Samouczek: tworzenie kompleksowego potoku danych w celu uzyskania szczegółowych informacji o sprzedaży w usłudze Azure HDInsight
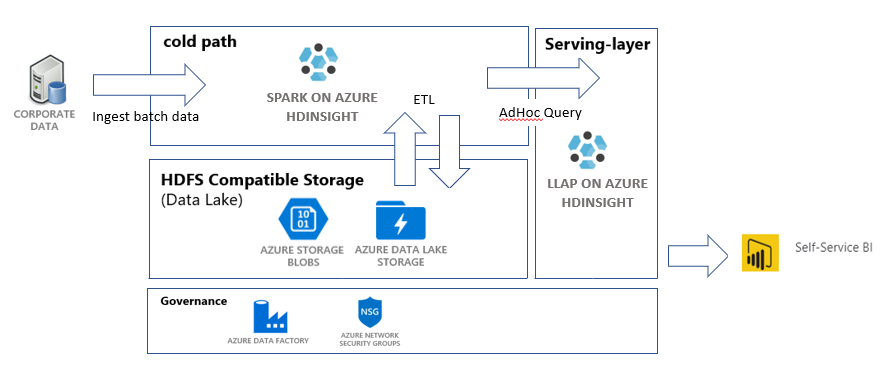
W tym samouczku utworzysz pełny potok danych, który wykonuje operacje wyodrębniania, przekształcania i ładowania (ETL). Potok będzie używać klastrów Apache Spark i Apache Hive działających w usłudze Azure HDInsight do wykonywania zapytań i manipulowania danymi. Użyjesz również technologii takich jak Azure Data Lake Storage Gen2 na potrzeby przechowywania danych i usługi Power BI na potrzeby wizualizacji.
Ten potok danych łączy dane z różnych magazynów, usuwa wszelkie niepożądane dane, dołącza nowe dane i ładuje je z powrotem do magazynu w celu wizualizacji analiz biznesowych. Przeczytaj więcej na temat potoków ETL w temacie Wyodrębnianie, przekształcanie i ładowanie (ETL) na dużą skalę.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Interfejs wiersza polecenia platformy Azure — co najmniej wersja 2.2.0. Zobacz Instalowanie interfejsu wiersza polecenia platformy Azure.
jq, procesor JSON wiersza polecenia. Zobacz: https://stedolan.github.io/jq/.
Członek wbudowanej roli platformy Azure — właściciel.
Jeśli używasz programu PowerShell do wyzwalania potoku usługi Data Factory, potrzebujesz modułu Az.
Program Power BI Desktop umożliwia wizualizowanie szczegółowych informacji biznesowych na końcu tego samouczka.
Tworzenie zasobów
Klonowanie repozytorium za pomocą skryptów i danych
Zaloguj się do subskrypcji platformy Azure. Jeśli planujesz używać usługi Azure Cloud Shell, wybierz pozycję Wypróbuj w prawym górnym rogu bloku kodu. W przeciwnym razie wprowadź poniższe polecenie:
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Upewnij się, że jesteś członkiem właściciela roli platformy Azure. Zastąp
user@contoso.comciąg swoim kontem, a następnie wprowadź polecenie:az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"Jeśli żaden rekord nie zostanie zwrócony, nie jesteś członkiem i nie będzie można ukończyć tego samouczka.
Pobierz dane i skrypty dla tego samouczka z repozytorium ETL szczegółowych informacji o sprzedaży usługi HDInsight. Podaj następujące polecenie:
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlUpewnij się, że
salesdata scripts templateszostały utworzone. Sprawdź przy użyciu następującego polecenia:ls
Wdrażanie zasobów platformy Azure wymaganych dla potoku
Dodaj uprawnienia wykonywania dla wszystkich skryptów, wprowadzając następujące polecenie:
chmod +x scripts/*.shUstaw zmienną dla grupy zasobów. Zastąp
RESOURCE_GROUP_NAMEciąg nazwą istniejącej lub nowej grupy zasobów, a następnie wprowadź polecenie:RESOURCE_GROUP="RESOURCE_GROUP_NAME"Uruchom skrypt. Zastąp
LOCATIONciąg żądaną wartością, a następnie wprowadź polecenie:./scripts/resources.sh $RESOURCE_GROUP LOCATIONJeśli nie masz pewności, który region ma być określony, możesz pobrać listę obsługiwanych regionów dla subskrypcji za pomocą polecenia az account list-locations .
Polecenie wdroży następujące zasoby:
- Konto usługi Azure Blob Storage. To konto będzie przechowywać dane sprzedaży firmy.
- Konto usługi Azure Data Lake Storage Gen2. To konto będzie służyć jako konto magazynu dla obu klastrów usługi HDInsight. Przeczytaj więcej na temat integracji usług HDInsight i Data Lake Storage Gen2 w usłudze Azure HDInsight z usługą Data Lake Storage Gen2.
- Tożsamość zarządzana przypisana przez użytkownika. To konto zapewnia klastrom usługi HDInsight dostęp do konta usługi Data Lake Storage Gen2.
- Klaster Apache Spark. Ten klaster będzie używany do czyszczenia i przekształcania danych pierwotnych.
- Klaster zapytań interakcyjnych apache Hive. Ten klaster umożliwia wykonywanie zapytań dotyczących danych sprzedaży i wizualizowanie ich za pomocą usługi Power BI.
- Sieć wirtualna platformy Azure obsługiwana przez reguły sieciowej grupy zabezpieczeń. Ta sieć wirtualna umożliwia klastrom komunikowanie się i zabezpieczanie komunikacji.
Tworzenie klastra może potrwać około 20 minut.
Domyślne hasło dostępu SSH do klastrów to Thisisapassword1. Jeśli chcesz zmienić hasło, przejdź do ./templates/resourcesparameters_remainder.json pliku i zmień hasło parametrów sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPasswordi llapsshPassword .
Weryfikowanie wdrożenia i zbieranie informacji o zasobach
Jeśli chcesz sprawdzić stan wdrożenia, przejdź do grupy zasobów w witrynie Azure Portal. W obszarze Ustawienia wybierz pozycję Wdrożenia, a następnie wdrożenie. W tym miejscu można zobaczyć zasoby, które zostały pomyślnie wdrożone, oraz zasoby, które są nadal w toku.
Aby wyświetlić nazwy klastrów, wprowadź następujące polecenie:
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEAby wyświetlić konto usługi Azure Storage i klucz dostępu, wprowadź następujące polecenie:
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYAby wyświetlić konto usługi Data Lake Storage Gen2 i klucz dostępu, wprowadź następujące polecenie:
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Tworzenie fabryki danych
Azure Data Factory to narzędzie, które pomaga zautomatyzować usługę Azure Pipelines. Nie jest to jedyny sposób na wykonanie tych zadań, ale jest to doskonały sposób automatyzacji procesów. Aby uzyskać więcej informacji na temat usługi Azure Data Factory, zobacz dokumentację usługi Azure Data Factory.
Ta fabryka danych będzie mieć jeden potok z dwoma działaniami:
- Pierwsze działanie spowoduje skopiowanie danych z usługi Azure Blob Storage na konto magazynu usługi Data Lake Storage Gen 2, aby naśladować pozyskiwanie danych.
- Drugie działanie spowoduje przekształcenie danych w klastrze Spark. Skrypt przekształca dane, usuwając niechciane kolumny. Dołącza również nową kolumnę, która oblicza przychód generowany przez jedną transakcję.
Aby skonfigurować potok usługi Azure Data Factory, wykonaj poniższe polecenie. Nadal powinien znajdować się w hdinsight-sales-insights-etl katalogu .
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
Ten skrypt wykonuje następujące czynności:
- Tworzy jednostkę usługi z uprawnieniami
Storage Blob Data Contributorna koncie magazynu usługi Data Lake Storage Gen2. - Uzyskuje token uwierzytelniania w celu autoryzowania żądań POST do interfejsu API REST systemu plików usługi Data Lake Storage Gen2.
- Wypełnia rzeczywistą nazwę konta magazynu usługi Data Lake Storage Gen2 w plikach
sparktransform.pyiquery.hql. - Uzyskuje klucze magazynu dla kont usługi Data Lake Storage Gen2 i usługi Blob Storage.
- Tworzy kolejne wdrożenie zasobów w celu utworzenia potoku usługi Azure Data Factory ze skojarzonymi połączonymi usługami i działaniami. Przekazuje klucze magazynu jako parametry do pliku szablonu, aby połączone usługi mogły prawidłowo uzyskiwać dostęp do kont magazynu.
Uruchamianie potoku danych
Wyzwalanie działań usługi Data Factory
Pierwsze działanie w potoku usługi Data Factory, które zostało utworzone, przenosi dane z usługi Blob Storage do usługi Data Lake Storage Gen2. Drugie działanie stosuje przekształcenia platformy Spark na danych i zapisuje przekształcone pliki .csv w nowej lokalizacji. Ukończenie całego potoku może potrwać kilka minut.
Aby pobrać nazwę usługi Data Factory, wprowadź następujące polecenie:
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
Aby wyzwolić potok, możesz wykonać następujące czynności:
Wyzwalanie potoku usługi Data Factory w programie PowerShell. Zastąp
RESOURCEGROUPwartości , iDataFactoryNameodpowiednimi wartościami, a następnie uruchom następujące polecenia:# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipelineGet-AzDataFactoryV2PipelineRunWykonaj ponownie w razie potrzeby, aby monitorować postęp.Or
Otwórz fabrykę danych i wybierz pozycję Utwórz i monitoruj. Wyzwól
IngestAndTransformpotok z portalu. Aby uzyskać informacje na temat wyzwalania potoków za pośrednictwem portalu, zobacz Tworzenie klastrów Apache Hadoop na żądanie w usłudze HDInsight przy użyciu usługi Azure Data Factory.
Aby sprawdzić, czy potok został uruchomiony, możesz wykonać jedną z następujących czynności:
- Przejdź do sekcji Monitorowanie w fabryce danych za pośrednictwem portalu.
- W Eksplorator usługi Azure Storage przejdź do konta magazynu usługi Data Lake Storage Gen 2. Przejdź do systemu plików, a następnie przejdź do
filestransformedfolderu i sprawdź jego zawartość, aby sprawdzić, czy potok zakończył się pomyślnie.
Aby uzyskać inne sposoby przekształcania danych przy użyciu usługi HDInsight, zobacz ten artykuł dotyczący korzystania z notesu Jupyter Notebook.
Tworzenie tabeli w klastrze Interactive Query w celu wyświetlania danych w usłudze Power BI
Skopiuj plik do klastra
query.hqlLLAP przy użyciu punktu połączenia usługi. Wprowadź polecenie:LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/Przypomnienie: domyślne hasło to
Thisisapassword1.Użyj protokołu SSH, aby uzyskać dostęp do klastra LLAP. Wprowadź polecenie:
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.netUżyj następującego polecenia, aby uruchomić skrypt:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlTen skrypt utworzy tabelę zarządzaną w klastrze Interactive Query, do którego można uzyskać dostęp z usługi Power BI.
Tworzenie pulpitu nawigacyjnego usługi Power BI na podstawie danych sprzedaży
Otwórz Power BI Desktop.
Z menu przejdź do pozycji Pobierz dane>Więcej...>Interakcyjne zapytanie usługi Azure>HDInsight.
Wybierz pozycję Połącz.
W oknie dialogowym Interaktywne zapytanie usługi HDInsight:
- W polu tekstowym Serwer wprowadź nazwę klastra LLAP w formacie
https://LLAPCLUSTERNAME.azurehdinsight.net. - W polu tekstowym bazy danych wprowadź .
default - Wybierz przycisk OK.
- W polu tekstowym Serwer wprowadź nazwę klastra LLAP w formacie
W oknie dialogowym AzureHive:
- W polu tekstowym Nazwa użytkownika wprowadź .
admin - W polu tekstowym Hasło wprowadź wartość
Thisisapassword1. - Wybierz pozycję Połącz.
- W polu tekstowym Nazwa użytkownika wprowadź .
W obszarze Nawigator wybierz pozycję
salesi/lubsales_raw, aby wyświetlić podgląd danych. Po załadowaniu danych możesz eksperymentować z pulpitem nawigacyjnym, który chcesz utworzyć. Zobacz następujące linki, aby rozpocząć pracę z pulpitami nawigacyjnymi usługi Power BI:
- Wprowadzenie do pulpitów nawigacyjnych dla projektantów usługi Power BI
- Samouczek: wprowadzenie do usługa Power BI
Czyszczenie zasobów
Jeśli nie zamierzasz nadal korzystać z tej aplikacji, usuń wszystkie zasoby przy użyciu następującego polecenia, aby nie były naliczane opłaty.
Aby usunąć grupę zasobów, wprowadź polecenie:
az group delete -n $RESOURCE_GROUPAby usunąć jednostkę usługi, wprowadź polecenia:
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL