Tworzenie, opracowywanie i konserwację notesów usługi Synapse w usłudze Azure Synapse Analytics
Notes usługi Synapse to interfejs internetowy umożliwiający tworzenie plików zawierających kod na żywo, wizualizacje i tekst narracji. Notesy to dobre miejsce do weryfikowania pomysłów i przeprowadzania krótkich eksperymentów w celu uzyskania szczegółowych informacji na podstawie danych. Notesy są również szeroko używane w scenariuszach przygotowywania danych, wizualizacji danych, uczenia maszynowego i innych scenariuszy danych big data.
Notes usługi Synapse umożliwia:
- Rozpocznij pracę z zerowym nakładem pracy z konfiguracją.
- Zachowaj bezpieczeństwo danych za pomocą wbudowanych funkcji zabezpieczeń przedsiębiorstwa.
- Analizowanie danych w formatach pierwotnych (CSV, txt, JSON itp.), przetworzonych formatów plików (parquet, Delta Lake, ORC itp.) i plików danych tabelarycznych SQL na platformie Spark i sql.
- Wydajniej dzięki ulepszonym możliwościom tworzenia i wbudowanym wizualizacjom danych.
W tym artykule opisano sposób używania notesów w Synapse Studio.
Tworzenie notesu
Istnieją dwa sposoby tworzenia notesu. Możesz utworzyć nowy notes lub zaimportować istniejący notes do obszaru roboczego usługi Synapse z Eksplorator obiektów. Notesy usługi Synapse rozpoznają standardowe pliki Jupyter Notebook IPYNB.
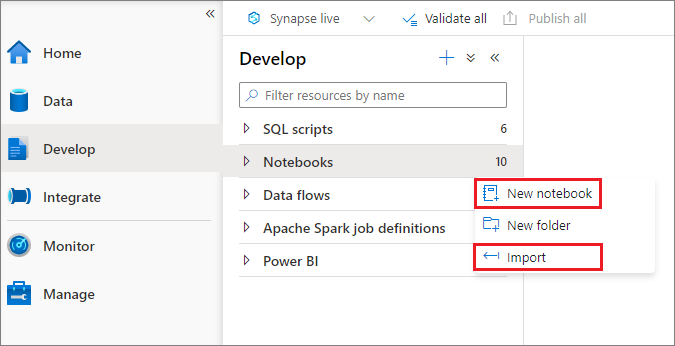
Tworzenie notesów
Notesy składają się z komórek, które są pojedynczymi blokami kodu lub tekstu, które mogą być uruchamiane niezależnie lub jako grupa.
Udostępniamy zaawansowane operacje tworzenia notesów:
- Dodawanie komórki
- Ustawianie języka podstawowego
- Korzystanie z wielu języków
- Używanie tabel tymczasowych do odwołowania się do danych w różnych językach
- IntelliSense w stylu IDE
- Fragmenty kodu
- Formatowanie komórki tekstowej za pomocą przycisków paska narzędzi
- Cofnij/Wykonaj ponownie operację komórki
- Komentowanie komórek kodu
- Przenoszenie komórki
- Usuwanie komórki
- Zwiń dane wejściowe komórki
- Zwiń dane wyjściowe komórki
- Konspekt notesu
Uwaga
W notesach jest automatycznie tworzona aplikacja SparkSession przechowywana w zmiennej o nazwie spark. Istnieje również zmienna sparkContext o nazwie sc. Użytkownicy mogą uzyskiwać bezpośredni dostęp do tych zmiennych i nie powinni zmieniać wartości tych zmiennych.
Dodawanie komórki
Istnieje wiele sposobów dodawania nowej komórki do notesu.
Umieść kursor na przestrzeni między dwiema komórkami i wybierz pozycję Kod lub Markdown.
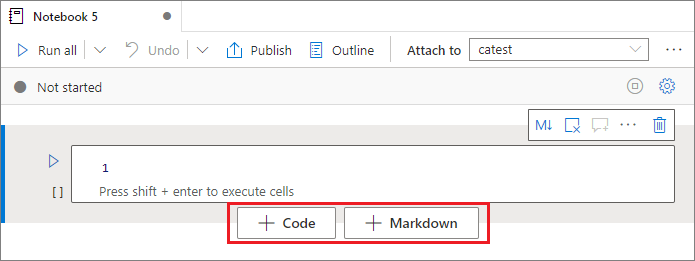
Użyj klawiszy skrótów aznb w trybie polecenia. Naciśnij klawisz A , aby wstawić komórkę nad bieżącą komórką. Naciśnij klawisz B , aby wstawić komórkę poniżej bieżącej komórki.
Ustawianie języka podstawowego
Notesy usługi Synapse obsługują cztery języki platformy Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
Możesz ustawić język podstawowy dla nowych dodanych komórek z listy rozwijanej na górnym pasku poleceń.
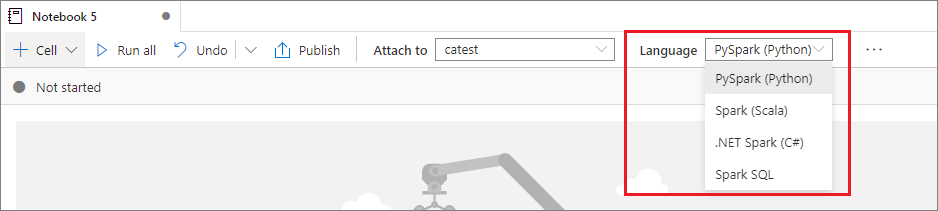
Korzystanie z wielu języków
Można użyć wielu języków w jednym notesie, określając poprawne polecenie magic języka na początku komórki. W poniższej tabeli wymieniono polecenia magic umożliwiające przełączanie języków komórek.
| Polecenie Magic | Język | Opis |
|---|---|---|
| %%pyspark | Python | Wykonaj zapytanie w języku Python względem kontekstu platformy Spark. |
| %%spark | Scala | Wykonaj zapytanie Scala względem kontekstu platformy Spark. |
| %%sql | SparkSQL | Wykonaj zapytanie SparkSQL względem kontekstu platformy Spark. |
| %%csharp | .NET dla platformy Spark C# | Wykonaj zapytanie platformy .NET dla języka C# platformy Spark względem kontekstu platformy Spark. |
| %%sparkr | R | Wykonaj zapytanie języka R względem kontekstu platformy Spark. |
Na poniższej ilustracji przedstawiono przykład sposobu pisania zapytania PySpark przy użyciu polecenia magic %%pyspark lub zapytania SparkSQL za pomocą polecenia magic %%sql w notesie Spark(Scala). Zwróć uwagę, że język podstawowy notesu jest ustawiony na pySpark.
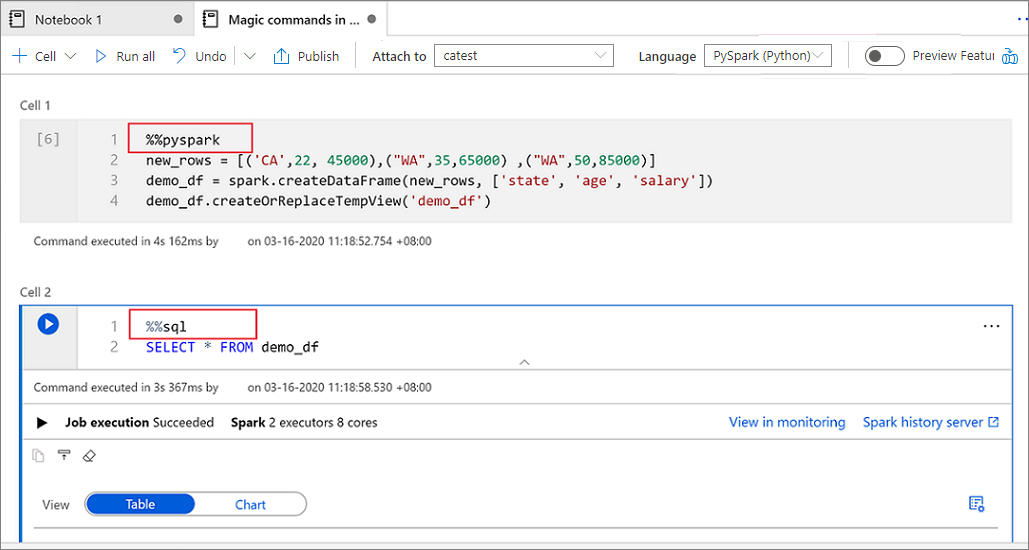
Używanie tabel tymczasowych do odwołowania się do danych w różnych językach
Nie można odwoływać się do danych ani zmiennych bezpośrednio w różnych językach w notesie usługi Synapse. Na platformie Spark można odwoływać się do tabeli tymczasowej w różnych językach. Oto przykład sposobu odczytywania Scala ramki danych w PySpark tabeli tymczasowej Platformy Spark i SparkSQL używania jej jako obejścia.
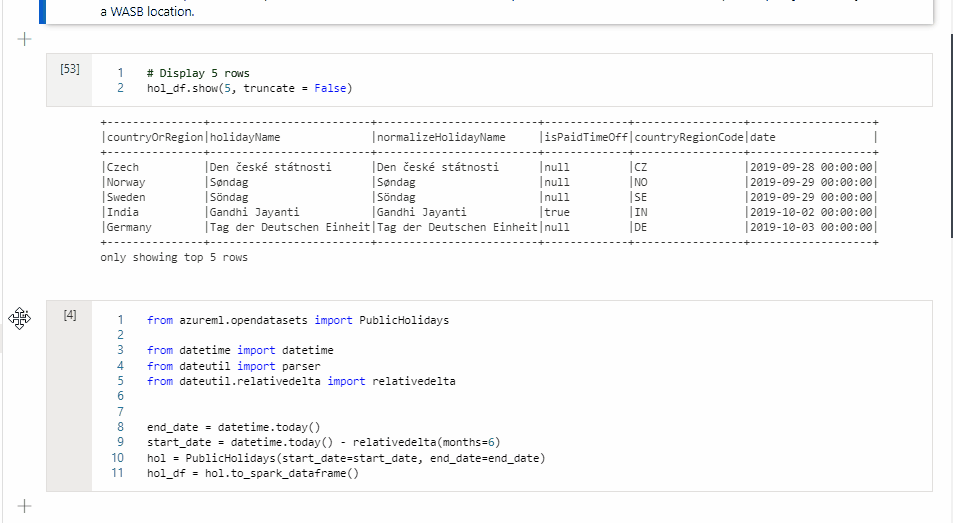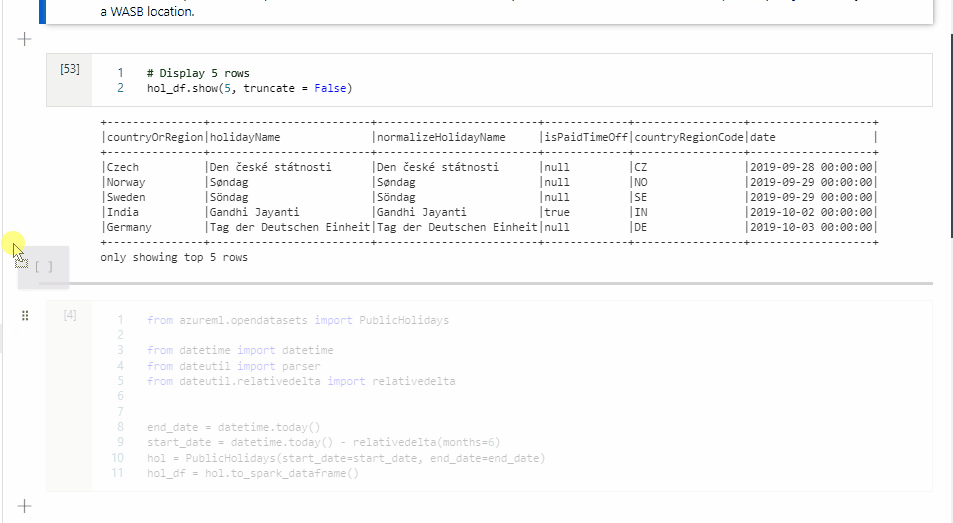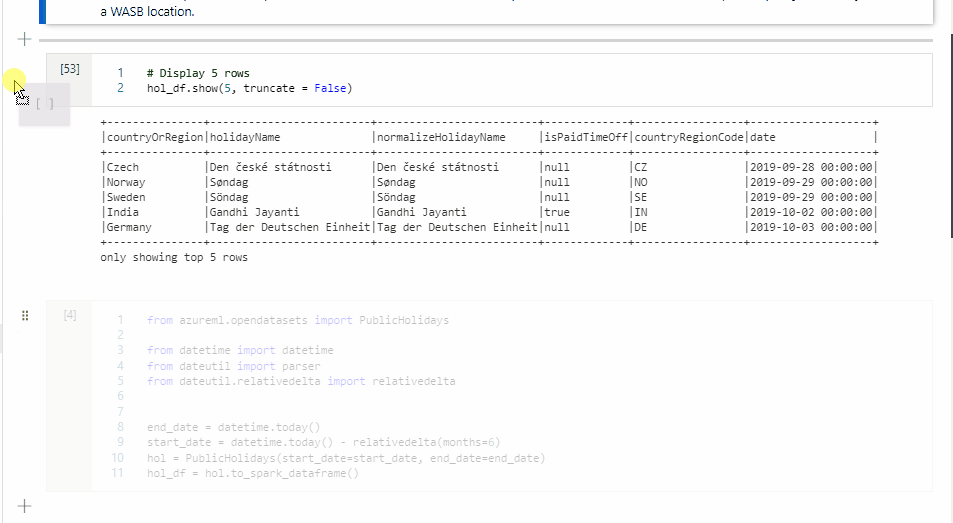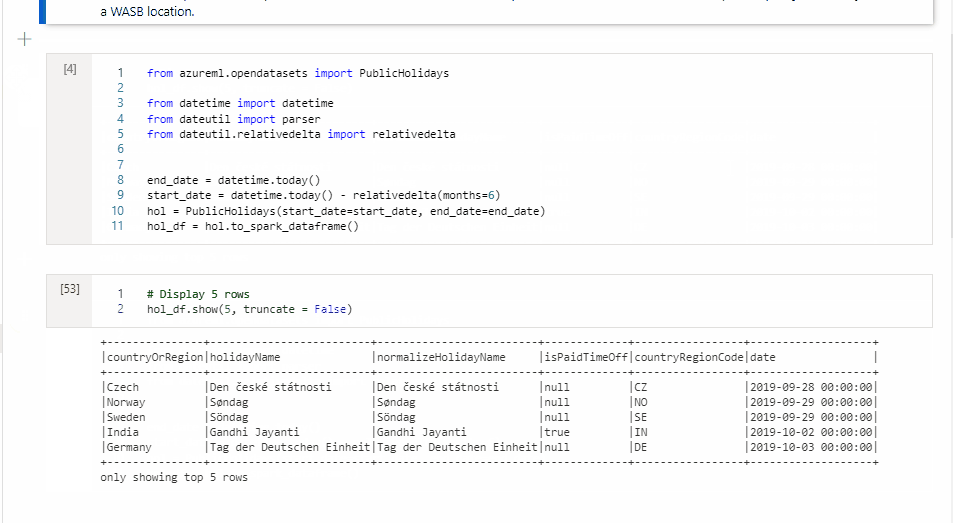
W komórce 1 odczytaj ramkę danych z łącznika puli SQL przy użyciu języka Scala i utwórz tabelę tymczasową.
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )W komórce 2 wykonaj zapytanie dotyczące danych przy użyciu języka Spark SQL.
%%sql SELECT * FROM mydataframetableW komórce 3 użyj danych w PySpark.
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IntelliSense w stylu IDE
Notesy usługi Synapse są zintegrowane z edytorem Monaco w celu włączenia funkcji IntelliSense w stylu IDE do edytora komórek. Wyróżnianie składni, znacznik błędów i automatyczne uzupełnianie kodu ułatwia pisanie kodu i szybsze identyfikowanie problemów.
Funkcje IntelliSense są na różnych poziomach dojrzałości dla różnych języków. Skorzystaj z poniższej tabeli, aby zobaczyć, co jest obsługiwane.
| Języki | Wyróżnianie składni | Znacznik błędu składniowego | Uzupełnianie kodu składniowego | Uzupełnianie kodu zmiennej | Uzupełnianie kodu funkcji systemu | Uzupełnianie kodu funkcji użytkownika | Inteligentne wcięcie | Składanie kodu |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Tak | Tak | Tak | Tak | Tak | Tak | Tak | Tak |
| Spark (Scala) | Tak | Tak | Tak | Tak | Tak | Tak | - | Tak |
| SparkSQL | Tak | Tak | Tak | Tak | Tak | - | - | - |
| .NET dla platformy Spark (C#) | Tak | Tak | Tak | Tak | Tak | Tak | Tak | Tak |
Uwaga
Aktywna sesja platformy Spark jest wymagana, aby korzystać ze zmiennej uzupełniania kodu, uzupełniania kodu funkcji systemu, uzupełniania kodu funkcji użytkownika dla platformy .NET dla platformy Spark (C#).
Wstawki kodu
Notesy usługi Synapse udostępniają fragmenty kodu, które ułatwiają wprowadzanie typowych używanych wzorców kodu, takich jak konfigurowanie sesji platformy Spark, odczytywanie danych jako ramki danych Spark lub rysowanie wykresów z biblioteką matplotlib itp.
Fragmenty kodu są wyświetlane w klawiszach skrótów stylu IDE IntelliSense mieszanej z innymi sugestiami. Zawartość fragmentów kodu jest zgodna z językiem komórek kodu. Dostępne fragmenty kodu można wyświetlić, wpisując fragment kodu lub dowolne słowa kluczowe wyświetlane w tytule fragmentu kodu w edytorze komórek kodu. Na przykład, wpisując odczyt , możesz wyświetlić listę fragmentów kodu do odczytu danych z różnych źródeł danych.

Formatowanie komórki tekstowej za pomocą przycisków paska narzędzi
Za pomocą przycisków formatowania na pasku narzędzi komórek tekstowych można wykonywać typowe akcje markdown. Obejmuje ona pogrubienie tekstu, kursywę, akapit/nagłówki za pomocą listy rozwijanej, wstawianie kodu, wstawianie nieuporządkowanej listy, wstawianie uporządkowanej listy, wstawianie hiperlinku i wstawianie obrazu z adresu URL.
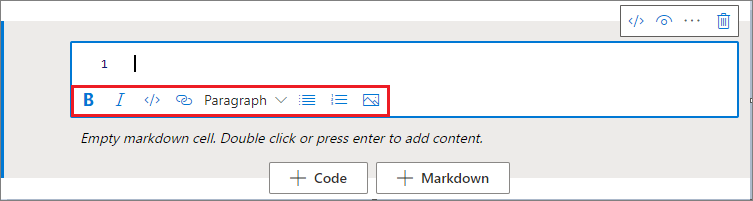
Cofnij/Wykonaj ponownie operację komórki
Wybierz przycisk Cofnij / ponownie lub naciśnij klawisze Z / Shift+Z , aby odwołać najnowsze operacje komórek. Teraz możesz cofnąć/ponownie wykonać maksymalnie 10 operacji historycznych komórek.

Obsługiwane operacje cofania komórek:
- Wstaw/Usuń komórkę: możesz odwołać operacje usuwania, wybierając pozycję Cofnij, zawartość tekstowa jest przechowywana wraz z komórką.
- Zmień kolejność komórki.
- Przełącz parametr.
- Konwertuj między komórką Code i komórką Markdown.
Uwaga
Operacje tekstowe w komórce i operacje komentowania komórek kodu nie są nieodwracalne. Teraz możesz cofnąć/ponownie wykonać maksymalnie 10 operacji historycznych komórek.
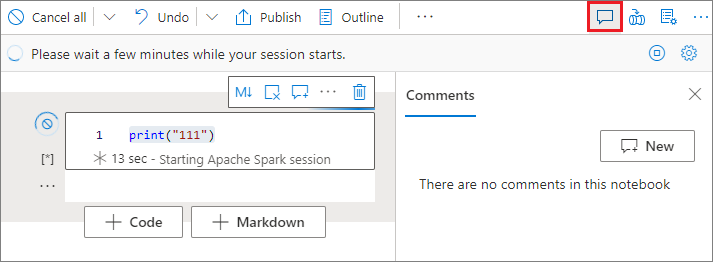
Komentowanie komórek kodu
Wybierz przycisk Komentarze na pasku narzędzi notesu, aby otworzyć okienko Komentarze .
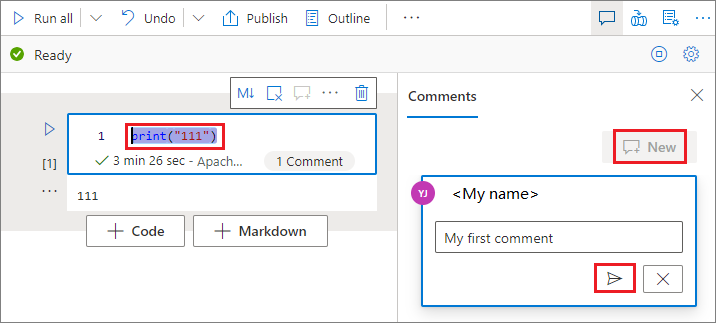
Wybierz kod w komórce kodu, kliknij pozycję Nowy w okienku Komentarze , dodaj komentarze, a następnie kliknij przycisk Opublikuj komentarz , aby zapisać.
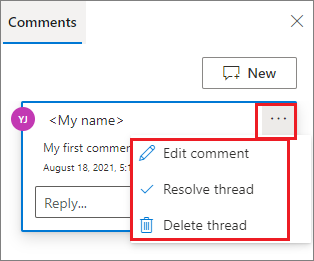
Możesz wykonać polecenie Edytuj komentarz, Rozwiązać wątek lub Usunąć wątek , klikając przycisk Więcej oprócz komentarza.
Przenoszenie komórki
Kliknij lewą stronę komórki i przeciągnij ją do żądanej pozycji.
Usuwanie komórki
Aby usunąć komórkę, wybierz przycisk usuń po prawej stronie komórki.
Możesz również użyć klawiszy skrótów w trybie polecenia. Naciśnij klawisze Shift+D , aby usunąć bieżącą komórkę.
Zwiń dane wejściowe komórki
Wybierz wielokropek Więcej poleceń (...) na pasku narzędzi komórki i Ukryj dane wejściowe , aby zwinąć dane wejściowe bieżącej komórki. Aby ją rozwinąć, wybierz pozycję Pokaż dane wejściowe , gdy komórka zostanie zwinięta.
Zwiń dane wyjściowe komórki
Wybierz wielokropek Więcej poleceń (...) na pasku narzędzi komórek i Ukryj dane wyjściowe , aby zwinąć dane wyjściowe bieżącej komórki. Aby ją rozwinąć, wybierz pozycję Pokaż dane wyjściowe , gdy dane wyjściowe komórki są ukryte.
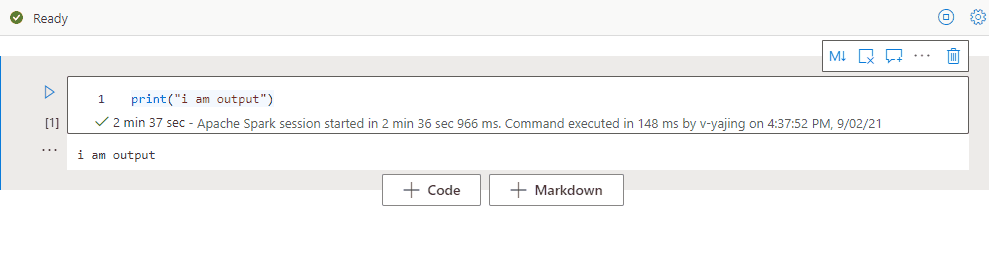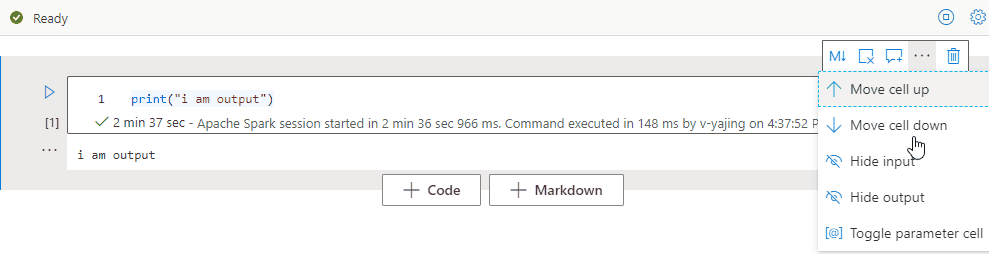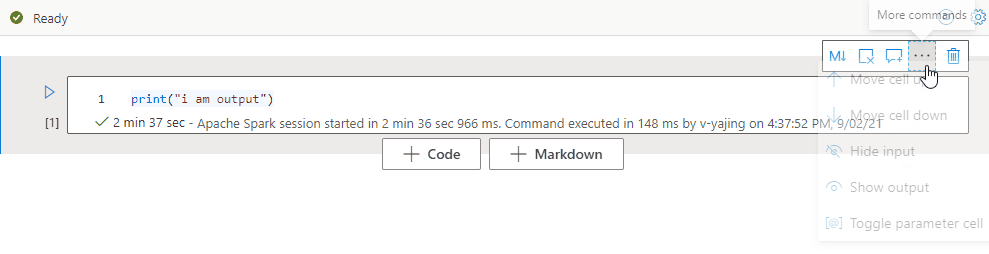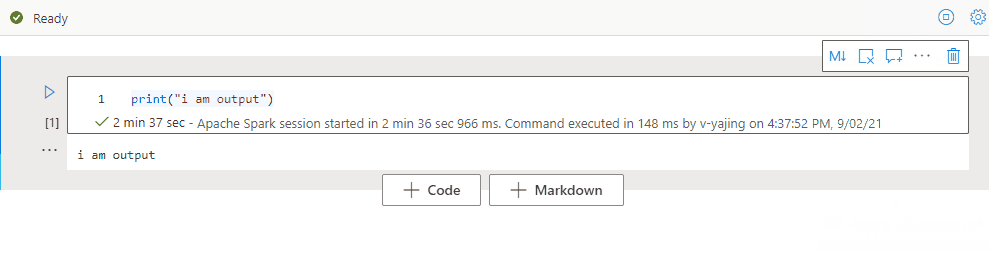
Konspekt notesu
Kontury (spis treści) przedstawia pierwszy nagłówek markdown dowolnej komórki markdown w oknie paska bocznego na potrzeby szybkiej nawigacji. Pasek boczny Kontury można zmienić rozmiar i zwijać, aby dopasować ekran w najlepszy możliwy sposób. Możesz wybrać przycisk Konspektu na pasku poleceń notesu, aby otworzyć lub ukryć pasek boczny
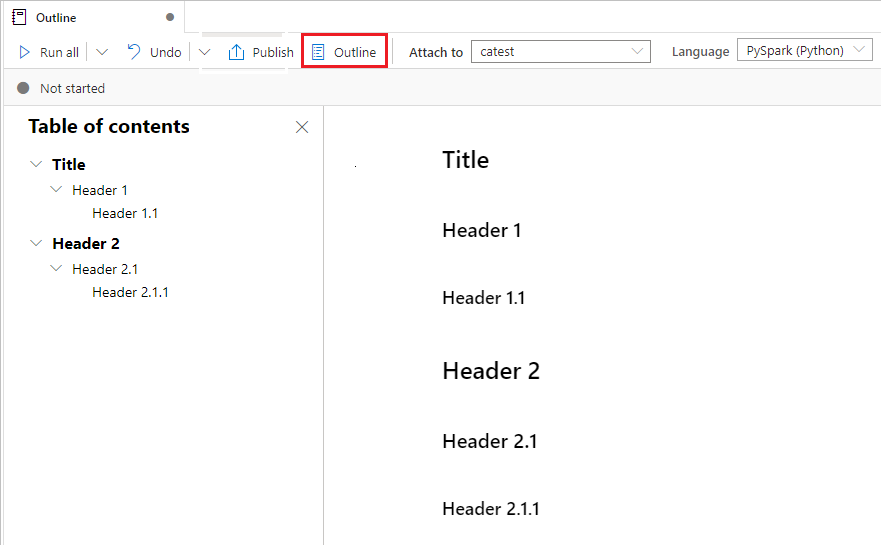
Uruchamianie notesów
Komórki kodu można uruchamiać pojedynczo lub jednocześnie w notesie. Stan i postęp każdej komórki są reprezentowane w notesie.
Uruchamianie komórki
Istnieje kilka sposobów uruchamiania kodu w komórce.
Umieść kursor na komórce, którą chcesz uruchomić, i wybierz przycisk Uruchom komórkę lub naciśnij klawisze Ctrl+Enter.

Użyj klawiszy skrótów w trybie polecenia. Naciśnij klawisze Shift+Enter , aby uruchomić bieżącą komórkę i wybrać komórkę poniżej. Naciśnij klawisze Alt+Enter , aby uruchomić bieżącą komórkę i wstawić nową komórkę poniżej.
Uruchamianie wszystkich komórek
Wybierz przycisk Uruchom wszystko , aby uruchomić wszystkie komórki w bieżącym notesie w sekwencji.

Uruchom wszystkie komórki powyżej lub poniżej
Rozwiń listę rozwijaną z przycisku Uruchom wszystkie , a następnie wybierz pozycję Uruchom komórki powyżej , aby uruchomić wszystkie komórki powyżej bieżącej sekwencji. Wybierz pozycję Uruchom komórki poniżej , aby uruchomić wszystkie komórki poniżej bieżącej sekwencji.
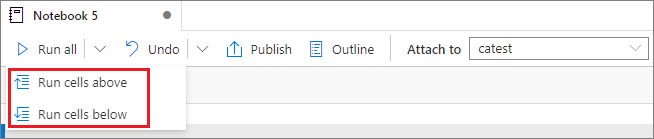
Anuluj wszystkie uruchomione komórki
Wybierz przycisk Anuluj wszystko , aby anulować uruchomione komórki lub komórki oczekujące w kolejce.

Dokumentacja notesu
Możesz użyć %run <notebook path> polecenia magic, aby odwołać się do innego notesu w kontekście bieżącego notesu. Wszystkie zmienne zdefiniowane w notesie referencyjnym są dostępne w bieżącym notesie. %run polecenie magic obsługuje zagnieżdżone wywołania, ale nie obsługuje wywołań cyklicznych. Otrzymasz wyjątek, jeśli głębokość instrukcji jest większa niż pięć.
Przykład: %run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
Odwołanie do notesu działa zarówno w trybie interaktywnym, jak i w potoku usługi Synapse.
Uwaga
%runPolecenie obecnie obsługuje tylko przekazywanie ścieżki bezwzględnej lub nazwy notesu tylko jako parametru, ścieżka względna nie jest obsługiwana.%runPolecenie obecnie obsługuje tylko 4 typy wartości parametrów:int, ,floatbool,stringoperacja zamiany zmiennej nie jest obsługiwana.- Wymagane jest opublikowanie odwołanych notesów. Musisz opublikować notesy, aby się do nich odwoływać, chyba że włączono odwołanie do nieopublikowanego notesu . Synapse Studio nie rozpoznaje nieopublikowanych notesów z repozytorium Git.
- Przywołyne notesy nie obsługują instrukcji, że głębokość jest większa niż pięć.
Eksplorator zmiennych
Notes usługi Synapse udostępnia wbudowanego eksploratora zmiennych, aby wyświetlić listę nazw zmiennych, typów, długości i wartości w bieżącej sesji platformy Spark dla komórek PySpark (Python). Więcej zmiennych jest wyświetlanych automatycznie w miarę ich definiowania w komórkach kodu. Kliknięcie każdego nagłówka kolumny sortuje zmienne w tabeli.
Możesz wybrać przycisk Zmienne na pasku poleceń notesu, aby otworzyć lub ukryć eksploratora zmiennych.
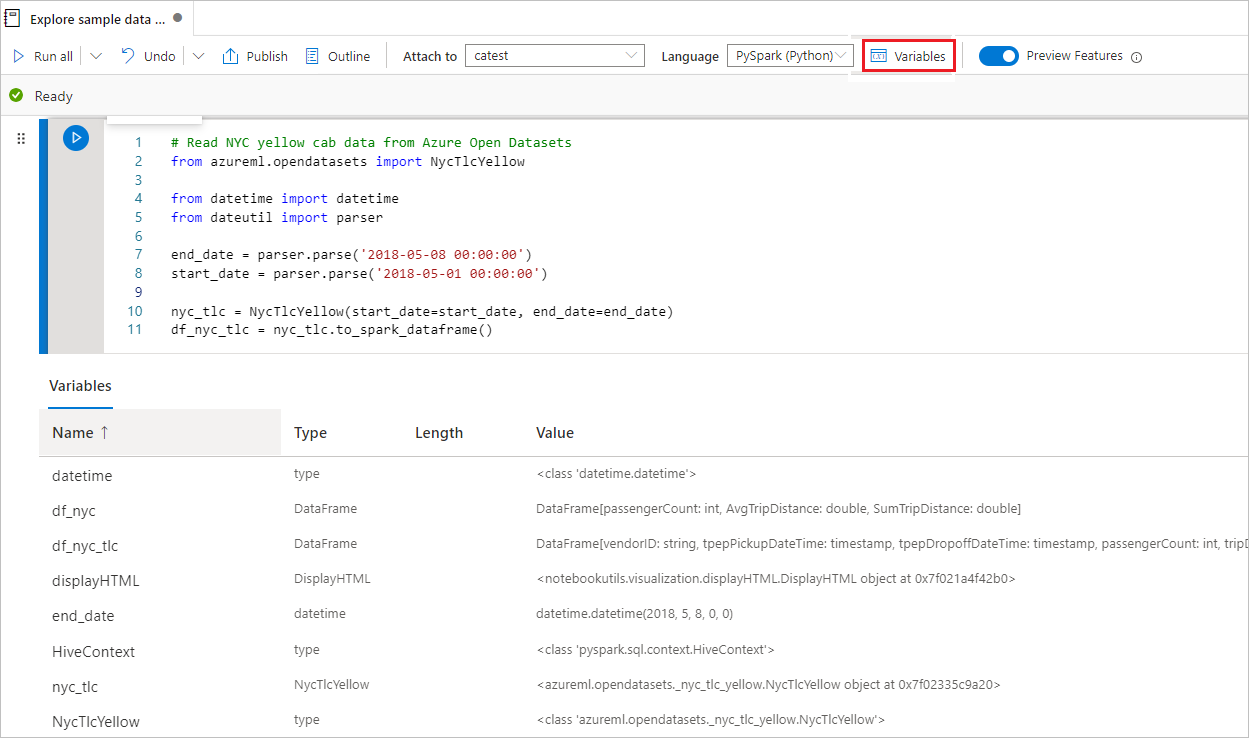
Uwaga
Eksplorator zmiennych obsługuje tylko język Python.
Wskaźnik stanu komórki
Stan wykonywania komórki krok po kroku jest wyświetlany pod komórką, aby ułatwić wyświetlenie bieżącego postępu. Po zakończeniu przebiegu komórki zostanie wyświetlone podsumowanie wykonania z łącznym czasem trwania i czasem zakończenia oraz przechowywane tam na potrzeby przyszłego odwołania.

Wskaźnik postępu platformy Spark
Notes usługi Synapse jest wyłącznie oparty na platformie Spark. Komórki kodu są wykonywane zdalnie w bezserwerowej puli platformy Apache Spark. Wskaźnik postępu zadania platformy Spark jest dostarczany z paskiem postępu w czasie rzeczywistym, który ułatwia zrozumienie stanu wykonywania zadania. Liczba zadań na każde zadanie lub etap ułatwiają zidentyfikowanie równoległego poziomu zadania platformy Spark. Możesz również dokładniej przejść do interfejsu użytkownika platformy Spark określonego zadania (lub etapu), wybierając link w nazwie zadania (lub etapu).
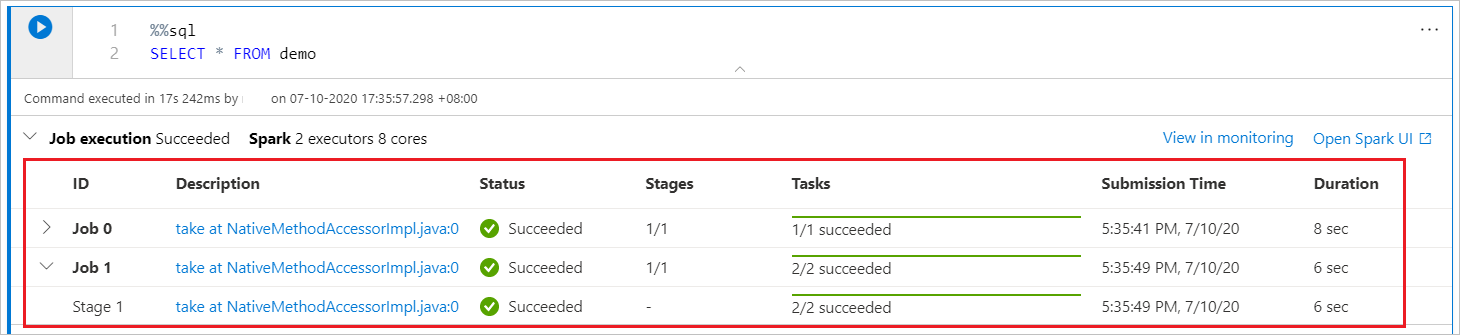
Konfiguracja sesji platformy Spark
Możesz określić czas trwania limitu czasu, liczbę i rozmiar funkcji wykonawczych, które mają być podane bieżącej sesji platformy Spark w temacie Konfigurowanie sesji. Uruchom ponownie sesję platformy Spark, aby zmiany konfiguracji zaczęły obowiązywać. Wszystkie buforowane zmienne notesu są wyczyszczone.
Konfigurację można również utworzyć na podstawie konfiguracji platformy Apache Spark lub wybrać istniejącą konfigurację. Aby uzyskać szczegółowe informacje, zobacz Zarządzanie konfiguracją platformy Apache Spark.

Polecenie magic konfiguracji sesji platformy Spark
Ustawienia sesji platformy Spark można również określić za pomocą polecenia magic %%configure. Aby wprowadzić efekt ustawień, sesja platformy Spark musi być ponownie uruchomiona. Zalecamy uruchomienie narzędzia %%configure na początku notesu. Oto przykład, zapoznaj się https://github.com/cloudera/livy#request-body z pełną listą prawidłowych parametrów.
%%configure
{
//You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of standard spark property, to find more available properties please visit:https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
Uwaga
- Zaleca się ustawienie wartości "DriverMemory" i "ExecutorMemory" jako tej samej wartości w konfiguracji %%, tak więc "driverCores" i "executorCores".
- Możesz użyć %%configure w potokach usługi Synapse, ale jeśli nie jest ona ustawiona w pierwszej komórce kodu, uruchomienie potoku zakończy się niepowodzeniem z powodu braku możliwości ponownego uruchomienia sesji.
- Konfiguracja %%skonfigurowana używana w pliku mssparkutils.notebook.run będzie ignorowana, ale używana w notesie %run będzie kontynuowana.
- Standardowe właściwości konfiguracji platformy Spark muszą być używane w treści "conf". Nie obsługujemy odwołania pierwszego poziomu dla właściwości konfiguracji platformy Spark.
- Niektóre specjalne właściwości platformy Spark, w tym "spark.driver.cores", "spark.executor.cores", "spark.driver.memory", "spark.executor.memory", "spark.executor.instances" nie będą obowiązywać w treści "conf".
Konfiguracja sparametryzowanej sesji z potoku
Konfiguracja sesji sparametryzowanej umożliwia zamianę wartości w %%configure magic za pomocą parametrów Przebiegu potoku (działanie notesu). Podczas przygotowywania komórki kodu %%configure można zastąpić wartości domyślne (również konfigurowalne, 4 i "2000" w poniższym przykładzie) z obiektem w następujący sposób:
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
Notes używa wartości domyślnej, jeśli uruchom notes w trybie interaktywnym bezpośrednio lub żaden parametr zgodny z parametrem "activityParameterName" jest podawany z działania notesu potoku.
W trybie uruchamiania potoku można skonfigurować ustawienia działania notesu potoku w następujący sposób: 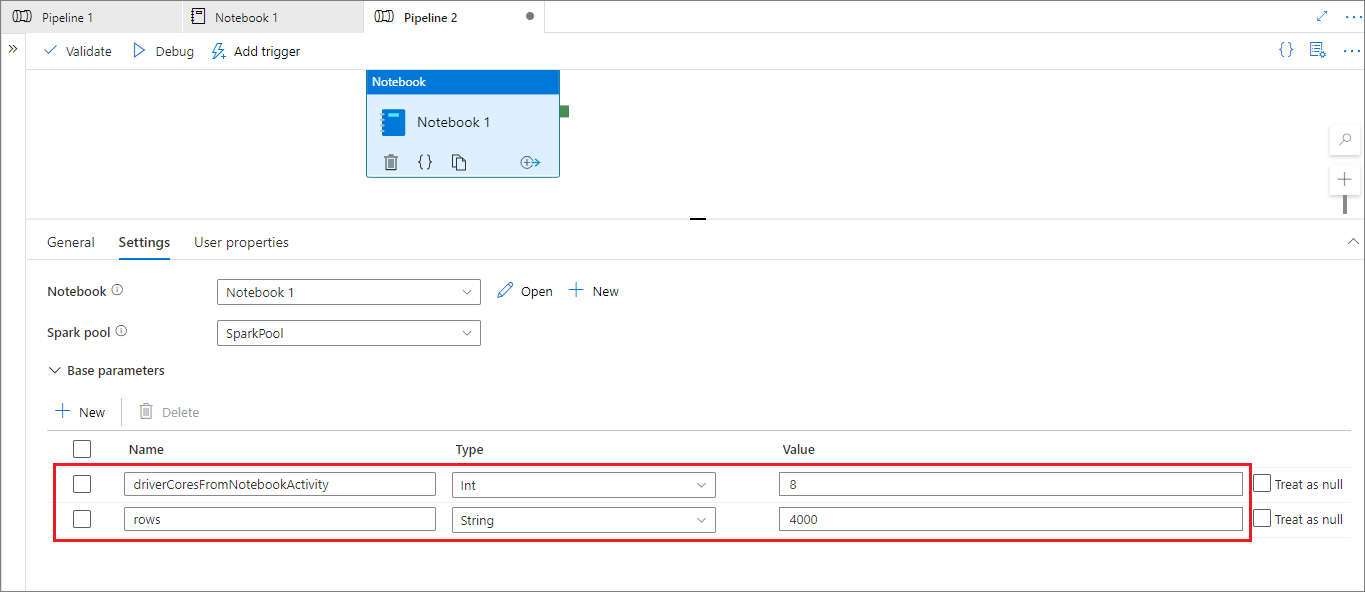
Jeśli chcesz zmienić konfigurację sesji, nazwa parametrów działania notesu potoku powinna być taka sama jak activityParameterName w notesie. Podczas uruchamiania tego potoku w tym przykładzie driverCores w konfiguracji %%configure zostanie zastąpiony przez 8, a wiersze livy.rsc.sql.num zostaną zastąpione przez 4000.
Uwaga
Jeśli potok uruchamiania nie powiódł się z powodu użycia tej nowej funkcji %%configure magic, możesz sprawdzić więcej informacji o błędzie, uruchamiając %%configure magic cell w trybie interaktywnym notesu.
Przenoszenie danych do notesu
Dane można załadować z Azure Blob Storage, usługi Azure Data Lake Store Gen 2 i puli SQL, jak pokazano w poniższych przykładach kodu.
Odczytywanie pliku CSV z usługi Azure Data Lake Store Gen2 jako ramki danych Platformy Spark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Odczytywanie pliku CSV z Azure Blob Storage jako ramki danych Platformy Spark
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
Odczytywanie danych z podstawowego konta magazynu
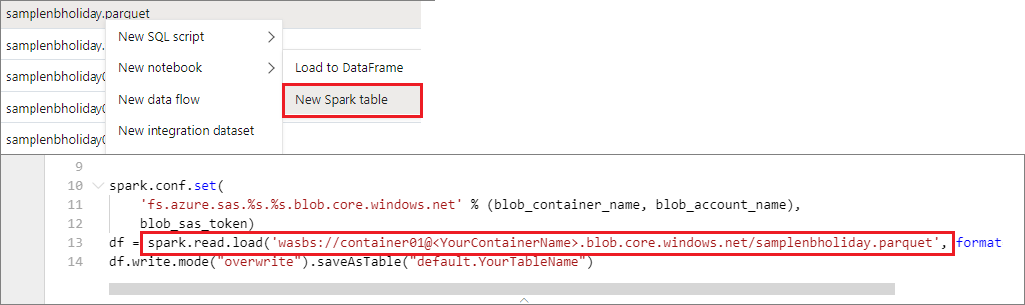
Dostęp do danych można uzyskać bezpośrednio na podstawowym koncie magazynu. Nie ma potrzeby udostępniania kluczy tajnych. W Data Explorer kliknij prawym przyciskiem myszy plik i wybierz pozycję Nowy notes, aby wyświetlić nowy notes z automatycznie wygenerowanym funkcją wyodrębniania danych.
Widżety IPython
Widżety to obiekty języka Python, które mają reprezentację w przeglądarce, często jako kontrolka, taka jak suwak, pole tekstowe itp. Widżety IPython działają tylko w środowisku języka Python, nie są jeszcze obsługiwane w innych językach (na przykład Scala, SQL, C#).
Aby użyć widżetu IPython
Najpierw należy zaimportować
ipywidgetsmoduł, aby użyć struktury widżetów Jupyter.import ipywidgets as widgetsMożesz użyć funkcji najwyższego poziomu
displaydo renderowania widżetu lub pozostawić wyrażenie typu widżetu w ostatnim wierszu komórki kodu.slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderUruchom komórkę, widżet zostanie wyświetlony w obszarze danych wyjściowych.
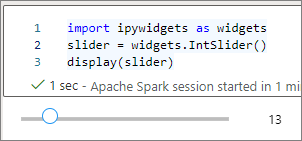
Można użyć wielu
display()wywołań do renderowania tego samego wystąpienia widżetu wiele razy, ale pozostają one zsynchronizowane ze sobą.slider = widgets.IntSlider() display(slider) display(slider)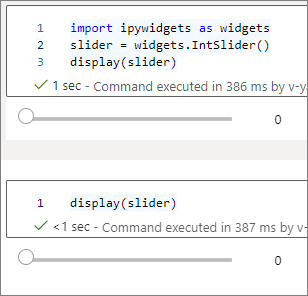
Aby renderować dwa widżety niezależnie od siebie, utwórz dwa wystąpienia widżetów:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)
Obsługiwane widżety
| Typ widżetów | Widżety |
|---|---|
| Widżety liczbowe | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Widżety logiczne | PrzełącznikButton, Pole wyboru, Prawidłowe |
| Widżety wyboru | Lista rozwijana, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| Widżety ciągów | Tekst, obszar tekstowy, pole kombi, hasło, etykieta, HTML, matematyka HTML, obraz, przycisk |
| Widżety odtwarzania (animacja) | Selektor dat, Selektor kolorów, Kontroler |
| Widżety kontenera/układu | Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Znane ograniczenia
Następujące widżety nie są jeszcze obsługiwane. Możesz wykonać odpowiednie obejście, jak pokazano poniżej:
Funkcjonalność Obejście OutputWidgetZamiast tego można użyć print()funkcji do zapisania tekstu w obiekcie stdout.widgets.jslink()Funkcji można użyć widgets.link()do łączenia dwóch podobnych widżetów.FileUploadWidgetNieobsługij jeszcze. Funkcja globalna
displayudostępniana przez usługę Synapse nie obsługuje wyświetlania wielu widżetów w jednym wywołaniu (czylidisplay(a, b)), co różni się od funkcji IPythondisplay.Jeśli zamkniesz notes zawierający widżet IPython, nie będzie można go zobaczyć ani wchodzić z nim w interakcję, dopóki nie zostanie ponownie wykonana odpowiednia komórka.
Zapisywanie notesów
Możesz zapisać jeden notes lub wszystkie notesy w obszarze roboczym.
Aby zapisać zmiany wprowadzone w jednym notesie, wybierz przycisk Publikuj na pasku poleceń notesu.

Aby zapisać wszystkie notesy w obszarze roboczym, wybierz przycisk Opublikuj wszystko na pasku poleceń obszaru roboczego.

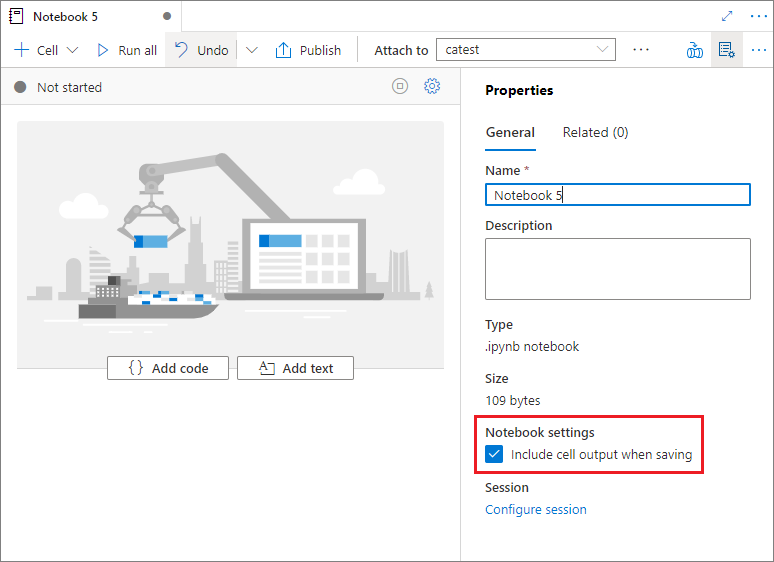
We właściwościach notesu można skonfigurować, czy podczas zapisywania mają być uwzględniane dane wyjściowe komórki.
Polecenia magiczne
W notesach usługi Synapse można używać znanych poleceń magicznych programu Jupyter. Przejrzyj poniższą listę jako bieżące dostępne polecenia magic. Poinformuj nas o swoich przypadkach użycia w usłudze GitHub , abyśmy mogli nadal tworzyć więcej poleceń magicznych, aby spełnić Twoje potrzeby.
Uwaga
W potoku usługi Synapse są obsługiwane tylko następujące polecenia magiczne: %%pyspark, %%spark, %%csharp, %%sql.
Dostępne magie wierszy: %lsmagic, %time, %timeit, %history, %run, %load
Dostępne magie komórek: %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
Odwołanie do nieopublikowanego notesu
Odwołanie do nieopublikowanego notesu jest przydatne, gdy chcesz debugować "lokalnie", podczas włączania tej funkcji uruchomienie notesu pobiera bieżącą zawartość w pamięci podręcznej sieci Web, jeśli uruchamiasz komórkę zawierającą instrukcję notesów referencyjnych, odwołujesz się do notesów prezentowanych w bieżącej przeglądarce notesów zamiast zapisanych wersji w klastrze, co oznacza, że zmiany w edytorze notesów można odwoływać się natychmiast przez inne notesy bez konieczności publikowania (tryb na żywo) lub zatwierdzenia( Tryb Git) dzięki wykorzystaniu tego podejścia można łatwo uniknąć zanieczyszczania popularnych bibliotek podczas opracowywania lub debugowania.
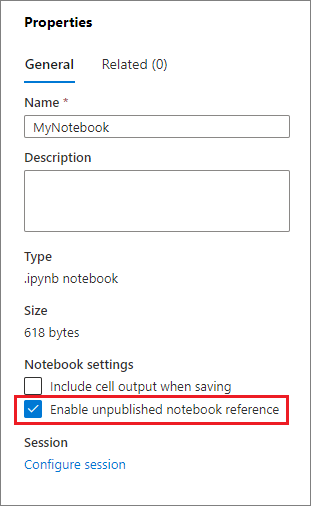
Możesz włączyć notes Odwołaj się do nieopublikowanego odwołania z panelu Właściwości:
W przypadku różnych przypadków porównania zapoznaj się z poniższą tabelą:
Zwróć uwagę, że polecenie %run i mssparkutils.notebook.run ma takie samo zachowanie tutaj. W tym miejscu użyto %run przykładu.
| Sprawa | Wyłącz | Włącz |
|---|---|---|
| Tryb na żywo | ||
- Nb1 (opublikowany)%run Nb1 |
Uruchamianie opublikowanej wersji Nb1 | Uruchamianie opublikowanej wersji Nb1 |
- Nb1 (nowy)%run Nb1 |
Błąd | Uruchamianie nowego Nb1 |
- Nb1 (wcześniej opublikowane, edytowane)%run Nb1 |
Uruchamianie opublikowanej wersji Nb1 | Uruchamianie edytowanej wersji Nb1 |
| Tryb Git | ||
- Nb1 (opublikowany)%run Nb1 |
Uruchamianie opublikowanej wersji Nb1 | Uruchamianie opublikowanej wersji Nb1 |
- Nb1 (nowy)%run Nb1 |
Błąd | Uruchamianie nowego Nb1 |
- Nb1 (Nie opublikowano, zatwierdzone)%run Nb1 |
Błąd | Uruchamianie zatwierdzonego Nb1 |
- Nb1 (wcześniej opublikowane, zatwierdzone)%run Nb1 |
Uruchamianie opublikowanej wersji Nb1 | Uruchamianie zatwierdzonej wersji Nb1 |
- Nb1 (wcześniej opublikowane, nowe w bieżącej gałęzi)%run Nb1 |
Uruchamianie opublikowanej wersji Nb1 | Uruchamianie nowego Nb1 |
- Nb1 (Nie opublikowano, wcześniej zatwierdzone, edytowane)%run Nb1 |
Błąd | Uruchamianie edytowanej wersji Nb1 |
- Nb1 (wcześniej opublikowane i zatwierdzone, edytowane)%run Nb1 |
Uruchamianie opublikowanej wersji Nb1 | Uruchamianie edytowanej wersji Nb1 |
Podsumowanie
- Jeśli to ustawienie jest wyłączone, zawsze uruchamiaj opublikowaną wersję.
- Jeśli to ustawienie jest włączone, priorytet to: edytowany/nowy > zatwierdzony > opublikowany.
Zarządzanie sesjami aktywnymi
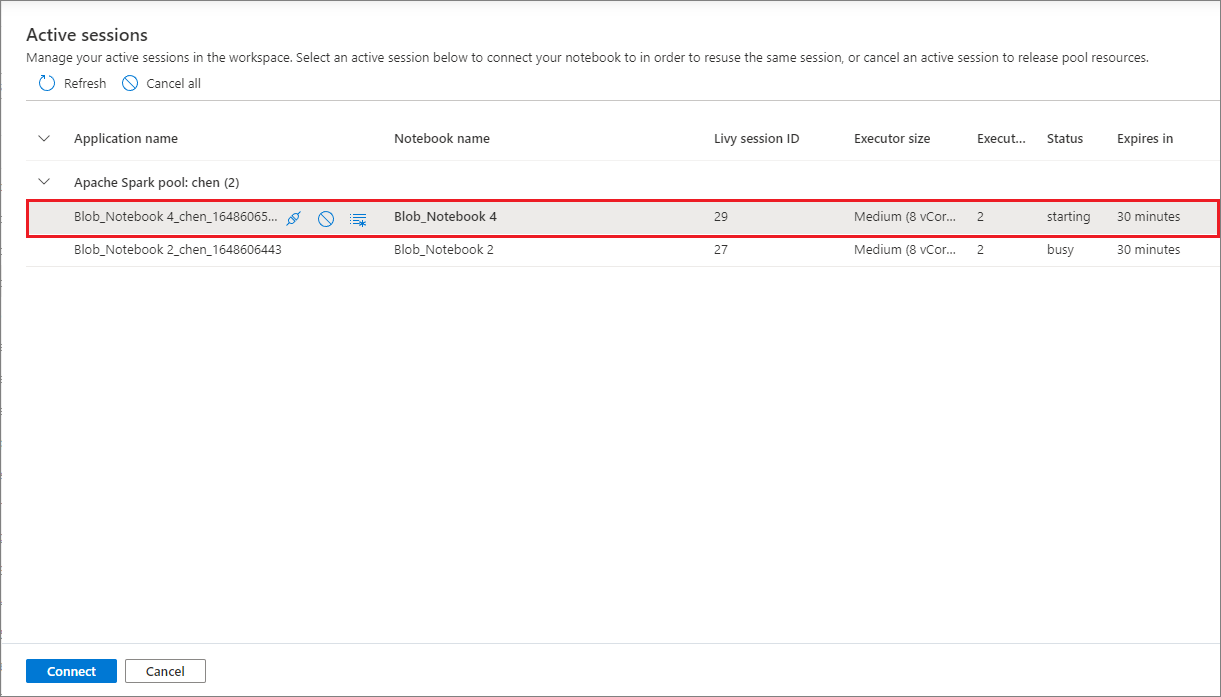
Sesje notesu można teraz wygodnie używać bez konieczności uruchamiania nowych. Notes usługi Synapse obsługuje teraz zarządzanie aktywnymi sesjami na liście Zarządzanie sesjami . Wszystkie sesje są widoczne w bieżącym obszarze roboczym uruchomionym przez Ciebie z poziomu notesu.
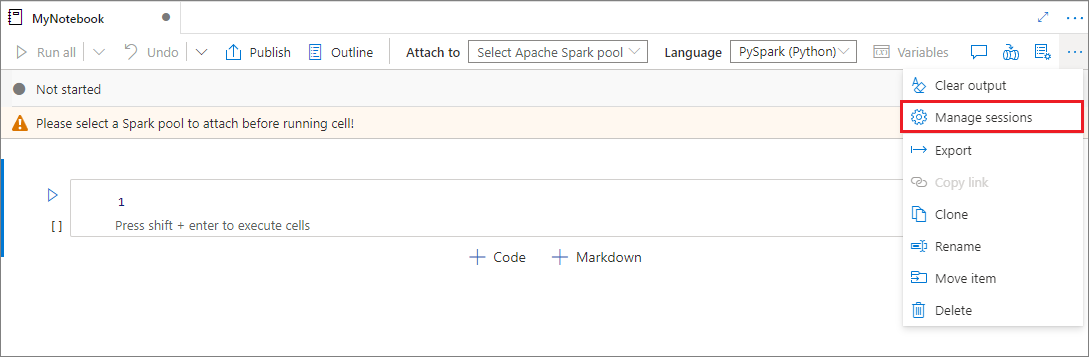
Na liście Aktywne sesje można wyświetlić informacje o sesji i odpowiedni notes, który jest obecnie dołączony do sesji. W tym miejscu możesz obsługiwać operacje Odłączanie za pomocą notesu, Zatrzymywanie sesji i Wyświetlanie w obszarze monitorowania. Ponadto możesz łatwo połączyć wybrany notes z aktywną sesją na liście uruchomioną z innego notesu, sesja jest odłączona od poprzedniego notesu (jeśli nie jest bezczynna), a następnie dołącz do bieżącego.
Rejestrowanie w języku Python w notesie
Dzienniki języka Python można znaleźć i ustawić różne poziomy dziennika oraz sformatować, postępując zgodnie z poniższym przykładowym kodem:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Integrowanie notesu
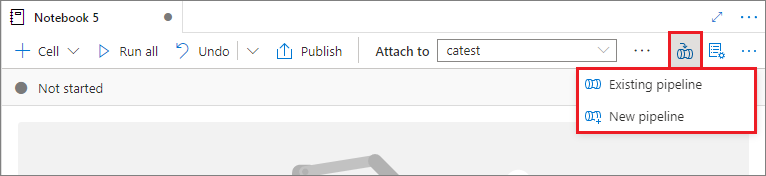
Dodawanie notesu do potoku
Wybierz przycisk Dodaj do potoku w prawym górnym rogu, aby dodać notes do istniejącego potoku lub utworzyć nowy potok.
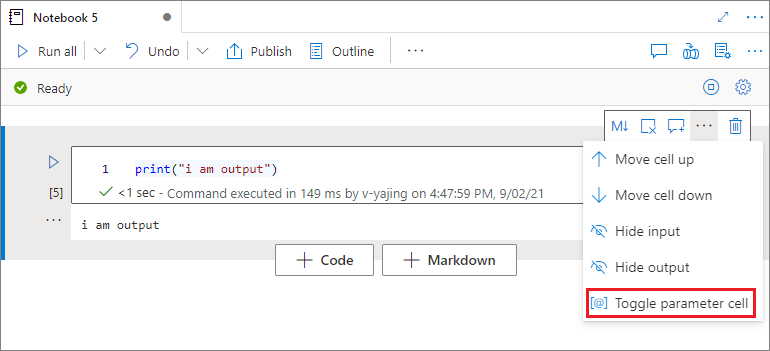
Wyznaczanie komórki parametrów
Aby sparametryzować notes, wybierz wielokropek (...) , aby uzyskać dostęp do większej liczby poleceń na pasku narzędzi komórki. Następnie wybierz pozycję Przełącz komórkę parametru , aby wyznaczyć komórkę jako komórkę parametrów.
Azure Data Factory wyszukuje komórkę parametrów i traktuje tę komórkę jako wartość domyślną parametrów przekazywanych w czasie wykonywania. Aparat wykonywania dodaje nową komórkę pod komórką parameters z parametrami wejściowymi, aby zastąpić wartości domyślne.
Przypisywanie wartości parametrów z potoku
Po utworzeniu notesu z parametrami możesz wykonać go z potoku za pomocą działania notesu usługi Synapse. Po dodaniu działania do kanwy potoku będzie można ustawić wartości parametrów w sekcji Podstawowe parametry na karcie Ustawienia .
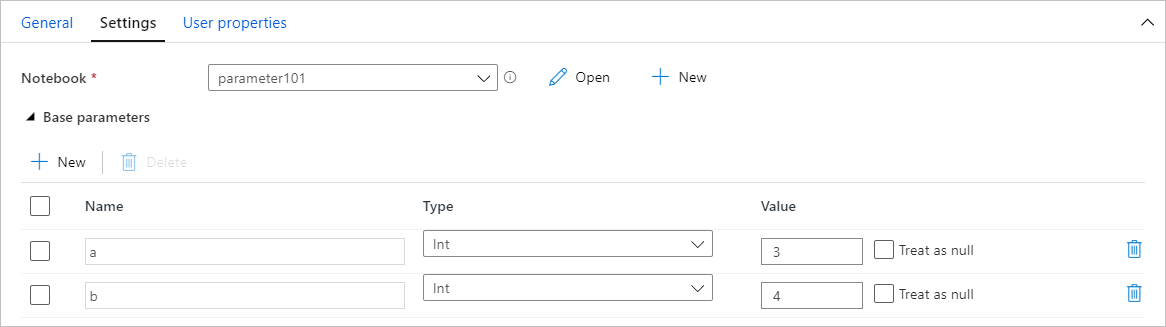
Podczas przypisywania wartości parametrów można użyć języka wyrażeń potoku lub zmiennych systemowych.
Klawisze skrótów
Podobnie jak w przypadku notesów Jupyter Notebook, notesy usługi Synapse mają modalny interfejs użytkownika. Klawiatura różni się w zależności od trybu, w którym znajduje się komórka notesu. Notesy usługi Synapse obsługują następujące dwa tryby dla danej komórki kodu: tryb polecenia i tryb edycji.
Komórka jest w trybie poleceń, gdy nie ma kursora tekstowego z monitem o wpisanie. Gdy komórka jest w trybie polecenia, możesz edytować notes jako całość, ale nie wpisywać ich w poszczególnych komórkach. Wprowadź tryb polecenia, naciskając
ESClub używając myszy, aby wybrać poza obszarem edytora komórki.
Tryb edycji jest wskazywany przez kursor tekstowy z monitem o wpisanie w obszarze edytora. Gdy komórka jest w trybie edycji, możesz wpisać w komórce. Wprowadź tryb edycji, naciskając
Enterlub używając myszy, aby wybrać obszar edytora komórki.
Klawisze skrótów w trybie polecenia
| Akcja | Skróty notesu usługi Synapse |
|---|---|
| Uruchom bieżącą komórkę i wybierz poniżej | Shift+Enter |
| Uruchom bieżącą komórkę i wstaw poniżej | Alt+Enter |
| Uruchamianie bieżącej komórki | Ctrl+Enter |
| Zaznacz komórkę powyżej | W górę |
| Wybierz komórkę poniżej | W dół |
| Wybierz poprzednią komórkę | K |
| Wybierz następną komórkę | J |
| Wstaw komórkę powyżej | A |
| Wstaw komórkę poniżej | B |
| Usuń zaznaczone komórki | Shift+D |
| Przełączanie do trybu edycji | Enter |
Klawisze skrótów w trybie edycji
Korzystając z poniższych skrótów klawiszowych, możesz łatwiej nawigować i uruchamiać kod w notesach usługi Synapse w trybie edycji.
| Akcja | Skróty notesu usługi Synapse |
|---|---|
| Przenieś kursor w górę | W górę |
| Przenieś kursor w dół | W dół |
| Cofnij | Ctrl + Z |
| Ponów | Ctrl + Y |
| Komentarz/komentarz | Ctrl + / |
| Usuń wyraz przed | Ctrl + Backspace |
| Usuń wyraz po | Ctrl + Delete |
| Przejdź do początku komórki | Ctrl + Strona główna |
| Przejdź do końca komórki | Ctrl + Koniec |
| Przejdź do jednego wyrazu w lewo | Ctrl + Lewa |
| Przejdź do jednego słowa w prawo | Ctrl + Prawy |
| Zaznacz wszystko | Ctrl + A |
| Wcięcie | Ctrl +] |
| Wcięcie | Ctrl + [ |
| Przełączanie do trybu poleceń | Esc |
Następne kroki
- Zapoznaj się z przykładowymi notesami usługi Synapse
- Szybki start: tworzenie puli platformy Apache Spark w usłudze Azure Synapse Analytics przy użyciu narzędzi internetowych
- Co to jest platforma Apache Spark w usłudze Azure Synapse Analytics
- Korzystanie z platformy .NET for Apache Spark z usługą Azure Synapse Analytics
- Dokumentacja platformy .NET dla platformy Apache Spark
- Azure Synapse Analytics