Projektowanie w celu przetrwania niepowodzeń (tworzenie aplikacji Real-World w chmurze za pomocą platformy Azure)
Autor: Rick Anderson, Tom Dykstra
Pobierz poprawkę projektu lub pobierz książkę elektroniczną
Książka elektroniczna Building Real World Cloud Apps with Azure (Tworzenie rzeczywistych aplikacji w chmurze za pomocą usługi Azure ) opiera się na prezentacji opracowanej przez Scotta Guthrie'ego. Wyjaśniono w nim 13 wzorców i praktyk, które mogą pomóc w pomyślnym tworzeniu aplikacji internetowych dla chmury. Aby uzyskać informacje o książce elektronicznej, zobacz pierwszy rozdział.
Jedną z rzeczy, o których musisz myśleć podczas tworzenia dowolnej aplikacji, ale zwłaszcza tej, która będzie działać w chmurze, w której wiele osób będzie jej używać, jest sposób projektowania aplikacji, aby mogła bezpiecznie obsługiwać błędy i nadal dostarczać wartość jak najwięcej. Biorąc pod uwagę wystarczająco dużo czasu, wszystko pójdzie źle w dowolnym środowisku lub dowolnym systemie oprogramowania. Sposób obsługi tych sytuacji przez aplikację określa, jak zdenerwowani klienci będą otrzymywać i ile czasu trzeba poświęcić na analizowanie i rozwiązywanie problemów.
Typy błędów
Istnieją dwie podstawowe kategorie błędów, które chcesz obsługiwać inaczej:
- Przejściowe błędy samonaprawiania, takie jak sporadyczne problemy z łącznością sieciową.
- Trwałe błędy wymagające interwencji.
W przypadku przejściowych błędów można zaimplementować zasady ponawiania prób, aby zapewnić, że większość czasu aplikacja szybko i automatycznie odzyskuje. Klienci mogą zauważyć nieco dłuższy czas odpowiedzi, ale w przeciwnym razie nie będą one miały wpływu. Pokażemy kilka sposobów obsługi tych błędów w rozdziale Obsługa błędów przejściowych.
W przypadku trwałych awarii można zaimplementować funkcje monitorowania i rejestrowania, które powiadamiają Cię natychmiast po wystąpieniu problemów i ułatwiają analizę głównej przyczyny. Pokażemy kilka sposobów, aby pomóc Ci pozostać na bieżąco z tego rodzaju błędami w rozdziale Monitorowanie i telemetria.
Zakres awarii
Należy również zastanowić się nad zakresem awarii — niezależnie od tego, czy dotyczy to pojedynczej maszyny, całej usługi, takiej jak SQL Database czy Storage, czy całego regionu.

Błędy maszyny
Na platformie Azure serwer, który zakończył się niepowodzeniem, jest automatycznie zastępowany przez nową, a dobrze zaprojektowana aplikacja w chmurze automatycznie i szybko odzyskuje dane po awarii tego rodzaju. Wcześniej podkreśliliśmy korzyści ze skalowalności bezstanowej warstwy internetowej, a łatwość odzyskiwania z serwera, który zakończył się niepowodzeniem, jest kolejną zaletą bezstanowości. Łatwość odzyskiwania jest również jedną z zalet funkcji typu platforma jako usługa (PaaS), takich jak SQL Database i Azure App Service Web Apps. Awarie sprzętu są rzadkie, ale gdy wystąpią, usługi te obsługują je automatycznie; Nie trzeba nawet pisać kodu do obsługi awarii maszyny podczas korzystania z jednej z tych usług.
Błędy usługi
Aplikacje w chmurze zazwyczaj korzystają z wielu usług. Na przykład aplikacja Fix It używa usługi SQL Database, usługi Storage i aplikacji internetowej jest wdrażana w Azure App Service. Co zrobi Twoja aplikacja, jeśli jedna z usług, od których zależy, zakończy się niepowodzeniem? W przypadku niektórych awarii usługi przyjazny komunikat "niestety spróbuj ponownie później" może być najlepszym rozwiązaniem. Ale w wielu scenariuszach można zrobić lepiej. Na przykład, gdy magazyn danych zaplecza nie działa, możesz zaakceptować dane wejściowe użytkownika, wyświetlić "żądanie zostało odebrane" i przechowywać dane wejściowe tymczasowo; następnie, gdy potrzebna usługa działa ponownie, możesz pobrać dane wejściowe i przetworzyć je.
Rozdział Wzorzec pracy skoncentrowany na kolejce przedstawia jeden ze sposobów obsługi tego scenariusza. Aplikacja Fix It przechowuje zadania w SQL Database, ale nie musi pracować, gdy SQL Database nie działa. W tym rozdziale zobaczymy, jak przechowywać dane wejściowe użytkownika dla zadania w kolejce i użyć procesu roboczego, aby odczytać kolejkę i zaktualizować zadanie. Jeśli program SQL nie działa, nie ma to wpływu na możliwość tworzenia zadań naprawy. proces roboczy może czekać i przetwarzać nowe zadania po udostępnieniu SQL Database.
Błędy regionów
Całe regiony mogą zakończyć się niepowodzeniem. Klęska żywiołowa może zniszczyć centrum danych, może zostać spłaszczona przez meteor, linia magistrali do centrum danych może zostać obcięta przez rolnika zakopując krówę z podkowy itp. Jeśli aplikacja jest hostowana w dotkniętym centrum danych, co robisz? Istnieje możliwość skonfigurowania aplikacji na platformie Azure w celu jednoczesnego uruchamiania w wielu regionach, aby w przypadku awarii w jednym regionie nadal działać w innym regionie. Takie awarie są niezwykle rzadkie, a większość aplikacji nie przechodzi przez obręcze niezbędne do zapewnienia nieprzerwanej usługi przez awarie tego rodzaju. Zobacz sekcję Zasoby na końcu rozdziału, aby uzyskać informacje o sposobie udostępniania aplikacji nawet za pośrednictwem awarii regionu.
Celem platformy Azure jest ułatwienie obsługi wszystkich tego rodzaju awarii i zobaczysz kilka przykładów tego, jak to robimy w poniższych rozdziałach.
Umowy SLA
Osoby często słyszy się o umowach dotyczących poziomu usług (SLA) w środowisku chmury. Zasadniczo są to obietnice, które firmy robią o tym, jak niezawodna jest ich usługa. Umowa SLA na 99,9% oznacza, że usługa będzie działać poprawnie 99,9% czasu. Jest to dość typowa wartość umowy SLA i brzmi jak bardzo duża liczba, ale możesz nie zdać sobie sprawy, ile czasu pracy w dół wynosi 1%. Oto tabela przedstawiająca, ile przestojów wynosi procent różnych umów SLA w ciągu roku, miesiąca i tygodnia.
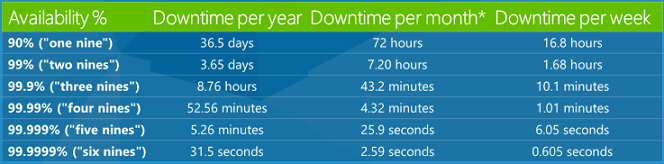
Umowa SLA na 99,9% oznacza, że twoja usługa może spaść o 8,76 godzin rocznie lub 43,2 minuty miesięcznie. To więcej czasu w dół niż większość ludzi zdaje sobie sprawę. Dlatego jako deweloper chcesz mieć świadomość, że pewna ilość czasu pracy jest możliwa i obsłużyć go w sposób bezproblemowy. W pewnym momencie ktoś będzie korzystać z twojej aplikacji, a usługa będzie wyłączona i chcesz zminimalizować negatywny wpływ tego na klienta.
Jedną z rzeczy, którą należy wiedzieć o umowie SLA, jest to, co oznacza przedział czasu: czy zegar jest resetowany co tydzień, co miesiąc, czy co roku? Na platformie Azure co miesiąc resetujemy zegar, który jest lepszy niż roczna umowa SLA, ponieważ roczna umowa SLA może ukryć złe miesiące, resetując je z serii dobrych miesięcy.
Oczywiście zawsze aspirujemy do zrobienia lepiej niż umowa SLA; zwykle będziesz w dół znacznie mniej niż to. Obietnica polega na tym, że jeśli kiedykolwiek jesteśmy w dół przez dłuższy niż maksymalny czas pracy, możesz poprosić o pieniądze z powrotem. Kwota pieniędzy, które otrzymasz, prawdopodobnie nie w pełni zrekompensowałaby ci wpływu biznesowego nadmiaru czasu pracy, ale ten aspekt umowy SLA działa jako polityka wymuszania i informuje o tym, że traktujemy to bardzo poważnie.
Złożone umowy SLA
Ważne jest, aby zastanowić się, kiedy patrzysz na umowy SLA, jest wpływ korzystania z wielu usług w aplikacji, przy czym każda usługa ma oddzielną umowę SLA. Na przykład aplikacja Fix It używa Azure App Service Web Apps, usługi Azure Storage i SQL Database. Poniżej przedstawiono numery umów SLA od daty pisania tej książki elektronicznej w grudniu 2013 r.:
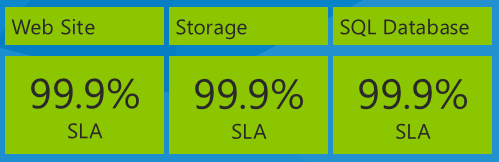
Jaki jest maksymalny czas pracy aplikacji na podstawie tych umów SLA usługi? Możesz pomyśleć, że twój czas pracy będzie równy najgorszej wartości procentowej umowy SLA lub 99,9% w tym przypadku. To prawda, jeśli wszystkie trzy usługi zawsze nie powiodły się w tym samym czasie, ale to niekoniecznie jest to, co rzeczywiście się dzieje. Każda usługa może działać niezależnie w różnych momentach, dlatego musisz obliczyć złożoną umowę SLA przez pomnożenie poszczególnych numerów umów SLA.
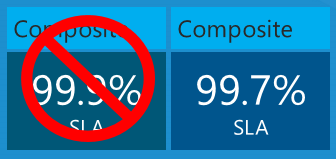
Więc twoja aplikacja może nie być tylko 43,2 minut miesięcznie, ale 3 razy ta kwota, 108 minut miesięcznie — i nadal mieści się w granicach umowy SLA platformy Azure.
Ten problem nie jest unikatowy dla platformy Azure. W rzeczywistości zapewniamy najlepsze umowy SLA dotyczące chmury dowolnej dostępnej usługi w chmurze i będziesz mieć podobne problemy, aby rozwiązać problemy, jeśli korzystasz z usług w chmurze dowolnego dostawcy. Najważniejsze jest znaczenie myślenia o tym, jak można zaprojektować aplikację w celu bezproblemowego obsługi nieuniknionych awarii usług, ponieważ mogą one zdarzyć się często wystarczająco często, aby wpłynąć na klientów lub użytkowników.
Umowy SLA w chmurze w porównaniu z środowiskiem czasu pracy w przedsiębiorstwie
Osoby czasami mówi: "W mojej aplikacji dla przedsiębiorstw nigdy nie mam tych problemów". Jeśli pytasz, ile czasu w dół miesiąca rzeczywiście mają, zwykle mówią: "Cóż, zdarza się to od czasu do czasu." A jeśli pytasz, jak często, przyznają, że "Czasami musimy utworzyć kopię zapasową lub zainstalować nowy serwer lub zaktualizować oprogramowanie". Oczywiście, to liczy się jako czas pracy. Większość aplikacji dla przedsiębiorstw, chyba że są one szczególnie krytyczne, są rzeczywiście w dół przez więcej niż czas dozwolony przez nasze umowy SLA usług. Ale kiedy jest to serwer i infrastruktura, a ty odpowiadasz za nią i kontrolujesz go, zwykle czujesz się mniej niepokój o czasy pracy. W środowisku chmury zależysz od kogoś innego i nie wiesz, co się dzieje, więc możesz mieć tendencję do bardziej martwić się o to.
Gdy przedsiębiorstwo osiągnie większy procent czasu pracy niż uzyskujesz od umowy SLA w chmurze, robią to, wydając o wiele więcej pieniędzy na sprzęt. Usługa w chmurze może to zrobić, ale musiałaby pobierać znacznie więcej opłat za jej usługi. Zamiast tego korzystasz z ekonomicznej usługi i projektujesz oprogramowanie, aby nieuniknione awarie powodowały minimalne zakłócenia dla klientów. Twoim zadaniem jako projektant aplikacji w chmurze nie jest tak wiele, aby uniknąć awarii, a ty to robisz, koncentrując się na oprogramowaniu, a nie na sprzęcie. Podczas gdy aplikacje dla przedsiębiorstw starają się zmaksymalizować średni czas między awariami, aplikacje w chmurze starają się zminimalizować średni czas odzyskiwania.
Nie wszystkie usługi w chmurze mają umowy SLA
Pamiętaj również, że nie każda usługa w chmurze ma nawet umowę SLA. Jeśli aplikacja jest zależna od usługi bez gwarancji czasu pracy, możesz być znacznie dłużej niż można sobie wyobrazić. Jeśli na przykład włączysz logowanie się do witryny przy użyciu dostawcy społecznościowego, takiego jak Facebook lub Twitter, sprawdź dostawcę usług, aby dowiedzieć się, czy istnieje umowa SLA, i możesz się dowiedzieć, że nie istnieje. Jeśli jednak usługa uwierzytelniania ulegnie awarii lub nie może obsłużyć liczby zgłoszonych żądań, klienci są zablokowani z aplikacji. Możesz być wyłączony przez kilka dni lub dłużej. Twórcy jednej nowej aplikacji spodziewali się setek milionów pobrań i wzięli zależność od uwierzytelniania na Facebooku — ale nie rozmawiali z Facebookiem przed rozpoczęciem transmisji na żywo i odkryli zbyt późno, że nie było umowy SLA dla tej usługi.
Nie wszystkie przestoje są liczone w stosunku do umów SLA
Niektóre usługi w chmurze mogą celowo odrzucać usługę, jeśli aplikacja używa ich nadmiernie. Jest to nazywane ograniczaniem przepustowości. Jeśli usługa ma umowę SLA, powinna określić warunki, w których może być ograniczona, a projekt aplikacji powinien unikać tych warunków i odpowiednio reagować na ograniczanie przepustowości, jeśli tak się stanie. Jeśli na przykład żądania do usługi kończą się niepowodzeniem po przekroczeniu określonej liczby na sekundę, należy upewnić się, że automatyczne ponawianie prób nie występuje tak szybko, że powodują one kontynuowanie ograniczania przepustowości. Będziemy mieli więcej do powiedzenia na temat ograniczania przepustowości w rozdziale Obsługa błędów przejściowych.
Podsumowanie
Ten rozdział starał się pomóc ci zrozumieć, dlaczego prawdziwa aplikacja w chmurze musi być zaprojektowana tak, aby przetrwać błędy w sposób bezproblemowy. Począwszy od następnego rozdziału, pozostałe wzorce z tej serii są bardziej szczegółowe na temat niektórych strategii, których można użyć do tego:
- Masz dobre monitorowanie i telemetrię, aby szybko dowiedzieć się o awariach wymagających interwencji i masz wystarczające informacje, aby je rozwiązać.
- Obsługa błędów przejściowych przez zaimplementowanie inteligentnej logiki ponawiania prób, dzięki czemu aplikacja jest odzyskiwane automatycznie, gdy może i wraca do logiki wyłącznika , gdy nie może.
- Użyj rozproszonego buforowania , aby zminimalizować przepływność, opóźnienie i problemy z połączeniem z dostępem do bazy danych.
- Zaimplementuj luźne sprzężenie za pośrednictwem wzorca pracy skoncentrowanego na kolejce, aby fronton aplikacji mógł nadal działać po awarii zaplecza.
Zasoby
Aby uzyskać więcej informacji, zobacz kolejne rozdziały w tej książce elektronicznej i poniższych zasobach.
Dokumentacja:
- Niepowodzenie: wskazówki dotyczące odpornych architektur chmury. Oficjalny dokument Marc Mercuri, Ulrich Homann i Andrew Townhill. Wersja strony internetowej serii wideo FailSafe.
- Najlepsze rozwiązania dotyczące projektowania usług Large-Scale na platformie Azure Cloud Services. Oficjalny dokument Marka Simmsa i Michaela Thomassy'ego.
- Wskazówki techniczne dotyczące ciągłości działania platformy Azure. Biała księga Patricka Wickline'a i Jasona Rotha.
- Odzyskiwanie po awarii i wysoka dostępność aplikacji platformy Azure. Biały dokument Michael McKeown, Hanu Kommalapati i Jason Roth.
- Wzorce i praktyki firmy Microsoft — wskazówki dotyczące platformy Azure. Zobacz Wskazówki dotyczące wdrażania w wielu centrach danych, wzorzec wyłącznika.
- Pomoc techniczna platformy Azure — umowy dotyczące poziomu usług.
- Ciągłość działalności biznesowej w bazie danych Azure SQL. Dokumentacja dotycząca SQL Database funkcji wysokiej dostępności i odzyskiwania po awarii.
- Wysoka dostępność i odzyskiwanie po awarii dla SQL Server na platformie Azure Virtual Machines.
Filmy wideo:
- FailSafe: tworzenie skalowalnych, odpornych Cloud Services. Dziewięć części serii Ulrich Homann, Marc Mercuri i Mark Simms. Przedstawia pojęcia wysokiego poziomu i zasady architektury w bardzo dostępny i interesujący sposób, z historiami pochodzącymi z zespołu doradczego klienta firmy Microsoft (CAT) z rzeczywistymi klientami. Odcinek 1 i 8 szczegółowo zapoznaj się z przyczynami projektowania aplikacji w chmurze w celu przetrwania awarii. Zobacz również kontynuację dyskusji na temat ograniczania przepustowości w odcinku 2 począwszy od 49:57, dyskusja o punktach awarii i trybach awarii w odcinku 2 począwszy od 56:05, a dyskusja wyłączników w odcinku 3 począwszy od 40:55.
- Tworzenie dużych: wnioski zdobyte od klientów platformy Azure — część II. Mark Simms mówi o projektowaniu pod kątem awarii i instrumentacji wszystkiego. Podobnie jak w serii Failsafe, ale zawiera więcej szczegółów instrukcji.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla