Ta architektura referencyjna przedstawia architekturę bezserwerową opartą na zdarzeniach, która pozyskuje strumień danych, przetwarza dane i zapisuje wyniki w bazie danych zaplecza.
Architektura
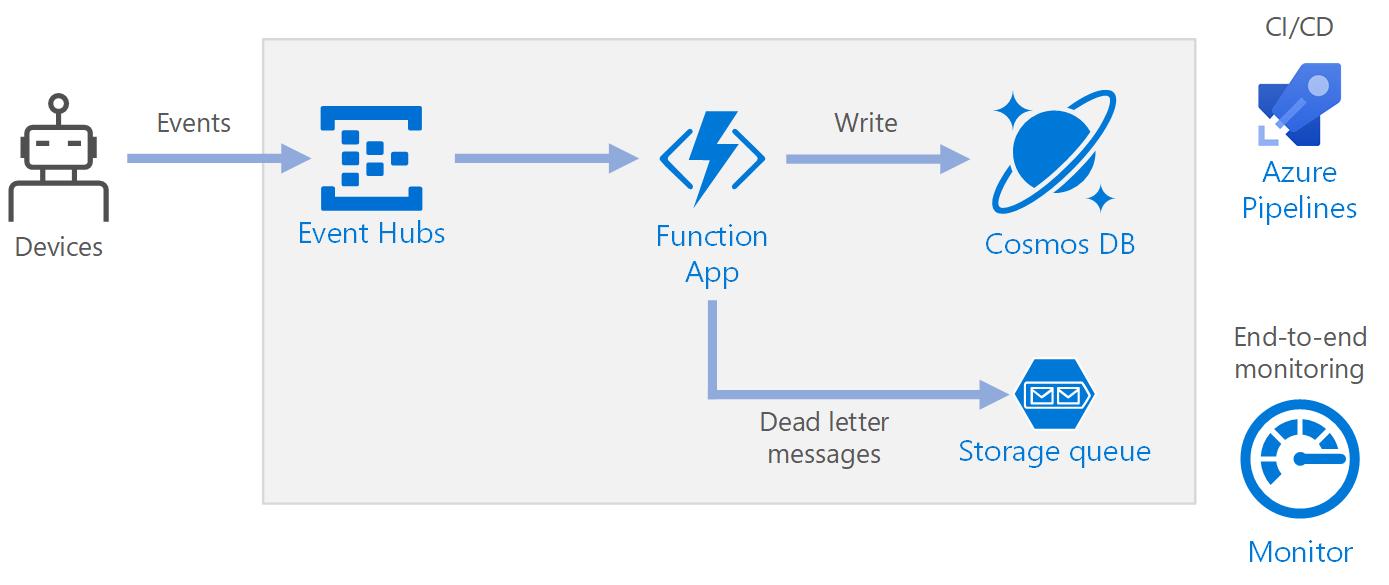
Przepływ pracy
- Zdarzenia docierają do usługi Azure Event Hubs.
- Aplikacja funkcji jest wyzwalana w celu obsługi zdarzenia.
- Zdarzenie jest przechowywane w bazie danych usługi Azure Cosmos DB.
- Jeśli aplikacja funkcji nie będzie pomyślnie przechowywać zdarzenia, zdarzenie zostanie zapisane w kolejce usługi Storage do przetworzenia później.
Składniki
Usługa Event Hubs pozyskiwa strumień danych. Usługa Event Hubs jest przeznaczona dla scenariuszy przesyłania strumieniowego danych o wysokiej przepływności.
Uwaga
W przypadku scenariuszy Internetu rzeczy (IoT) zalecamy usługę Azure IoT Hub. Usługa IoT Hub ma wbudowany punkt końcowy zgodny z interfejsem API usługi Azure Event Hubs, dzięki czemu można używać żadnej usługi w tej architekturze bez istotnych zmian w przetwarzaniu zaplecza. Aby uzyskać więcej informacji, zobacz Połączenie ing IoT Devices to Azure: IoT Hub and Event Hubs (Połączenie ing IoT Devices to Azure: IoT Hubs and Event Hubs).
Aplikacja funkcji. Usługa Azure Functions to opcja obliczeniowa bezserwerowa. Używa ona modelu sterowanego zdarzeniami, w którym element kodu ( funkcja) jest wywoływany przez wyzwalacz. W tej architekturze, gdy zdarzenia docierają do usługi Event Hubs, wyzwalają funkcję, która przetwarza zdarzenia i zapisuje wyniki w magazynie.
Aplikacje funkcji są odpowiednie do przetwarzania poszczególnych rekordów z usługi Event Hubs. W przypadku bardziej złożonych scenariuszy przetwarzania strumieniowego rozważ użycie platformy Apache Spark przy użyciu usługi Azure Databricks lub Azure Stream Analytics.
Azure Cosmos DB. Azure Cosmos DB to wielomodelowa usługa bazy danych, która jest dostępna w trybie bezserwerowym opartym na użyciu. W tym scenariuszu funkcja przetwarzania zdarzeń przechowuje rekordy JSON przy użyciu usługi Azure Cosmos DB for NoSQL.
Magazyn kolejek. Usługa Queue Storage jest używana w przypadku komunikatów utraconych. Jeśli podczas przetwarzania zdarzenia wystąpi błąd, funkcja przechowuje dane zdarzenia w kolejce utraconych komunikatów w celu późniejszego przetworzenia. Aby uzyskać więcej informacji, zobacz sekcję Odporność w dalszej części tego artykułu.
Azure Monitor. Monitor zbiera metryki wydajności dotyczące usług platformy Azure wdrożonych w rozwiązaniu. Wizualizując je na pulpicie nawigacyjnym, możesz uzyskać wgląd w kondycję rozwiązania.
Azure Pipelines. Potoki to usługa ciągłej integracji i ciągłego dostarczania (CD), która kompiluje, testuje i wdraża aplikację.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Dostępność
Wdrożenie pokazane tutaj znajduje się w jednym regionie świadczenia usługi Azure. Aby uzyskać bardziej odporne podejście do odzyskiwania po awarii, skorzystaj z funkcji dystrybucji geograficznej w różnych usługach:
- Event Hubs. Utwórz dwie przestrzenie nazw usługi Event Hubs, przestrzeń nazw podstawowej (aktywnej) i pomocniczą (pasywną) przestrzeń nazw. Komunikaty są automatycznie kierowane do aktywnej przestrzeni nazw, chyba że zostanie przełączona w tryb failover do pomocniczej przestrzeni nazw. Aby uzyskać więcej informacji, zobacz Odzyskiwanie geograficzne po awarii w usłudze Azure Event Hubs.
- Aplikacja funkcji. Wdróż drugą aplikację funkcji, która oczekuje na odczyt z pomocniczej przestrzeni nazw usługi Event Hubs. Ta funkcja zapisuje dane na pomocniczym koncie magazynu dla kolejki utraconych komunikatów.
- Azure Cosmos DB. Usługa Azure Cosmos DB obsługuje wiele regionów zapisu, co umożliwia zapisywanie w dowolnym regionie dodanym do konta usługi Azure Cosmos DB. Jeśli nie włączysz wielu zapisów, nadal możesz przejść w tryb failover w regionie podstawowego zapisu. Zestawy SDK klienta usługi Azure Cosmos DB i powiązania funkcji platformy Azure automatycznie obsługują tryb failover, więc nie trzeba aktualizować żadnych ustawień konfiguracji aplikacji.
- Azure Storage. Użyj magazynu RA-GRS dla kolejki utraconych komunikatów. Spowoduje to utworzenie repliki tylko do odczytu w innym regionie. Jeśli region podstawowy stanie się niedostępny, możesz odczytać elementy znajdujące się obecnie w kolejce. Ponadto aprowizuj kolejne konto magazynu w regionie pomocniczym, do którego funkcja może zapisywać dane po przejściu w tryb failover.
Skalowalność
Event Hubs
Pojemność przepływności usługi Event Hubs jest mierzona w jednostkach przepływności. Możesz automatycznie skalować centrum zdarzeń, włączając automatyczne rozszerzanie, które automatycznie skaluje jednostki przepływności na podstawie ruchu, do skonfigurowanej maksymalnej wartości.
Wyzwalacz usługi Event Hubs w aplikacji funkcji jest skalowany zgodnie z liczbą partycji w centrum zdarzeń. Każda partycja jest przypisana do jednego wystąpienia funkcji naraz. Aby zmaksymalizować przepływność, odbieraj zdarzenia w partii, a nie jeden naraz.
Azure Cosmos DB
Usługa Azure Cosmos DB jest dostępna w dwóch różnych trybach pojemności:
- Bezserwerowe, w przypadku obciążeń ze sporadycznymi lub nieprzewidywalnymi ruchem oraz niskim średnim i szczytowym współczynnikiem ruchu.
- Aprowizowana przepływność dla obciążeń z trwałym ruchem wymagającym przewidywalnej wydajności.
Aby upewnić się, że obciążenie jest skalowalne, ważne jest, aby wybrać odpowiedni klucz partycji podczas tworzenia kontenerów usługi Azure Cosmos DB. Poniżej przedstawiono niektóre cechy dobrego klucza partycji:
- Przestrzeń wartości klucza jest duża.
- Będzie istnieć równomierny rozkład odczytów/zapisów na wartość klucza, unikając kluczy dostępu.
- Maksymalna ilość danych przechowywanych dla dowolnej wartości pojedynczego klucza nie przekroczy maksymalnego rozmiaru partycji fizycznej (20 GB).
- Klucz partycji dla dokumentu nie ulegnie zmianie. Nie można zaktualizować klucza partycji w istniejącym dokumencie.
W scenariuszu dla tej architektury referencyjnej funkcja przechowuje dokładnie jeden dokument na urządzenie wysyłające dane. Funkcja stale aktualizuje dokumenty o najnowszy stan urządzenia przy użyciu operacji upsert. Identyfikator urządzenia jest dobrym kluczem partycji dla tego scenariusza, ponieważ zapisy będą równomiernie dystrybuowane między kluczami, a rozmiar każdej partycji będzie ściśle ograniczony, ponieważ istnieje jeden dokument dla każdej wartości klucza. Aby uzyskać więcej informacji na temat kluczy partycji, zobacz Partition and scale in Azure Cosmos DB (Partycjonowanie i skalowanie w usłudze Azure Cosmos DB).
Odporność
W przypadku korzystania z wyzwalacza usługi Event Hubs z usługą Functions przechwyć wyjątki w pętli przetwarzania. Jeśli wystąpi nieobsługiwany wyjątek, środowisko uruchomieniowe usługi Functions nie ponawia próby komunikatów. Jeśli nie można przetworzyć wiadomości, umieść wiadomość w kolejce utraconych komunikatów. Użyj procesu poza pasmem, aby zbadać komunikaty i określić akcję naprawczą.
Poniższy kod pokazuje, jak funkcja pozyskiwania przechwytuje wyjątki i umieszcza nieprzetworzone komunikaty do kolejki utraconych komunikatów.
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
Pokazany kod rejestruje również wyjątki dotyczące Szczegółowe informacje aplikacji. Klucz partycji i numer sekwencji umożliwiają skorelowanie komunikatów utraconych z wyjątkami w dziennikach.
Komunikaty w kolejce utraconych komunikatów powinny mieć wystarczającą ilość informacji, aby można było zrozumieć kontekst błędu. W tym przykładzie DeadLetterMessage klasa zawiera komunikat o wyjątku, oryginalne dane treści zdarzenia i zdeserializowany komunikat zdarzenia (jeśli jest dostępny).
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
Monitorowanie centrum zdarzeń za pomocą usługi Azure Monitor . Jeśli widzisz, że istnieją dane wejściowe, ale nie ma danych wyjściowych, oznacza to, że komunikaty nie są przetwarzane. W takim przypadku przejdź do usługi Log Analytics i poszukaj wyjątków lub innych błędów.
DevOps
Jeśli to możliwe, użyj infrastruktury jako kodu (IaC). Usługa IaC zarządza infrastrukturą, aplikacją i zasobami magazynu przy użyciu podejścia deklaratywnego, takiego jak usługa Azure Resource Manager. Pomoże to zautomatyzować wdrażanie przy użyciu metodyki DevOps jako rozwiązania ciągłej integracji i ciągłego dostarczania (CI/CD). Szablony powinny być wersjonowane i dołączane jako część potoku wydania.
Podczas tworzenia szablonów grupuj zasoby jako sposób organizowania i izolowania ich na obciążenie. Typowym sposobem myślenia o obciążeniu jest pojedyncza aplikacja bezserwerowa lub sieć wirtualna. Celem izolacji obciążenia jest skojarzenie zasobów z zespołem, aby zespół DevOps mógł niezależnie zarządzać wszystkimi aspektami tych zasobów i wykonywać ciągłą integrację/ciągłe wdrażanie.
Podczas wdrażania usług należy je monitorować. Rozważ użycie Szczegółowe informacje aplikacji, aby umożliwić deweloperom monitorowanie wydajności i wykrywanie problemów.
Aby uzyskać więcej informacji, zobacz listę kontrolną metodyki DevOps.
Odzyskiwanie po awarii
Wdrożenie pokazane tutaj znajduje się w jednym regionie świadczenia usługi Azure. Aby uzyskać bardziej odporne podejście do odzyskiwania po awarii, skorzystaj z funkcji dystrybucji geograficznej w różnych usługach:
Event Hubs. Utwórz dwie przestrzenie nazw usługi Event Hubs, przestrzeń nazw podstawowej (aktywnej) i pomocniczą (pasywną) przestrzeń nazw. Komunikaty są automatycznie kierowane do aktywnej przestrzeni nazw, chyba że zostanie przełączona w tryb failover do pomocniczej przestrzeni nazw. Aby uzyskać więcej informacji, zobacz Odzyskiwanie geograficzne po awarii w usłudze Azure Event Hubs.
Aplikacja funkcji. Wdróż drugą aplikację funkcji, która oczekuje na odczyt z pomocniczej przestrzeni nazw usługi Event Hubs. Ta funkcja zapisuje dane na pomocniczym koncie magazynu dla kolejki utraconych komunikatów.
Azure Cosmos DB. Usługa Azure Cosmos DB obsługuje wiele regionów zapisu, co umożliwia zapisywanie w dowolnym regionie dodanym do konta usługi Azure Cosmos DB. Jeśli nie włączysz wielu zapisów, nadal możesz przejść w tryb failover w regionie podstawowego zapisu. Zestawy SDK klienta usługi Azure Cosmos DB i powiązania funkcji platformy Azure automatycznie obsługują tryb failover, więc nie trzeba aktualizować żadnych ustawień konfiguracji aplikacji.
Azure Storage. Użyj magazynu RA-GRS dla kolejki utraconych komunikatów. Spowoduje to utworzenie repliki tylko do odczytu w innym regionie. Jeśli region podstawowy stanie się niedostępny, możesz odczytać elementy znajdujące się obecnie w kolejce. Ponadto aprowizuj kolejne konto magazynu w regionie pomocniczym, do którego funkcja może zapisywać dane po przejściu w tryb failover.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Użyj kalkulatora cen platformy Azure, aby oszacować koszty. Poniżej przedstawiono kilka innych zagadnień dotyczących usług Azure Functions i Azure Cosmos DB.
Azure Functions
Usługa Azure Functions obsługuje dwa modele hostingu:
- Plan zużycia. Moc obliczeniowa jest przydzielana automatycznie po uruchomieniu kodu.
- Plan usługi App Service. Zestaw maszyn wirtualnych jest przydzielany dla kodu. Plan usługi App Service definiuje liczbę maszyn wirtualnych i rozmiar maszyny wirtualnej.
W tej architekturze każde zdarzenie docierające do usługi Event Hubs wyzwala funkcję przetwarzającą to zdarzenie. Z perspektywy kosztów zaleca się użycie planu zużycia, ponieważ płacisz tylko za używane zasoby obliczeniowe.
Azure Cosmos DB
W przypadku usługi Cosmos DB płacisz za operacje wykonywane na bazie danych i za magazyn zajmowany przez dane.
- Operacje bazy danych. Sposób naliczania opłat za operacje bazy danych zależy od typu używanego konta usługi Azure Cosmos DB.
- W trybie bezserwerowym nie trzeba aprowizować żadnej przepływności podczas tworzenia zasobów na koncie usługi Azure Cosmos DB. Na koniec okresu rozliczeniowego opłaty są naliczane za liczbę jednostek żądań używanych przez operacje bazy danych.
- W trybie aprowizowanej przepływności należy określić przepływność potrzebną w jednostkach żądań na sekundę (RU/s) i pobierać opłaty godzinowe za maksymalną aprowizowaną przepływność dla danej godziny. Uwaga: ponieważ model aprowizowanej przepływności dedykuje zasoby kontenerowi lub bazie danych, opłaty będą naliczane za aprowizowaną przepływność, nawet jeśli nie uruchamiasz żadnych obciążeń.
- Magazyn. Opłaty są naliczane w wysokości ryczałtowej za łączną ilość miejsca do magazynowania (w GB) zużywaną przez dane i indeksy przez daną godzinę.
W tej architekturze referencyjnej funkcja przechowuje dokładnie jeden dokument na urządzenie wysyłające dane. Funkcja stale aktualizuje dokumenty o najnowszym stanie urządzenia przy użyciu operacji upsert, która jest opłacalna pod względem zużytego magazynu. Aby uzyskać więcej informacji, zobacz Model cen usługi Azure Cosmos DB.
Skorzystaj z kalkulatora pojemności usługi Azure Cosmos DB, aby uzyskać szybkie oszacowanie kosztów obciążenia.
Wdrażanie tego scenariusza
 Implementacja referencyjna dla tej architektury jest dostępna w usłudze GitHub.
Implementacja referencyjna dla tej architektury jest dostępna w usłudze GitHub.
Następne kroki
- Wprowadzenie do usługi Azure Functions
- Azure Cosmos DB — Zapraszamy!
- Co to jest usługa Azure Queue Storage?
- Omówienie usługi Azure Monitor
- Dokumentacja usługi Azure Pipelines
Powiązane zasoby
- Przewodnik po kodzie: aplikacja bezserwerowa z usługą Azure Functions
- Monitorowanie przetwarzania zdarzeń bezserwerowych
- Odsadanie i filtrowanie w przetwarzaniu zdarzeń bezserwerowych za pomocą usługi Event Hubs
- Scenariusz usługi Private Link w przetwarzaniu strumienia zdarzeń
- Usługa Azure Kubernetes w przetwarzaniu strumienia zdarzeń