on features like, gas mileage, safety rating, etc. Learn more and see an example of regression with automated machine learning (v1).
See examples of regression and automated machine learning for predictions in these Python notebooks: CPU Performance Prediction,
Time-series forecasting
Building forecasts is an integral part of any business, whether it's revenue, inventory, sales, or customer demand. You can use automated ML to combine techniques and approaches and get a recommended, high-quality time-series forecast. Learn more with this how-to: automated machine learning for time series forecasting (v1).
An automated time-series experiment is treated as a multivariate regression problem. Past time-series values are "pivoted" to become additional dimensions for the regressor together with other predictors. This approach, unlike classical time series methods, has an advantage of naturally incorporating multiple contextual variables and their relationship to one another during training. Automated ML learns a single, but often internally branched model for all items in the dataset and prediction horizons. More data is thus available to estimate model parameters and generalization to unseen series becomes possible.
Advanced forecasting configuration includes:
- holiday detection and featurization
- time-series and DNN learners (Auto-ARIMA, Prophet, ForecastTCN)
- many models support through grouping
- rolling-origin cross validation
- configurable lags
- rolling window aggregate features
See examples of regression and automated machine learning for predictions in these Python notebooks: Sales Forecasting, Demand Forecasting, and Forecasting GitHub's Daily Active Users.
Computer vision
Support for computer vision tasks allows you to easily generate models trained on image data for scenarios like image classification and object detection.
With this capability you can:
- Seamlessly integrate with the Azure Machine Learning data labeling capability
- Use labeled data for generating image models
- Optimize model performance by specifying the model algorithm and tuning the hyperparameters.
- Download or deploy the resulting model as a web service in Azure Machine Learning.
- Operationalize at scale, leveraging Azure Machine Learning MLOps and ML Pipelines (v1) capabilities.
Authoring AutoML models for vision tasks is supported via the Azure Machine Learning Python SDK. The resulting experimentation jobs, models, and outputs can be accessed from the Azure Machine Learning studio UI.
Learn how to set up AutoML training for computer vision models.

Automated ML for images supports the following computer vision tasks:
| Task | Description |
|---|---|
| Multi-class image classification | Tasks where an image is classified with only a single label from a set of classes - e.g. each image is classified as either an image of a 'cat' or a 'dog' or a 'duck' |
| Multi-label image classification | Tasks where an image could have one or more labels from a set of labels - e.g. an image could be labeled with both 'cat' and 'dog' |
| Object detection | Tasks to identify objects in an image and locate each object with a bounding box e.g. locate all dogs and cats in an image and draw a bounding box around each. |
| Instance segmentation | Tasks to identify objects in an image at the pixel level, drawing a polygon around each object in the image. |
Natural language processing: NLP
Support for natural language processing (NLP) tasks in automated ML allows you to easily generate models trained on text data for text classification and named entity recognition scenarios. Authoring automated ML trained NLP models is supported via the Azure Machine Learning Python SDK. The resulting experimentation jobs, models, and outputs can be accessed from the Azure Machine Learning studio UI.
The NLP capability supports:
- End-to-end deep neural network NLP training with the latest pre-trained BERT models
- Seamless integration with Azure Machine Learning data labeling
- Use labeled data for generating NLP models
- Multi-lingual support with 104 languages
- Distributed training with Horovod
Learn how to set up AutoML training for NLP models (v1).
How automated ML works
During training, Azure Machine Learning creates a number of pipelines in parallel that try different algorithms and parameters for you. The service iterates through ML algorithms paired with feature selections, where each iteration produces a model with a training score. The higher the score, the better the model is considered to "fit" your data. It will stop once it hits the exit criteria defined in the experiment.
Using Azure Machine Learning, you can design and run your automated ML training experiments with these steps:
Identify the ML problem to be solved: classification, forecasting, regression or computer vision.
Choose whether you want to use the Python SDK or the studio web experience: Learn about the parity between the Python SDK and studio web experience.
- For limited or no code experience, try the Azure Machine Learning studio web experience at https://ml.azure.com
- For Python developers, check out the Azure Machine Learning Python SDK (v1)
Specify the source and format of the labeled training data: Numpy arrays or Pandas dataframe
Configure the compute target for model training, such as your local computer, Azure Machine Learning Computes, remote VMs, or Azure Databricks with SDK v1.
Configure the automated machine learning parameters that determine how many iterations over different models, hyperparameter settings, advanced preprocessing/featurization, and what metrics to look at when determining the best model.
Submit the training job.
Review the results
The following diagram illustrates this process.
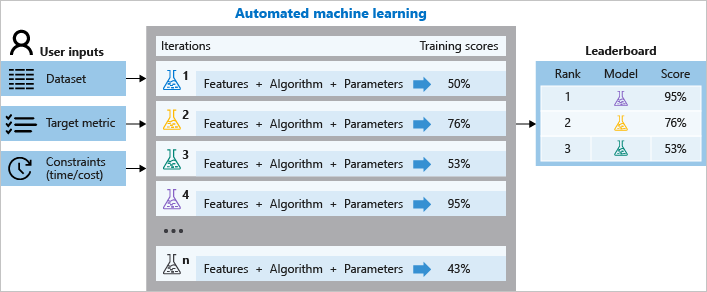
You can also inspect the logged job information, which contains metrics gathered during the job. The training job produces a Python serialized object (.pkl file) that contains the model and data preprocessing.
While model building is automated, you can also learn how important or relevant features are to the generated models.
Guidance on local vs. remote managed ML compute targets
The web interface for automated ML always uses a remote compute target. But when you use the Python SDK, you will choose either a local compute or a remote compute target for automated ML training.
- Local compute: Training occurs on your local laptop or VM compute.
- Remote compute: Training occurs on Machine Learning compute clusters.
Choose compute target
Consider these factors when choosing your compute target:
- Choose a local compute: If your scenario is about initial explorations or demos using small data and short trains (i.e. seconds or a couple of minutes per child job), training on your local computer might be a better choice. There is no setup time, the infrastructure resources (your PC or VM) are directly available.
- Choose a remote ML compute cluster: If you are training with larger datasets like in production training creating models which need longer trains, remote compute will provide much better end-to-end time performance because
AutoMLwill parallelize trains across the cluster's nodes. On a remote compute, the start-up time for the internal infrastructure will add around 1.5 minutes per child job, plus additional minutes for the cluster infrastructure if the VMs are not yet up and running.
Pros and cons
Consider these pros and cons when choosing to use local vs. remote.
| Pros (Advantages) | Cons (Handicaps) | |
|---|---|---|
| Local compute target | ||
| Remote ML compute clusters |
Feature availability
More features are available when you use the remote compute, as shown in the table below.
| Feature | Remote | Local |
|---|---|---|
| Data streaming (Large data support, up to 100 GB) | ✓ | |
| DNN-BERT-based text featurization and training | ✓ | |
| Out-of-the-box GPU support (training and inference) | ✓ | |
| Image Classification and Labeling support | ✓ | |
| Auto-ARIMA, Prophet and ForecastTCN models for forecasting | ✓ | |
| Multiple jobs/iterations in parallel | ✓ | |
| Create models with interpretability in AutoML studio web experience UI | ✓ | |
| Feature engineering customization in studio web experience UI | ✓ | |
| Azure Machine Learning hyperparameter tuning | ✓ | |
| Azure Machine Learning Pipeline workflow support | ✓ | |
| Continue a job | ✓ | |
| Forecasting | ✓ | ✓ |
| Create and run experiments in notebooks | ✓ | ✓ |
| Register and visualize experiment's info and metrics in UI | ✓ | ✓ |
| Data guardrails | ✓ | ✓ |
Training, validation and test data
With automated ML you provide the training data to train ML models, and you can specify what type of model validation to perform. Automated ML performs model validation as part of training. That is, automated ML uses validation data to tune model hyperparameters based on the applied algorithm to find the best combination that best fits the training data. However, the same validation data is used for each iteration of tuning, which introduces model evaluation bias since the model continues to improve and fit to the validation data.
To help confirm that such bias isn't applied to the final recommended model, automated ML supports the use of test data to evaluate the final model that automated ML recommends at the end of your experiment. When you provide test data as part of your AutoML experiment configuration, this recommended model is tested by default at the end of your experiment (preview).
Important
Testing your models with a test dataset to evaluate generated models is a preview feature. This capability is an experimental preview feature, and may change at any time.
Learn how to configure AutoML experiments to use test data (preview) with the SDK (v1) or with the Azure Machine Learning studio.
You can also test any existing automated ML model (preview) (v1)), including models from child jobs, by providing your own test data or by setting aside a portion of your training data.
Feature engineering
Feature engineering is the process of using domain knowledge of the data to create features that help ML algorithms learn better. In Azure Machine Learning, scaling and normalization techniques are applied to facilitate feature engineering. Collectively, these techniques and feature engineering are referred to as featurization.
For automated machine learning experiments, featurization is applied automatically, but can also be customized based on your data. Learn more about what featurization is included (v1) and how AutoML helps prevent over-fitting and imbalanced data in your models.
Note
Automated machine learning featurization steps (feature normalization, handling missing data, converting text to numeric, etc.) become part of the underlying model. When using the model for predictions, the same featurization steps applied during training are applied to your input data automatically.
Customize featurization
Additional feature engineering techniques such as, encoding and transforms are also available.
Enable this setting with:
Azure Machine Learning studio: Enable Automatic featurization in the View additional configuration section with these (v1) steps.
Python SDK: Specify
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'in your AutoMLConfig object. Learn more about enabling featurization (v1).
Ensemble models
Automated machine learning supports ensemble models, which are enabled by default. Ensemble learning improves machine learning results and predictive performance by combining multiple models as opposed to using single models. The ensemble iterations appear as the final iterations of your job. Automated machine learning uses both voting and stacking ensemble methods for combining models:
- Voting: predicts based on the weighted average of predicted class probabilities (for classification tasks) or predicted regression targets (for regression tasks).
- Stacking: stacking combines heterogenous models and trains a meta-model based on the output from the individual models. The current default meta-models are LogisticRegression for classification tasks and ElasticNet for regression/forecasting tasks.
The Caruana ensemble selection algorithm with sorted ensemble initialization is used to decide which models to use within the ensemble. At a high level, this algorithm initializes the ensemble with up to five models with the best individual scores, and verifies that these models are within 5% threshold of the best score to avoid a poor initial ensemble. Then for each ensemble iteration, a new model is added to the existing ensemble and the resulting score is calculated. If a new model improved the existing ensemble score, the ensemble is updated to include the new model.
See the how-to (v1) for changing default ensemble settings in automated machine learning.
AutoML & ONNX
With Azure Machine Learning, you can use automated ML to build a Python model and have it converted to the ONNX format. Once the models are in the ONNX format, they can be run on a variety of platforms and devices. Learn more about accelerating ML models with ONNX.
See how to convert to ONNX format in this Jupyter notebook example. Learn which algorithms are supported in ONNX (v1).
The ONNX runtime also supports C#, so you can use the model built automatically in your C# apps without any need for recoding or any of the network latencies that REST endpoints introduce. Learn more about using an AutoML ONNX model in a .NET application with ML.NET and inferencing ONNX models with the ONNX runtime C# API.
Next steps
There are multiple resources to get you up and running with AutoML.
Tutorials/ how-tos
Tutorials are end-to-end introductory examples of AutoML scenarios.
For a code first experience, follow the Tutorial: Train a regression model with AutoML and Python (v1).
For a low or no-code experience, see the Tutorial: Train a classification model with no-code AutoML in Azure Machine Learning studio.
For using AutoML to train computer vision models, see the Tutorial: Train an object detection model with AutoML and Python (v1).
How-to articles provide additional detail into what functionality automated ML offers. For example,
Configure the settings for automatic training experiments
Learn how to train forecasting models with time series data (v1).
Learn how to train computer vision models with Python (v1).
Learn how to view the generated code from your automated ML models.
Jupyter notebook samples
Review detailed code examples and use cases in the GitHub notebook repository for automated machine learning samples.
Python SDK reference
Deepen your expertise of SDK design patterns and class specifications with the AutoML class reference documentation.
Note
Automated machine learning capabilities are also available in other Microsoft solutions such as, ML.NET, HDInsight, Power BI and SQL Server
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for