Co nowego w usłudze Azure AI Document Intelligence
Ta zawartość dotyczy:![]() v4.0 (wersja zapoznawcza)
v4.0 (wersja zapoznawcza)![]() v3.1 (GA)v3.0 (GA)
v3.1 (GA)v3.0 (GA)![]()
![]() v2.1 (GA)
v2.1 (GA)
Usługa analizy dokumentów jest aktualizowana w sposób ciągły. Oznacz tę stronę zakładką, aby być na bieżąco z informacjami o wersji, ulepszeniami funkcji i najnowszą dokumentacją.
Ważne
Wersje interfejsu API w wersji zapoznawczej są wycofyzowane po wydaniu interfejsu API ogólnie dostępnego. Wersja interfejsu API 2023-02-28-preview jest wycofana, jeśli nadal używasz interfejsu API w wersji zapoznawczej lub skojarzonych wersji zestawu SDK, zaktualizuj kod, aby był przeznaczony dla najnowszej wersji interfejsu API 2023-07-31 (OGÓLNA dostępność).
Luty 2024 r.
Interfejs API REST analizy dokumentów 2024-02-29-preview jest teraz dostępny. Ten interfejs API w wersji zapoznawczej wprowadza nowe i zaktualizowane możliwości:
Publiczna wersja zapoznawcza 2024-02-29-preview jest obecnie dostępna tylko w następujących regionach świadczenia usługi Azure:
- Wschodnie stany USA
- Zachodnie stany USA 2
- Europa Zachodnia
Model układu obsługuje teraz wykrywanie danych i hierarchiczną analizę struktury dokumentów (sekcje i podsekcje). Poprawiono również jakość sztucznej inteligencji kolejności odczytu i wykrywania ról logicznych.
Niestandardowe modele wyodrębniania
- Niestandardowe modele wyodrębniania obsługują teraz wyniki ufności na poziomie komórek, wierszy i tabeli. Dowiedz się więcej o ufności tabeli, wiersza i komórki.
- Niestandardowe modele wyodrębniania mają ulepszenia jakości sztucznej inteligencji na potrzeby wyodrębniania pól.
- Niestandardowy model wyodrębniania szablonów obsługuje teraz wyodrębnianie nakładających się pól. Dowiedz się więcej o nakładających się polach i sposobie ich używania.
Niestandardowy model klasyfikacji
- Niestandardowy model klasyfikacji obsługuje teraz trenowanie przyrostowe dla scenariuszy, w których należy zaktualizować model klasyfikatora przy użyciu dodatkowych przykładów lub dodatkowych klas. Dowiedz się więcej o trenowaniu przyrostowym.
- Niestandardowy model klasyfikacji dodaje obsługę typów dokumentów pakietu Office (.docx, .pptx i .xls). Dowiedz się więcej o rozszerzonej obsłudze typów dokumentów.
-
- Obsługa nowych ustawień regionalnych:
Ustawienia regionalne Kod Arabski ( ar)Bułgarski ( bg)Grecki ( el)Hebrajski ( he)Macedoński ( mk)Rosyjski ( ru)Serbski cyrylica ( sr-cyrl)Ukraiński ( uk)Tajlandzki ( th)Turecki ( tr)Wietnamski ( vi)- Obsługa nowych kodów walutowych:
Waluta Ustawienia regionalne Kod BAM Bośniacki znak kabrioletu ( ba)BGN Lew bułgarski ( bg)ILS Izraelski Nowy Shekel ( il)MKD Macedoński Denar ( mk)RUB Rubel ( ru)THB Tajlandzki ( th)TRY Lira turecka ( tr)UAH Hrywinia ukraińska ( ua)VND Wietnamski Dong ( vn)- Elementy podatkowe wspierają ekspansję dla Niemiec (), Hiszpanii (
dees),Portugalii (pt), Angielski Kanadaen-CA.
-
- Rozszerzona obsługa pól dla identyfikatorów Unii Europejskiej i prawa jazdy.
-
- Wyodrębnij informacje z jednolitego wniosku o pożyczkę mieszkaniową (formularz 1003).
- Wyodrębnij informacje z formularza 1008 lub podsumowania jednolitego zapisu i przesyłania.
- Wyodrębnij informacje z ujawnienia zamknięcia kredytu hipotecznego.
🆕 Model karty kredytowej/debetowej
- Wyodrębnij informacje z kart bankowych.
-
- Nowe wstępnie utworzone w celu wyodrębnienia informacji z certyfikatów małżeństwa.
Grudzień 2023 r.
Biblioteki klienta analizy dokumentów przeznaczone dla interfejsu API REST 2023-10-31-preview są teraz dostępne do użycia!
Listopad 2023
Interfejs API REST analizy dokumentów 2023-10-31-preview jest teraz dostępny. Ten interfejs API w wersji zapoznawczej wprowadza nowe i zaktualizowane możliwości:
Publiczna wersja zapoznawcza 2023-10-31-preview jest obecnie dostępna tylko w następujących regionach świadczenia usługi Azure:
- Wschodnie stany USA
- Zachodnie stany USA 2
- Europa Zachodnia
-
- Rozszerzenie języka do pisma ręcznego: Russian(
ru), Arabski(ar), Thai(th). - Zgodność ze standardem Cyber Executive Order (EO).
- Rozszerzenie języka do pisma ręcznego: Russian(
-
- Obsługa plików pakietu Office i HTML.
- Obsługa danych wyjściowych języka Markdown.
- Ulepszenia wyodrębniania tabel, kolejności odczytu i wykrywania nagłówków sekcji.
- W przypadku wersji zapoznawczej 2023-10-31-preview ogólny model dokumentu (wstępnie utworzony dokument) jest przestarzały. W przyszłości, aby wyodrębnić pary klucz-wartość z dokumentów, użyj
prebuilt-layoutmodelu z opcjonalnym parametremfeatures=keyValuePairsciągu zapytania włączonym.
-
- Teraz wyodrębnia walutę dla wszystkich pól związanych z ceną.
Model karty ubezpieczenia zdrowotnego
- Nowe wsparcie pola dla Medicare i Medicaid informacji.
Modele dokumentów podatkowych w USA
- Nowy model podatkowy 1099. Obsługuje formularz base 1099 i następujące odmiany: A, B, C, CAP, DIV, G, H, INT, K, LS, LTC, MISC, NEC, OID, PATR, Q, QA, R, S, SA, SB.
-
- Obsługa
KVKpól. - Obsługa
BPAYpól. - Liczne udoskonalenia pól.
- Obsługa
-
- Obsługa dokumentów wielojęzycznych.
- Opcje podziału nowej strony: autosplit, zawsze podzielone według strony, bez podziału.
Uwaga
W wersji ogólnie dostępnej interfejsu API 2022-08-31 skojarzone interfejsy API w wersji zapoznawczej są przestarzałe. Jeśli używasz wersji 2021-09-30-preview, 2022-01-30-preview lub 2022-06-30-preview interfejsu API, zaktualizuj aplikacje do wersji interfejsu API 2022-08-31. Aby uzyskać więcej informacji, zobaczprzewodnik migracji.
Lipiec 2023 r.
Uwaga
Rozpoznawanie formularzy to teraz usługa Azure AI Document Intelligence!
- Dokument, usługi Azure AI obejmują wszystkie elementy, które wcześniej były znane jako Cognitive Services i aplikacja systemu Azure lied AI Services.
- Nie ma żadnych zmian w cenach.
- Nazwy usług Cognitive Services i aplikacja systemu Azure lied AI nadal są używane w rozliczeniach platformy Azure, analizie kosztów, cenniku i interfejsach API cen.
- Nie ma żadnych zmian powodujących niezgodność w interfejsach programowania aplikacji lub bibliotekach klienckich.
- Niektóre platformy nadal czekają na zmianę nazwy aktualizacji. Wszystkie wzmianki o rozpoznawaniu formularzy lub analizie dokumentów w naszej dokumentacji odnoszą się do tej samej usługi platformy Azure.
Analiza dokumentów w wersji 3.1 (ogólna dostępność)
Interfejs API analizy dokumentów w wersji 3.1 jest teraz ogólnie dostępny (GA)! Wersja interfejsu API odpowiada .2023-07-31
Interfejs API w wersji 3.1 wprowadza nowe i zaktualizowane możliwości:
- Interfejsy API analizy dokumentów są teraz bardziej modułowe i obsługują funkcje opcjonalne. Teraz możesz dostosować dane wyjściowe, aby uwzględnić potrzebne funkcje. Dowiedz się więcej o parametrach opcjonalnych.
- Interfejs API klasyfikacji dokumentów do dzielenia pojedynczego pliku na poszczególne dokumenty. Dowiedz się więcej o klasyfikacji dokumentów.
- Wstępnie utworzony model kontraktu.
- Wstępnie utworzony model amerykańskiego formularza podatkowego 1098.
- Obsługa typów plików pakietu Office przy użyciu interfejsu API odczytu.
- Rozpoznawanie kodów kreskowych w dokumentach.
- Możliwość dodawania rozpoznawania formuł.
- Możliwość dodawania rozpoznawania czcionek.
- Obsługa dokumentów o wysokiej rozdzielczości.
- Niestandardowe modele neuronowe wymagają teraz trenowania z pojedynczą etykietą przykładu.
- Rozszerzenie języka niestandardowych modeli neuronowych. Trenowanie modelu neuronowego dla dokumentów w 30 językach. Zobacz Obsługa języków, aby uzyskać pełną listę obsługiwanych języków.
- 🆕 Wstępnie utworzony model karty ubezpieczenia zdrowotnego.
- Wstępnie utworzone ustawienia regionalne modelu faktur.
- Wstępnie utworzony język modelu paragonów i rozszerzenie ustawień regionalnych z ponad 100 obsługiwanymi językami.
- Wstępnie utworzony model identyfikatorów obsługuje teraz europejskie identyfikatory.
Aktualizacje środowiska użytkownika programu Document Intelligence Studio
✔️ Opcje analizy
Analiza dokumentów obsługuje teraz bardziej zaawansowane funkcje analizy, a program Studio umożliwia łatwe konfigurowanie funkcji dodawania do jednego punktu wejścia (przycisk Analizuj opcje).
W zależności od scenariusza wyodrębniania dokumentów skonfiguruj zakres analiz, zakres stron dokumentów, opcjonalne wykrywanie i funkcje wykrywania w warstwie Premium.

Uwaga
Wyodrębnianie czcionek nie jest wizualizowane w programie Document Intelligence Studio. Można jednak sprawdzić sekcję stylów danych wyjściowych JSON pod kątem wyników wykrywania czcionek.
✔️ Automatyczne etykietowanie dokumentów przy użyciu wstępnie utworzonych modeli lub jednego z własnych modeli
Na stronie niestandardowego etykietowania modelu wyodrębniania można teraz automatycznie oznaczać dokumenty przy użyciu jednego ze wstępnie utworzonych modeli lub modeli wstępnie wytrenowanych przez usługę Document Intelligent Service.

W przypadku niektórych dokumentów po uruchomieniu automatycznej etykiety mogą być zduplikowane etykiety. Pamiętaj, aby zmodyfikować etykiety, aby nie było zduplikowanych etykiet na stronie etykietowania.

✔️ Automatyczne etykietowanie tabel
Na niestandardowej stronie etykietowania modelu wyodrębniania można teraz automatycznie etykietować tabele w dokumencie bez konieczności ręcznego etykietowania tabel.

✔️ Dodawanie plików testowych bezpośrednio do zestawu danych treningowych
Po wytrenowaniu niestandardowego modelu wyodrębniania użyj strony testowej, aby poprawić jakość modelu, przekazując dokumenty testowe do zestawu danych trenowania w razie potrzeby.
Jeśli dla niektórych etykiet zostanie zwrócony niski współczynnik ufności, upewnij się, że są one poprawnie oznaczone etykietami. Jeśli nie, dodaj je do zestawu danych szkoleniowych i ponownie określ, aby poprawić jakość modelu.

✔️ Korzystanie z opcji listy dokumentów i filtrów w projektach niestandardowych
Użyj niestandardowej strony etykietowania modelu wyodrębniania. Teraz możesz łatwo przechodzić przez dokumenty szkoleniowe, korzystając z funkcji wyszukiwania, filtrowania i sortowania według.
Użyj widoku siatki, aby wyświetlić podgląd dokumentów lub użyć widoku listy, aby łatwiej przewijać dokumenty.

✔️ Udostępnianie projektu
- Łatwe udostępnianie niestandardowych projektów wyodrębniania. Aby uzyskać więcej informacji, zobacz Udostępnianie projektu za pomocą modeli niestandardowych.
Maj 2023 r .
Wprowadzenie do odświeżonej dokumentacji kompilacji 2023
🆕 Nawigacja rozszerzona, ustrukturyzowane punkty dostępu i wzbogacone obrazy z omówieniem analizy dokumentów.
🆕 Wybieranie modelu analizy dokumentów zawiera wskazówki dotyczące wybierania najlepszego rozwiązania do analizy dokumentów dla projektów i przepływów pracy.
Kwiecień 2023
Ogłoszenie najnowszej wersji zapoznawczej biblioteki klienta analizy dokumentów
Interfejs API REST analizy dokumentów w wersji 2023-02-28-preview obsługuje biblioteki klienckie publicznej wersji zapoznawczej . Ta wersja zawiera następujące nowe funkcje i możliwości dostępne dla platformy .NET/C# (4.1.0-beta-1), Java (4.1.0-beta-1), JavaScript (4.1.0-beta-1) i Python (3.3.0b.1):
Aby uzyskać więcej informacji, zobaczInformacje o wersji zestawu Document Intelligence SDK (publiczna wersja zapoznawcza) i informacje o wersji z marca 2023 r.
Marzec 2023
Ważne
2023-02-28-preview możliwości są obecnie dostępne tylko w następujących regionach:
- West Europe
- Zachodnie stany USA 2
- Wschodnie stany USA
- Niestandardowy model klasyfikacji to nowa funkcja w ramach analizy dokumentów rozpoczynająca się od interfejsu
2023-02-28-previewAPI. Wypróbuj możliwość klasyfikacji dokumentów przy użyciu programu Document Intelligence Studio lub interfejsu API REST. - Możliwości pól zapytań dodane do modelu ogólnego dokumentu umożliwiają wyodrębnianie określonych pól z dokumentów przy użyciu modeli usługi Azure OpenAI. Wypróbuj funkcję Ogólne dokumenty z polami zapytań przy użyciu programu Document Intelligence Studio. Pola zapytań są obecnie aktywne tylko dla zasobów w
East USregionie. - Możliwości dodatków:
- Wyodrębnianie czcionek jest teraz rozpoznawane za pomocą interfejsu
2023-02-28-previewAPI. - Wyodrębnianie formuł jest teraz rozpoznawane za pomocą interfejsu
2023-02-28-previewAPI. - Wyodrębnianie o wysokiej rozdzielczości jest teraz rozpoznawane za pomocą interfejsu
2023-02-28-previewAPI.
- Wyodrębnianie czcionek jest teraz rozpoznawane za pomocą interfejsu
- Niestandardowe aktualizacje modelu wyodrębniania:
- Niestandardowy model neuronowy obsługuje teraz dodane języki do trenowania i analizy. Trenowanie modeli neuronowych dla holenderskich, francuskich, niemieckich, włoskich i hiszpańskich.
- Niestandardowy model szablonu ma teraz ulepszoną funkcję wykrywania podpisów.
- Aktualizacje programu Document Intelligence Studio :
- Oprócz obsługi wszystkich nowych funkcji, takich jak pola klasyfikacji i zapytań, program Studio umożliwia teraz udostępnianie projektów dla projektów niestandardowych modeli.
- Nowe dodatki modelu w wersji zapoznawczej: karty szczepień, umowy, podatek USA 1098, US Tax 1098-E i US Tax 1098-T. Aby zażądać dostępu do modeli w wersji zapoznawczej z bramą, ukończ i prześlij formularz żądania prywatnej wersji zapoznawczej analizy dokumentów.
- Aktualizacje modelu paragonów:
- Model paragonu dodaje obsługę paragonów termicznych.
- Model paragonu dodaje teraz obsługę języka dla 18 języków i trzech języków regionalnych (angielski, francuski, portugalski).
- Model paragonu obsługuje
TaxDetailsteraz wyodrębnianie.
- Model układu ulepsza teraz rozpoznawanie tabel.
- Model odczytu dodaje teraz ulepszenia do rozpoznawania znaków jednocyfrowych.
2023 lutego
Wybierz pozycję Kontenery analizy dokumentów dla wersji 3.0 są teraz dostępne do użycia!
Obecnie dostępne są kontenery Read v3.0 i Layout v3.0 .
Aby uzyskać więcej informacji, zobaczInstalowanie i uruchamianie kontenerów analizy dokumentów.
Styczeń 2023
Wstępnie utworzony model paragonu — dodano obsługiwane języki. Model paragonu obsługuje teraz te dodane języki i ustawienia regionalne
- Japoński — Japonia (ja-JP)
- Francuski — Kanada (fr-CA)
- Holenderski — Holandia (nl-NL)
- Angielski — Zjednoczone Emiraty Arabskie (en-AE)
- Portugalski — Brazylia (pt-BR)
Wstępnie utworzony model faktur — dodano obsługiwane języki. Model faktury obsługuje teraz te dodane języki i ustawienia regionalne
- Angielski — Stany Zjednoczone (en-US), Australia (en-AU), Kanada (en-CA), Wielka Brytania (en-UK), Indie (en-IN)
- Hiszpański — Hiszpania (es-ES)
- Francuski — Francja (fr-FR)
- Włoski — Włochy (it-IT)
- Portugalski — Portugalia (pt-PT)
- Holenderski — Holandia (nl-NL)
Wstępnie utworzony model faktury — dodano rozpoznane pola. Model faktury rozpoznaje teraz te dodane pola
- Kod waluty
- Opcje płatności
- Rabat końcowy
- Elementy podatkowe (tylko en-IN)
Wstępnie utworzony model identyfikatorów — dodano obsługiwane typy dokumentów. Model identyfikatorów obsługuje teraz te dodane typy dokumentów
- Identyfikator wojskowy USA
Napiwek
Wszystkie aktualizacje ze stycznia 2023 r. są dostępne w interfejsie API REST w wersji 2022-08-31 (GA).
Wstępnie utworzony model paragonu — dodatkowa obsługa języka:
Wstępnie utworzony model paragonu dodaje obsługę następujących języków:
- Angielski — Zjednoczone Emiraty Arabskie (en-AE)
- Holenderski — Holandia (nl-NL)
- Francuski — Kanada (fr-CA)
- Niemiecki — (de-DE)
- Włoski — (it-IT)
- Japoński — Japonia (ja-JP)
- Portugalski — Brazylia (pt-BR)
Wstępnie utworzony model faktury — dodatkowa obsługa języka i wyodrębnianie pól
Wstępnie utworzony model faktury dodaje obsługę następujących języków:
- Angielski — Australia (en-AU), Kanada (en-CA), Wielka Brytania (en-UK), Indie (en-IN)
- Portugalski — Brazylia (pt-BR)
Wstępnie utworzony model faktury dodaje teraz obsługę następujących wyodrębnień pól:
- Kod waluty
- Opcje płatności
- Rabat końcowy
- Elementy podatkowe (tylko en-IN)
Wstępnie utworzony model dokumentu identyfikatora — obsługa dodatkowych typów dokumentów
Wstępnie utworzony model dokumentu identyfikatora dodaje teraz obsługę następujących typów dokumentów:
- Rozszerzenie licencji kierowcy wspierające Indie, Kanada, Wielka Brytania i Australia
- Amerykańskie karty identyfikatorów wojskowych i dokumenty
- Karty identyfikatorów Indii i dokumenty (PAN i Aadhaar)
- Karty tożsamości i dokumenty w Australii (karta zdjęciowa, identyfikator klucza)
- Karty tożsamości Kanady i dokumenty (karty identyfikacyjnej, karty maple)
- Dowody tożsamości i dokumenty Zjednoczonego Królestwa (krajowe/regionalne karty tożsamości)
Grudzień 2022
Aktualizacje programu Document Intelligence Studio
Wersja programu Document Intelligence Studio z grudnia zawiera najnowsze aktualizacje programu Document Intelligence Studio. Istnieją znaczące ulepszenia środowiska użytkownika, głównie dzięki obsłudze etykietowania niestandardowego modelu.
Zakres stron. Program Studio obsługuje teraz analizowanie określonych stron z dokumentu.
Niestandardowe etykietowanie modelu:
Automatycznie uruchom interfejs API układu. Możesz zdecydować się na automatyczne uruchamianie interfejsu API układu dla wszystkich dokumentów w magazynie obiektów blob podczas procesu instalacji modelu niestandardowego.
Wyszukaj. Program Studio zawiera teraz funkcję wyszukiwania w celu lokalizowania wyrazów w dokumencie. To ulepszenie umożliwia łatwiejsze nawigację podczas etykietowania.
Nawigacja. Możesz wybrać etykiety, aby oznaczyć wyrazy etykietami docelowymi w dokumencie.
Automatyczne etykietowanie tabel. Po wybraniu ikony tabeli w dokumencie możesz wybrać automatyczne etykietowanie wyodrębnionej tabeli w widoku etykietowania.
Podtypy etykiet i podtypy drugiego poziomu Program Studio obsługuje teraz podtypy kolumn tabeli, wierszy tabeli i podtypów drugiego poziomu dla typów, takich jak daty i liczby.
Tworzenie niestandardowych modeli neuronowych jest teraz obsługiwane w regionie US Gov Virginia.
Wersje
2022-01-30-previewinterfejsu API w wersji zapoznawczej i2021-09-30-previewzostaną wycofane 31 stycznia 2023 r. Przeprowadź aktualizację do wersji interfejsu API,2022-08-31aby uniknąć zakłóceń w działaniu usługi.
Listopad 2022
- Ogłoszenie najnowszej stabilnej wersji bibliotek analizy dokumentów usługi Azure AI
- Ta wersja zawiera ważne zmiany i aktualizacje bibliotek klienckich .NET, Java, JavaScript i Python. Aby uzyskać więcej informacji, zobaczAzure SDK DevBlog.
- Najważniejsze ulepszenia to wprowadzenie dwóch nowych klientów: i
DocumentAnalysisClientDocumentModelAdministrationClient.
Październik 2022
Zawartość z wersją analizy dokumentów
Dokumentacja analizy dokumentów została zaktualizowana, aby przedstawić środowisko wersji. Teraz możesz wyświetlić zawartość przeznaczoną dla
v3.0 GAśrodowiska lubv2.1 GAśrodowiska. Środowisko w wersji 3.0 jest domyślne.
Przykładowy kod programu Document Intelligence Studio
- Przykładowy kod środowiska etykietowania usługi Document Intelligence Studio jest teraz dostępny w witrynie GitHub. Klienci mogą opracowywać i integrować analizę dokumentów z własnym środowiskiem użytkownika lub tworzyć własne nowe środowisko użytkownika przy użyciu przykładowego kodu usługi Document Intelligence Studio.
Rozszerzanie języka
- W najnowszej wersji zapoznawczej modele odczytu (OCR), układu i szablonu niestandardowego analizy dokumentów obsługują 134 nowe języki. Dodatki te obejmują grecki, łotewski, serbski, tajski, ukraiński i wietnamski, wraz z kilkoma językami łacińskimi i cyrylica. Analiza dokumentów ma teraz łącznie 299 obsługiwanych języków w najnowszych wersjach ogólnodostępnych i nowych wersji zapoznawczych. Zapoznaj się ze stroną obsługiwanych języków , aby wyświetlić wszystkie obsługiwane języki.
- Użyj parametru
api-version=2022-06-30-previewinterfejsu API REST podczas korzystania z interfejsu API lub odpowiedniego zestawu SDK, aby obsługiwać nowe języki w aplikacjach.
Nowy wstępnie utworzony model kontraktu
- Nowa wstępnie utworzona funkcja wyodrębnia informacje z kontraktów, takich jak strony, tytuł, identyfikator kontraktu, data wykonania i inne. model kontraktów jest obecnie w wersji zapoznawczej, żądaj dostępu tutaj.
Rozszerzanie regionów na potrzeby trenowania niestandardowych modeli neuronowych
- Trenowanie niestandardowych modeli neuronowych jest teraz obsługiwane w dodanych regionach.
- East US
- Wschodnie stany USA 2
- US Gov Arizona
- Trenowanie niestandardowych modeli neuronowych jest teraz obsługiwane w dodanych regionach.
2022 września
Uwaga
Począwszy od wersji 4.0.0, wprowadzono nowy zestaw klientów korzystających z najnowszych funkcji usługi Analizy dokumentów.
Wersja zestawu SDK 4.0.0 (ogólna dostępność) zawiera następujące aktualizacje:
- Wersja 4.0.0 GA (2022-09-08)
- Obsługuje klientów interfejsu API REST w wersji 3.0 i 2.0
Rozszerzanie regionów na potrzeby trenowania niestandardowych modeli neuronowych jest teraz obsługiwane w sześciu nowych regionach
- Australia Wschodnia
- Central US
- Azja Wschodnia
- Francja Środkowa
- Południowe Zjednoczone Królestwo
- Zachodnie stany USA 2
Aby uzyskać pełną listę regionów, w których obsługiwane jest trenowanie, zobacz niestandardowe modele neuronowe.
Wersja zestawu
4.0.0 GASDK analizy dokumentów:- Biblioteki klienta analizy dokumentów w wersji 4.0.0 (.NET/C#, Java, JavaScript) i 3.2.0 (Python) są ogólnie dostępne i gotowe do użycia w aplikacjach produkcyjnych!.
- Aby uzyskać więcej informacji na temat bibliotek klienta analizy dokumentów, zobacz omówienie zestawu SDK.
- Zaktualizuj aplikacje przy użyciu przewodnika migracji języka programowania.
Sierpień 2022
Wersja zapoznawcza zestawu Document Intelligence SDK z sierpnia 2022 r. obejmuje następujące aktualizacje:
Wersja 4.0.0-beta.5 (2022-08-09)
Analiza dokumentów w wersji 3.0 jest ogólnie dostępna
- Interfejs API REST analizy dokumentów w wersji 3.0 jest teraz ogólnie dostępny i gotowy do użycia w aplikacjach produkcyjnych! Zaktualizuj aplikacje przy użyciu interfejsu API REST w wersji 2022-08-31.
Aktualizacje programu Document Intelligence Studio
- Następne kroki. Na każdej stronie modelu program Studio ma teraz następną sekcję kroków. Użytkownicy mogą szybko odwoływać się do przykładowego kodu, wytycznych dotyczących rozwiązywania problemów i informacji o cenach.
- Modele niestandardowe. Program Studio oferuje teraz możliwość zmiany kolejności etykiet w niestandardowych projektach modelu w celu zwiększenia wydajności etykietowania.
- Modele niestandardowe kopiowania można kopiować między usługami analizy dokumentów z poziomu programu Studio. Operacja umożliwia podwyższenie poziomu wytrenowanego modelu do innych środowisk i regionów.
- Usuń dokumenty. Program Studio obsługuje teraz usuwanie dokumentów z oznaczonego zestawu danych w projektach niestandardowych.
Aktualizacje usługi Analizy dokumentów
- wstępnie skompilowany odczyt. Odczyt modelu OCR jest teraz również dostępny w usłudze Document Intelligence z akapitami i wykrywaniem języka jako dwie nowe funkcje. Odczyt analizy dokumentów jest przeznaczony dla zaawansowanych scenariuszy dokumentów dostosowanych do szerszych możliwości analizy dokumentów w usłudze Document Intelligence.
- wstępnie utworzony układ. Model układu wyodrębnia akapity i określa, czy wyodrębniony tekst jest akapitem, tytułem, nagłówkiem sekcji, przypisem dolnym, nagłówkiem strony, stopką strony lub numerem strony.
- wstępnie utworzona faktura. Pola TotalVAT i Line/VAT są teraz rozpoznawane odpowiednio dla istniejących pól TotalTax i Line/Tax.
- prebuilt-idDocument. Obsługa wyodrębniania danych dla identyfikatorów stanu USA, zabezpieczeń społecznych i zielonych kart. Wsparcie dla informacji o wizie paszportowej.
- wstępnie utworzone potwierdzenie. Rozszerzona obsługa ustawień regionalnych dla języka francuskiego (fr-FR), hiszpańskiego (es-ES), portugalskiego (pt-PT), włoskiego (it-IT) i niemieckiego (de-DE).
- wstępnie utworzona karta biznesowa. Obsługa analizowania adresów w celu wyodrębniania pól podrzędnych dla składników adresów, takich jak adres, miasto, stan, kraj/region i kod pocztowy.
Ulepszenia jakości sztucznej inteligencji
- wstępnie skompilowany odczyt. Ulepszona obsługa pojedynczych znaków, dat odręcznych, kwot, nazw, innych kluczowych danych często spotykanych w paragonach i fakturach oraz ulepszonego przetwarzania cyfrowych dokumentów PDF.
- wstępnie utworzony układ. Obsługa lepszego wykrywania przyciętych tabel, tabel bez obramowania i ulepszonego rozpoznawania długich komórek.
- wstępnie utworzony dokument. Ulepszona wartość i wykrywanie pól wyboru.
- niestandardowe neuronowe. Ulepszona dokładność wykrywania i wyodrębniania tabel.
Czerwiec 2022
- Wersja zapoznawcza zestawu DOCUMENT Intelligence SDK w czerwcu 2022 r. obejmuje następujące aktualizacje:
Wersja 4.0.0-beta.4 (2022-06-08)
Wersja usługi Document Intelligence Studio w czerwcu to najnowsza aktualizacja programu Document Intelligence Studio. W tej aktualizacji uwzględniono znaczne ulepszenia środowiska użytkownika i ułatwień dostępu:
- Przykład kodu dla języków JavaScript i C#. Karta Kod programu Studio dodaje teraz przykłady kodu JavaScript i C# oprócz istniejącego języka Python.
- Interfejs użytkownika przekazywania nowego dokumentu. Program Studio obsługuje teraz przekazywanie dokumentu z przeciągnięciem i upuszczaniem do nowego interfejsu użytkownika przekazywania.
- Nowa funkcja dla projektów niestandardowych. Projekty niestandardowe obsługują teraz tworzenie konta magazynu i obiektów blob podczas konfigurowania projektu. Ponadto projekt niestandardowy obsługuje teraz przekazywanie plików szkoleniowych bezpośrednio w programie Studio i kopiowanie istniejącego modelu niestandardowego.
W wersji 3.0 2022-06-30-preview analiza dokumentów zawiera obszerne aktualizacje w interfejsach API funkcji:
- Układ rozszerza wyodrębnianie struktury. Układ zawiera teraz dodane elementy struktury, w tym sekcje, nagłówki sekcji i akapity. Ta aktualizacja umożliwia bardziej szczegółowe scenariusze segmentacji dokumentów. Aby uzyskać pełną listę zidentyfikowanych elementów struktury, zobaczulepszoną strukturę.
- Obsługa niestandardowych pól tabelarycznych modelu neuronowego. Niestandardowe modele dokumentów obsługują teraz pola tabelaryczne. Pola tabelaryczne domyślnie są również wielostronicowe. Aby dowiedzieć się więcej na temat pól tabelarycznych w niestandardowych modelach neuronowych, zobaczpola tabelaryczne.
- Obsługa niestandardowych pól tabelarycznych modelu szablonów dla tabel międzystronicowych. Niestandardowe modele formularzy obsługują teraz pola tabelaryczne na stronach. Aby dowiedzieć się więcej na temat pól tabelarycznych w niestandardowych modelach szablonów, zobaczpola tabelaryczne.
- Dane wyjściowe modelu faktury obejmują teraz ogólne pary klucz-wartość dokumentu. Jeśli faktury zawierają wymagane pola poza polami zawartymi w wstępnie utworzonym modelu, ogólny model dokumentu uzupełnia dane wyjściowe parami klucz-wartość. Zobaczpary klucz-wartość.
- Rozszerzenie języka faktur. Model faktur obejmuje rozszerzoną obsługę języka. Zobaczobsługiwane języki.
- Wstępnie utworzona wizytówka obejmuje teraz obsługę języka japońskiego. Zobaczobsługiwane języki.
- Wstępnie utworzony model dokumentu identyfikatora. Model dokumentu identyfikatora wyodrębnia teraz element DateOfIssue, Height, Weight, EyeColor, HairColor i DocumentDiscriminator z licencji kierowców w USA. Zobaczwyodrębnianie pól.
- Model odczytu obsługuje teraz typowe typy dokumentów pakietu Microsoft Office. Typy dokumentów, takie jak Word (docx), Excel (xlsx) i PowerPoint (pptx) są teraz obsługiwane za pomocą interfejsu API odczytu. Zobacz Wyodrębnianie danych do odczytu.
Luty 2022 r.
Wersja 4.0.0-beta.3 (2022-02-10)
Wersja zapoznawcza analizy dokumentów w wersji 3.0 wprowadza kilka nowych funkcji, możliwości i ulepszeń:
- Niestandardowy model neuronowy lub niestandardowy model dokumentów to nowy model niestandardowy do wyodrębniania tekstu i znaków zaznaczania ze strukturą, częściowo ustrukturyzowanych i nieustrukturyzowanych dokumentów.
- W-2 wstępnie utworzony model to nowy wstępnie utworzony model umożliwiający wyodrębnianie pól z formularzy W-2 na potrzeby scenariuszy raportowania podatków i weryfikacji dochodów.
- Interfejs API odczytu wyodrębnia drukowane wiersze tekstu, wyrazy, lokalizacje tekstu, wykryte języki i tekst odręczny, jeśli zostanie wykryty.
- Ogólny wstępnie wytrenowany model dokumentu jest teraz aktualizowany w celu obsługi znaków zaznaczenia oprócz tekstu interfejsu API, tabel, struktury i par klucz-wartość z formularzy i dokumentów.
- Wstępnie utworzony model faktur dla interfejsu API faktur rozszerza obsługę hiszpańskich faktur.
- Usługa Document Intelligence Studio dodaje nowe pokazy dla przykładów odczytu, W2, paragonów hotelowych i obsługi trenowania nowych niestandardowych modeli neuronowych.
- Rozszerzenie języka analiza dokumentów odczyt, układ i formularz niestandardowy dodaje obsługę 42 nowych języków, w tym arabskich, hindi i innych języków przy użyciu skryptów arabskich i Devanagari w celu rozszerzenia zasięgu do 164 języków. Obsługa języka odręcznego rozszerza się na japoński i koreański.
Rozpocznij pracę z nowym interfejsem API REST, językiem Python lub zestawem .NET SDK dla interfejsu API w wersji 3.0 w wersji zapoznawczej.
Wyodrębnianie danych modelu analizy dokumentów:
Model Wyodrębnianie tekstu Pary klucz-wartość Znaczniki zaznaczenia Tabele Podpisy Przeczytaj ✓ Dokument ogólny ✓ ✓ ✓ ✓ Układ ✓ ✓ ✓ Faktura ✓ ✓ ✓ ✓ Przyjęcie ✓ ✓ ✓ Dokument tożsamości ✓ ✓ Karta biznesowa ✓ ✓ Szablon niestandardowy ✓ ✓ ✓ ✓ ✓ Niestandardowe neuronowe ✓ ✓ ✓ ✓ Wersja zapoznawcza zestawu SDK analizy dokumentów w wersji beta zawiera następujące aktualizacje:
Niestandardowe modele i tryby dokumentów:
- Szablon niestandardowy (wcześniej formularz niestandardowy).
- Niestandardowe neuronowe.
- Model niestandardowy — tryb kompilacji.
W-2 wstępnie utworzony model (wstępnie utworzony-tax.us.w2).
Odczyt wstępnie utworzonego modelu (wstępnie skompilowany odczyt).
Wstępnie utworzony model faktury (hiszpański) (wstępnie utworzona faktura).
Listopad 2021
Wersja 4.0.0-beta.2 (2021-11-09)
| Dokumentacja interfejsu API package (NuGet) | Changelog/Release History API |
- Aktualizacja wersji zapoznawczej zestawu SDK analizy dokumentów w wersji 3.0 (beta.2) obejmuje poprawki błędów i drobne aktualizacje funkcji.
Październik 2021
Wersja zapoznawcza analizy dokumentów w wersji 3.0 w wersji zapoznawczej 4.0.0-beta.1 (2021-10-07)wprowadza kilka nowych funkcji i możliwości:
Ogólny model dokumentów to nowy interfejs API, który używa wstępnie wytrenowanego modelu do wyodrębniania tekstu, tabel, struktury i par klucz-wartość z formularzy i dokumentów.
Model paragonów hotelowych dodany do wstępnie utworzonego przetwarzania paragonów.
Rozwinięte pola dokumentu identyfikatora modelu id obsługują zatwierdzenia, ograniczenia i wyodrębnianie klasyfikacji pojazdów z licencji kierowców w USA.
Pole sygnatury to nowy typ pola w formularzach niestandardowych umożliwiający wykrywanie obecności podpisu w polu formularza.
Obsługa rozszerzenia języka dla 122 języków (druku) i 7 języków (odręcznych). Układ analizy dokumentów i formularz niestandardowy rozszerzają obsługiwane języki do wersji 122, korzystając z najnowszej wersji zapoznawczej. Podgląd obejmuje wyodrębnianie tekstu do drukowania tekstu w 49 nowych językach, w tym rosyjski, bułgarski i inne cyrylica i inne języki łacińskie. Ponadto wyodrębnianie tekstu odręcznego obsługuje teraz siedem języków, które obejmują język angielski i nowe wersje zapoznawcze chińskich uproszczonych, francuskich, niemieckich, włoskich, portugalskich i hiszpańskich.
Ulepszenia tabel i wyodrębniania tekstu Układ obsługuje teraz wyodrębnianie tabel z pojedynczym wierszem nazywanych również tabelami klucz-wartość. Ulepszenia wyodrębniania tekstu obejmują lepsze przetwarzanie cyfrowych plików PDF i tekstu strefy do odczytu maszyny (MRZ) w dokumentach tożsamości wraz z ogólną wydajnością.
Document Intelligence Studio Aby uprościć korzystanie z usługi, możesz teraz uzyskać dostęp do programu Document Intelligence Studio , aby przetestować różne wstępnie utworzone modele lub etykietę i wytrenować model niestandardowy.
Rozpocznij pracę z nowym interfejsem API REST, językiem Python lub zestawem .NET SDK dla interfejsu API w wersji 3.0 w wersji zapoznawczej.
Wyodrębnianie danych modelu analizy dokumentów
Model Wyodrębnianie tekstu Pary klucz-wartość Znaczniki zaznaczenia Tabele Dokument ogólny ✓ ✓ ✓ ✓ Układ ✓ ✓ ✓ Faktura ✓ ✓ ✓ ✓ Przyjęcie ✓ ✓ Dokument tożsamości ✓ ✓ Karta biznesowa ✓ ✓ Niestandardowy ✓ ✓ ✓ ✓
Wrzesień 2021
Zaawansowane funkcje eksploratora metryk platformy Azure są dostępne na stronie przeglądu zasobów analizy dokumentów w witrynie Azure Portal.
Menu Monitorowania:

Wykresy:

Aktualizacja modelu dokumentu identyfikatora: podane nazwy, w tym sufiks, z kropką lub bez kropki (pełne zatrzymanie), proces zakończył się pomyślnie:
Tekst wejściowy Wynik z aktualizacją William Isaac Kirby Jr. FirstName: William Isaac
LastName: Kirby Jr.Henry Caleb Ross Sr FirstName: Henry Caleb
LastName: Ross Sr.
Lipiec 2021
- Obsługa tożsamości zarządzanej przypisanej przez system: można teraz włączyć przypisaną przez system tożsamość zarządzaną w celu udzielenia ograniczonego dostępu analizy dokumentów do prywatnych kont magazynu, w tym kont chronionych przez sieć wirtualną, zaporę lub włączoną funkcję byOS (bring-your-own-storage). Aby dowiedzieć się więcej, zobaczTworzenie i używanie tożsamości zarządzanej dla zasobu analizy dokumentów.
Czerwiec 2021
Kontenery analizy dokumentów w wersji 2.1 wydane w wersji zapoznawczej z bramą i są teraz obsługiwane przez sześć kontenerów funkcji — układ, wizytówkę, dokument identyfikatora, potwierdzenie, fakturę i niestandardowe. Aby ich używać, musisz przesłać żądanie online i otrzymać zatwierdzenie.
Łącznik analizy dokumentów wydany w wersji zapoznawczej: łącznik analizy dokumentów integruje się z usługami Azure Logic Apps, Microsoft Power Automate i Microsoft Power Apps. Łącznik obsługuje akcje i wyzwalacze przepływu pracy w celu wyodrębniania i analizowania danych dokumentów oraz struktury z niestandardowych i wstępnie utworzonych formularzy, faktur, paragonów, wizytówek i dokumentów identyfikatorów.
Zestaw Document Intelligence SDK w wersji 3.1.0 został poprawiony do wersji 3.1.1 dla języków C#, Java i Python. Poprawki adresują faktury, które nie mają wykrytych pól elementów podrzędnych, takich jak element bez
FormFieldTextBoundingBoxinformacji lubPagebez.
Maj 2021 r .
- Wersja 3.1.0 (2021-05-26)
Dokumentacja dotycząca dziennika zmian/historii| | wydania — pakiet NuGet w wersji 3.0.1 |
Analiza dokumentów 2.1 jest ogólnie dostępna. Wersja ogólnie dostępna oznacza stabilność zmian wprowadzonych w poprzednich wersjach pakietu w wersji zapoznawczej 2.1. Ta wersja umożliwia wykrywanie i wyodrębnianie informacji i danych z następujących typów dokumentów:
Aby rozpocząć pracę, wypróbuj przykładowe narzędzie do analizy dokumentów i postępuj zgodnie z przewodnikiem Szybki start.
Zaktualizowana funkcja tabeli interfejsu API układu dodaje rozpoznawanie nagłówków z nagłówkami kolumn, które mogą obejmować wiele wierszy. Każda komórka tabeli ma atrybut wskazujący, czy jest częścią nagłówka, czy nie. Ta aktualizacja może służyć do identyfikowania wierszy tworzących nagłówek tabeli.
Kwiecień 2021
Pakiet NuGet w wersji 3.1.0-beta.4
Dziennik zmian/historia wydania.
Nowe metody analizowania danych z dokumentów tożsamości:
StartRecognizeIdDocumentsFromUriAsync
StartRecognizeIdDocumentsAsync
Aby uzyskać listę wartości pól, zobaczPola wyodrębnione w dokumentacji analizy dokumentów.
Rozszerzono zestaw języków dokumentów, które można udostępnić metodzie StartRecognizeContent .
Nowa właściwość
Pagesobsługiwana przez następujące klasy:RecognizeBusinessCardsOptions
RecognizeCustomFormsOptions
RecognizeInvoicesOptions
RecognizeReceiptsOptionsWłaściwość
Pagespozwala wybrać poszczególne lub zakres stron dla wielostronicowych dokumentów PDF i TIFF. W przypadku poszczególnych stron wprowadź numer strony, na przykład3. W przypadku zakresu stron (takich jak strona 2 i strony 5–7) wprowadź numery wiekowe i zakresy rozdzielone przecinkami:2, 5-7.Nowa właściwość
ReadingOrderobsługiwana dla następującej klasy:Właściwość
ReadingOrderjest opcjonalnym parametrem, który umożliwia określenie algorytmu kolejności odczytu —basiclubnatural— należy zastosować w celu uporządkowania wyodrębniania elementów tekstowych. Jeśli nie zostanie określony, wartość domyślna tobasic.
- Aktualizacje wersji zapoznawczej zestawu SDK dla wersji
2.1-preview.3interfejsu API zawierają aktualizacje funkcji i ulepszenia.
Marzec 2021
Udostępniono publiczną wersję zapoznawczą analizy dokumentów w wersji 2.1-preview.3 i udostępniono następujące funkcje:
Nowy wstępnie utworzony model identyfikatorów Nowy wstępnie utworzony model identyfikatorów umożliwia klientom przejmowanie identyfikatorów i zwracanie danych strukturalnych w celu zautomatyzowania przetwarzania. Łączy nasze zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z modelami rozumienia identyfikatorów w celu wyodrębnienia kluczowych informacji z paszportów i licencji kierowców USA.
Dowiedz się więcej o wstępnie utworzonym modelu identyfikatorów

Wyodrębnianie elementów liniowych dla modelu faktury — wstępnie utworzony model faktury obsługuje teraz wyodrębnianie elementów liniowych. Teraz wyodrębnia pełne elementy i ich części — opis, ilość, ilość, identyfikator produktu, data i inne. Za pomocą prostego wywołania interfejsu API/zestawu SDK możesz wyodrębnić przydatne dane z faktur — tekst, tabela, pary klucz-wartość i elementy wiersza.
Dowiedz się więcej o modelu faktur.
Nadzorowane etykietowanie tabel i trenowanie, etykietowanie pustych wartości — oprócz najnowocześniejszej funkcji automatycznego wyodrębniania tabel w usłudze Document Intelligence umożliwia klientom etykietowanie i szkolenie w tabelach. Ta nowa wersja obejmuje możliwość etykietowania i trenowania elementów/tabel wierszy (dynamicznych i stałych) oraz trenowania modelu niestandardowego w celu wyodrębniania par klucz-wartość i elementów liniowych. Po wytrenowanym modelu model wyodrębnia elementy wiersza jako część danych wyjściowych JSON w sekcji documentResults.

Oprócz tabel etykietowania można teraz oznaczać puste wartości i regiony. Jeśli niektóre dokumenty w zestawie treningowym nie mają wartości dla niektórych pól, możesz oznaczyć je etykietami, aby model mógł prawidłowo wyodrębnić wartości z analizowanych dokumentów.
Obsługa 66 nowych języków — interfejs API układu i modele niestandardowe na potrzeby analizy dokumentów obsługują teraz 73 języki.
Dowiedz się więcej o obsłudze języka analizy dokumentów.
Kolejność czytania naturalnego, klasyfikacja pisma ręcznego i wybór strony — dzięki tej aktualizacji można pobrać dane wyjściowe wiersza tekstu w kolejności odczytu naturalnego zamiast domyślnej kolejności od lewej do prawej i od góry do dołu. Użyj nowego parametru zapytania readingOrder i ustaw go na wartość "natural" w celu uzyskania bardziej przyjaznych dla człowieka danych wyjściowych kolejności odczytu. Ponadto w przypadku języków łacińskich inteligencja dokumentów klasyfikuje wiersze tekstu jako styl odręczny lub nie i daje wynik ufności.
Wstępnie utworzone ulepszenia jakości modelu paragonów Ta aktualizacja zawiera wiele ulepszeń jakości dla wstępnie utworzonego modelu paragonu, szczególnie w przypadku wyodrębniania elementów liniowych.


Listopad 2020
Usługa Document Intelligence w wersji 2.1-preview.2 została wydana i zawiera następujące funkcje:
Nowy wstępnie utworzony model faktury — nowy wstępnie utworzony model faktury umożliwia klientom wykonywanie faktur w różnych formatach i zwracanie danych ustrukturyzowanych w celu zautomatyzowania przetwarzania faktur. Łączy ona nasze zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z modelami uczenia głębokiego opisem faktur w celu wyodrębnienia kluczowych informacji z faktur w języku angielskim. Wyodrębnia on tekst klucza, tabele i informacje, takie jak klient, dostawca, identyfikator faktury, data ukończenia faktury, łączna kwota, kwota należności, kwota podatku, wysyłka i rachunek.

Ulepszone wyodrębnianie tabel — analiza dokumentów udostępnia teraz ulepszone wyodrębnianie tabel, które łączy nasze zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z modelem wyodrębniania tabel uczenia głębokiego. Analiza dokumentów może wyodrębniać dane z tabel, w tym złożone tabele ze scalanymi kolumnami, wierszami, bez obramowań i nie tylko.

Aktualizacja biblioteki klienta — najnowsze wersje bibliotek klienckich dla platform .NET, Python, Java i JavaScript obsługują interfejs API analizy dokumentów 2.1.
Obsługiwany jest nowy język: Japoński — obsługiwane są teraz następujące nowe języki: for
AnalyzeLayoutiAnalyzeCustomForm: Japoński (ja). Obsługa języków.Wskazanie stylu wiersza tekstu (tylko odręczne/inne) (tylko języki łacińskie) — analiza dokumentów generuje
appearanceteraz obiekt klasyfikujący, czy każdy wiersz tekstu jest stylem odręcznym, czy nie, wraz z oceną ufności. Ta funkcja jest obsługiwana tylko w językach łacińskich.Ulepszenia jakości — ulepszenia wyodrębniania, w tym ulepszenia wyodrębniania pojedynczej cyfry.
Nowa funkcja try-it-out w narzędziu Do próbkowania i etykietowania analizy dokumentów — możliwość wypróbowania wstępnie utworzonych modeli faktur, paragonów i wizytówek oraz interfejsu API układu przy użyciu narzędzia do etykietowania przykładowego analizy dokumentów. Zobacz, jak dane są wyodrębniane bez konieczności pisania kodu.
Wypróbuj narzędzie do etykietowania przykładu analizy dokumentów

- Pętla opinii — podczas analizowania plików za pomocą narzędzia Do etykietowania przykładowego można teraz również dodać je do zestawu treningowego i dostosować etykiety w razie potrzeby i wytrenować, aby ulepszyć model.
- Automatyczne etykietowanie dokumentów — automatycznie etykiety dodały dokumenty na podstawie poprzednich dokumentów oznaczonych etykietą w projekcie.


Sierpień 2020
**Analiza
v2.1-preview.1dokumentów obejmuje następujące funkcje:- Dostępna jest dokumentacja interfejsu API REST — wyświetl element
v2.1-preview.1 reference. - Nowe języki obsługiwane oprócz języka angielskiego są teraz obsługiwane następujące języki : dla
LayoutiTrain Custom Model: angielski (), chiński (enuproszczony) (zh-Hans), holenderskinl(), francuski (fr), niemieckide(), włoskiit(), portugalski (pt) i hiszpański (es). - Wykrywanie zaznaczenia/znacznika zaznaczenia — analiza dokumentów obsługuje wykrywanie i wyodrębnianie znaków zaznaczenia, takich jak pola wyboru i przyciski radiowe. Znaczniki wyboru są wyodrębniane
Layouti można teraz również oznaczyć i trenować wTrain Custom Model- obszarze Train with Labels (Trenowanie za pomocą etykiet), aby wyodrębnić pary klucz-wartość dla znaków wyboru. - Model Compose — umożliwia tworzenie wielu modeli i wywoływanie ich za pomocą jednego identyfikatora modelu. Po przesłaniu dokumentu do przeanalizowania za pomocą złożonego identyfikatora modelu krok klasyfikacji jest najpierw wykonywany w celu kierowania go do poprawnego modelu niestandardowego. Redagowanie modelu jest dostępne w przypadku
Train Custom Model- trenowania z etykietami. - Nazwa modelu — dodaj przyjazną nazwę do modeli niestandardowych, aby ułatwić zarządzanie i śledzenie.
- Nowy wstępnie utworzony model wizytówek na potrzeby wyodrębniania typowych pól w języku angielskim, językowych wizytówek.
- Nowe ustawienia regionalne dla wstępnie utworzonych paragonów oprócz EN-US, obsługa jest teraz dostępna dla EN-AU, EN-CA, EN-GB, EN-IN.
- Ulepszenia jakości dla programu
Train Custom Model-Layout, trenowanie bez etykiet i trenowanie za pomocą etykiet.
- Dostępna jest dokumentacja interfejsu API REST — wyświetl element
Wersja 2.0 zawiera następującą aktualizację:
- Biblioteki klienckie dla języków NET, Python, Java i JavaScript są ogólnie dostępne.
Nowe przykłady są dostępne w witrynie GitHub.
- Podręcznik przepisy wyodrębniania wiedzy — formularze zbiera najlepsze rozwiązania z rzeczywistych zaangażowania klientów analizy dokumentów i udostępnia użyteczne przykłady kodu, listy kontrolne i przykładowe potoki używane podczas tworzenia tych projektów.
- Narzędzie Do etykietowania przykładowego zostało zaktualizowane w celu obsługi nowej funkcji w wersji 2.1. Zobacz ten przewodnik Szybki start , aby rozpocząć pracę z narzędziem.
- W przykładzie Intelligent Kiosk Document Intelligence pokazano, jak zintegrować
Analyze ReceiptiTrain Custom Model- trenować bez etykiet.
Lipiec 2020
- Dostępna dokumentacja analizy dokumentów w wersji 2.0 — wyświetl dokumentację interfejsu API w wersji 2.0 i zaktualizowane biblioteki klienta dla platform .NET, Python, Java i JavaScript.
Ulepszenia tabel i ulepszenia wyodrębniania tabel — obejmują ulepszenia dokładności i ulepszenia wyodrębniania tabel, w szczególności możliwość uczenia nagłówków tabel i struktur w niestandardowym pociągu bez etykiet.
Obsługa waluty — wykrywanie i wyodrębnianie symboli globalnych walut.
Azure Gov — analiza dokumentów jest teraz również dostępna w witrynie Azure Gov .
Ulepszone funkcje zabezpieczeń:
- Przynieś własny klucz — analiza dokumentów automatycznie szyfruje dane, gdy są utrwalane w chmurze, aby je chronić i ułatwiają spełnienie zobowiązań organizacji w zakresie zabezpieczeń i zgodności. Domyślnie subskrypcja używa kluczy szyfrowania zarządzanych przez firmę Microsoft. Teraz możesz również zarządzać subskrypcją przy użyciu własnych kluczy szyfrowania. Klucze zarządzane przez klienta, znane również jako bring your own key (BYOK), oferują większą elastyczność tworzenia, obracania, wyłączania i odwoływanie kontroli dostępu. Możesz również przeprowadzać inspekcję kluczy szyfrowania używanych do ochrony danych.
- Prywatne punkty końcowe — umożliwia sieci wirtualnej bezpieczny dostęp do danych za pośrednictwem usługi Private Link.
Czerwiec 2020
- Interfejs API CopyModel dodany do bibliotek klienckich — teraz możesz użyć bibliotek klienckich do kopiowania modeli z jednej subskrypcji do innej. Aby uzyskać ogólne informacje na temat tej funkcji, zobacz Tworzenie kopii zapasowych i odzyskiwanie modeli .
- Integracja usługi Azure Active Directory — teraz możesz użyć poświadczeń usługi Azure AD do uwierzytelniania obiektów klienta analizy dokumentów w bibliotekach klienckich.
- Zmiany specyficzne dla zestawu SDK — ta zmiana obejmuje zarówno drobne dodatki funkcji, jak i zmiany powodujące niezgodność. Aby uzyskać więcej informacji, zobacz dzienniki zmian zestawu SDK.
Kwiecień 2020
- Obsługa zestawu SDK dla interfejsu API analizy dokumentów w wersji 2.0 w wersji 2.0 — w tym miesiącu rozszerzyliśmy obsługę usługi, aby uwzględnić zestaw SDK w wersji zapoznawczej dla wersji 2.0 analizy dokumentów. Użyj tych linków, aby rozpocząć pracę z wybranym językiem:
- Zestaw SDK platformy .NET
- Zestaw SDK Java
- Zestaw SDK dla języka Python
- Zestaw SDK dla języka JavaScript
Nowy zestaw SDK obsługuje wszystkie funkcje interfejsu API REST w wersji 2.0 na potrzeby analizy dokumentów. Swoją opinię możesz podzielić się swoimi opiniami na temat bibliotek klienckich za pomocą formularza opinii zestawu SDK.
Skopiuj model niestandardowy Teraz możesz kopiować modele między regionami i subskrypcjami przy użyciu nowej funkcji Kopiuj model niestandardowy. Przed wywołaniem interfejsu API kopiowania modelu niestandardowego należy najpierw uzyskać autoryzację do skopiowania do zasobu docelowego. Ta autoryzacja jest zabezpieczona przez wywołanie operacji kopiowania autoryzacji względem docelowego punktu końcowego zasobu.
Ulepszenia zabezpieczeń.
Klucze zarządzane przez klienta są teraz dostępne dla klasy FormRecognizer. Aby uzyskać więcej informacji, zobacz Szyfrowanie danych magazynowanych na potrzeby analizy dokumentów.
Użyj tożsamości zarządzanych, aby uzyskać dostęp do zasobów platformy Azure za pomocą usługi Azure Active Directory. Aby uzyskać więcej informacji, zobacz Autoryzowanie dostępu do tożsamości zarządzanych.
Marzec 2020 r.
- Typy wartości do etykietowania Możesz teraz określić typy wartości, które etykietujesz za pomocą narzędzia do etykietowania przykładowego analizy dokumentów. Obecnie obsługiwane są następujące typy wartości i odmiany:
string- wartość domyślna,
no-whitespaces,alphanumeric
- wartość domyślna,
number- Domyślny
currency
- Domyślny
date- default,
dmy, ,mdyymd
- default,
timeinteger
Zobacz przewodnik po narzędziu do etykietowania przykładowego, aby dowiedzieć się, jak używać tej funkcji.
Wizualizacja tabeli Narzędzie do etykietowania przykładowego wyświetla teraz tabele, które zostały rozpoznane w dokumencie. Ta funkcja umożliwia wyświetlanie rozpoznanych i wyodrębnionych tabel z dokumentu przed etykietowaniem i analizowaniem. Tę funkcję można włączać/wyłączać przy użyciu opcji warstw.
Na poniższej ilustracji przedstawiono przykład sposobu rozpoznawania i wyodrębniania tabel:
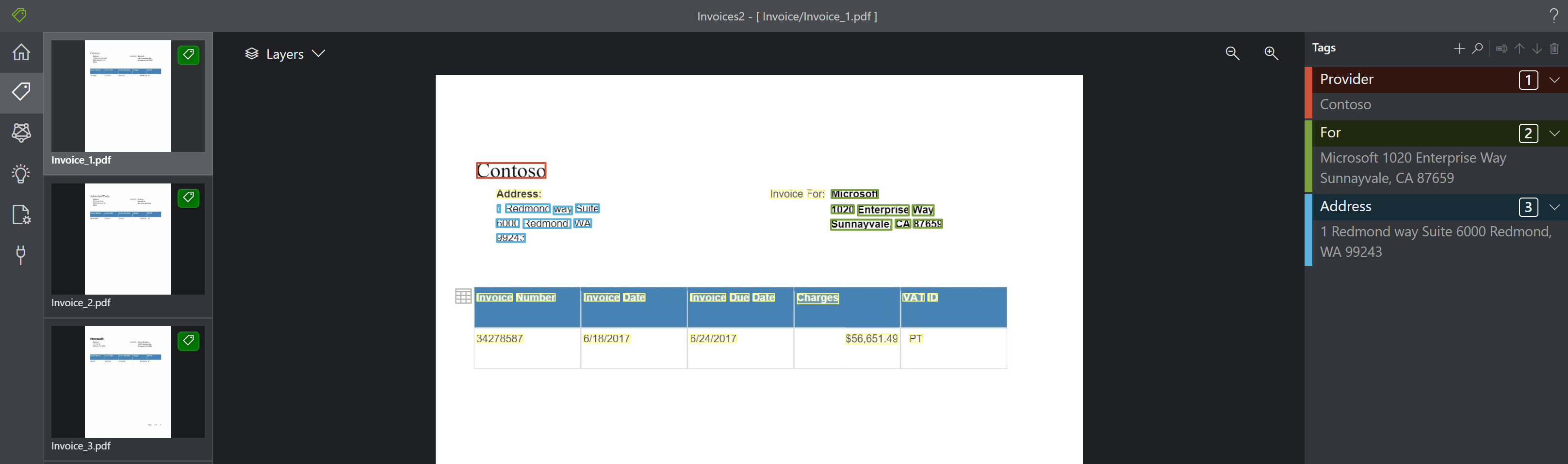
Wyodrębnione tabele są dostępne w danych wyjściowych JSON w obszarze
"pageResults".Ważne
Tabele etykietowania nie są obsługiwane. Jeśli tabele nie są rozpoznawane i wyodrębniane automatycznie, można oznaczyć je tylko jako pary klucz/wartość. Podczas etykietowania tabel jako par klucz/wartość należy oznaczyć każdą komórkę jako unikatową wartość.
Ulepszenia wyodrębniania.
Ta wersja obejmuje ulepszenia wyodrębniania i ulepszenia dokładności, w szczególności możliwość etykietowania i wyodrębniania wielu par klucz/wartość w tym samym wierszu tekstu.
Przykładowe narzędzie etykietowania jest teraz open source.
Narzędzie do etykietowania przykładowego analizy dokumentów jest teraz dostępne jako projekt open source. Możesz ją zintegrować w swoich rozwiązaniach i wprowadzić zmiany specyficzne dla klienta, aby spełniały Twoje potrzeby.
Aby uzyskać więcej informacji na temat narzędzia do etykietowania przykładowego analizy dokumentów, zapoznaj się z dokumentacją dostępną w usłudze GitHub.
TLS1.2 wymuszanie.TLS1.2 jest teraz wymuszany dla wszystkich żądań HTTP do tej usługi. Aby uzyskać więcej informacji, zobacz Zabezpieczenia usług Azure AI.
Styczeń 2020
W tej wersji wprowadzono analizę dokumentów w wersji 2.0. W następnych sekcjach znajdziesz więcej informacji na temat nowych funkcji, ulepszeń i zmian.
Nowe funkcje
Model niestandardowy
- Trenowanie za pomocą etykiet Możesz teraz wytrenować model niestandardowy z ręcznie oznaczonymi danymi. Ta metoda daje lepsze wyniki modeli i może tworzyć modele, które współpracują ze złożonymi formularzami lub formularzami zawierającymi wartości bez kluczy.
- Asynchroniczny interfejs API możesz użyć asynchronicznych wywołań interfejsu API do trenowania i analizowania dużych zestawów danych i plików.
- Obsługa plików TIFF Można teraz trenować przy użyciu dokumentów TIFF i wyodrębniać je.
- Ulepszenia dokładności wyodrębniania.
Wstępnie utworzony model paragonu
- Kwoty porad Możesz teraz wyodrębnić kwoty porad i inne wartości odręczne.
- Wyodrębnianie elementów liniowych Można wyodrębnić wartości elementów liniowych z paragonów.
- Wartości ufności Możesz wyświetlić pewność modelu dla każdej wyodrębnionej wartości.
- Ulepszenia dokładności wyodrębniania.
- Wyodrębnianie układu Możesz teraz użyć interfejsu API układu do wyodrębniania danych tekstowych i danych tabeli z formularzy.
Zmiany interfejsu API modelu niestandardowego
Zmieniono nazwy wszystkich interfejsów API do trenowania i używania modeli niestandardowych, a niektóre metody synchroniczne są teraz asynchroniczne. Poniżej przedstawiono poważne zmiany:
- Proces trenowania modelu jest teraz asynchroniczny. Inicjowanie trenowania za pomocą wywołania interfejsu API /custom/models . To wywołanie zwraca identyfikator operacji, który można przekazać do niestandardowych/modeli/{modelID} , aby zwrócić wyniki trenowania.
- Wyodrębnianie klucza/wartości jest teraz inicjowane przez wywołanie interfejsu API /custom/models/{modelID}/analyze . To wywołanie zwraca identyfikator operacji, który można przekazać do niestandardowych/modeli/{modelID}/analyzeResults/{resultID} w celu zwrócenia wyników wyodrębniania.
- Identyfikatory operacji dla operacji Trenowanie znajdują się teraz w nagłówku Lokalizacja odpowiedzi HTTP, a nie w nagłówku Operation-Location .
Zmiany interfejsu API paragonów
Nazwy interfejsów API do odczytywania paragonów sprzedaży są zmieniane.
Wyodrębnianie danych paragonu jest teraz inicjowane przez wywołanie interfejsu API /prebuilt/receipt/analyze . To wywołanie zwraca identyfikator operacji, który można przekazać do /prebuilt/receipt/analyzeResults/{resultID} , aby zwrócić wyniki wyodrębniania.
Zmiany formatu danych wyjściowych
- Odpowiedzi JSON dla wszystkich wywołań interfejsu API mają nowe formaty. Niektóre klucze i wartości są dodawane, usuwane lub zmieniane. Zobacz przewodniki Szybki start, aby zapoznać się z przykładami bieżących formatów JSON.
Następne kroki
Spróbuj przetwarzać własne formularze i dokumenty za pomocą programu Document Intelligence Studio.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.
Spróbuj przetwarzać własne formularze i dokumenty za pomocą narzędzia do etykietowania przykładowego analizy dokumentów.
Ukończ przewodnik Szybki start dotyczący analizy dokumentów i rozpocznij tworzenie aplikacji do przetwarzania dokumentów w wybranym języku programowania.