Proces potoków wdrażania
Proces wdrażania umożliwia klonowanie zawartości z jednego etapu w potoku wdrażania do innego, zazwyczaj od programowania do testowania i od testowania do środowiska produkcyjnego.
Podczas wdrażania usługa Microsoft Fabric kopiuje zawartość z bieżącego etapu do elementu docelowego. Połączenia między skopiowanymi elementami są zachowywane podczas procesu kopiowania. Sieć szkieletowa stosuje również skonfigurowane reguły wdrażania do zaktualizowanej zawartości na etapie docelowym. Wdrażanie zawartości może zająć trochę czasu, w zależności od liczby wdrażanych elementów. W tym czasie możesz przejść do innych stron w portalu, ale nie możesz używać zawartości na etapie docelowym.
Zawartość można również wdrożyć programowo przy użyciu interfejsów API REST potoków wdrażania. Więcej informacji na temat tego procesu można znaleźć w temacie Automate your deployment pipeline using APIs and DevOps (Automatyzowanie potoku wdrażania przy użyciu interfejsów API i metodyki DevOps).
Wdrażanie zawartości na pustym etapie
Podczas wdrażania zawartości na pustym etapie nowy obszar roboczy jest tworzony w pojemności dla etapu, w którym wdrażasz. Wszystkie metadane w raportach, pulpitach nawigacyjnych i semantycznych modelach oryginalnego obszaru roboczego są kopiowane do nowego obszaru roboczego na etapie wdrażania.
Istnieje kilka sposobów wdrażania zawartości z jednego etapu do innego. Możesz wdrożyć całą zawartość lub wybrać elementy do wdrożenia.
Zawartość można również wdrożyć do tyłu z późniejszego etapu w potoku wdrażania do wcześniejszego.
Po zakończeniu wdrażania odśwież modele semantyczne, aby można było użyć nowo skopiowanych zawartości. Odświeżanie modelu semantycznego jest wymagane, ponieważ dane nie są kopiowane z jednego etapu do innego. Aby dowiedzieć się, które właściwości elementu są kopiowane podczas procesu wdrażania i które właściwości elementu nie są kopiowane, przejrzyj właściwości elementu skopiowane podczas wdrażania .
Tworzenie obszaru roboczego
Podczas pierwszego wdrażania zawartości potoki wdrażania sprawdzają, czy masz uprawnienia.
Jeśli masz uprawnienia, zawartość obszaru roboczego zostanie skopiowana do etapu, w którym wdrażasz, a nowy obszar roboczy dla tego etapu zostanie utworzony w pojemności.
Jeśli nie masz uprawnień, obszar roboczy zostanie utworzony, ale zawartość nie zostanie skopiowana. Możesz poprosić administratora pojemności o dodanie obszaru roboczego do pojemności lub poprosić o uprawnienia do przypisania pojemności. Później, gdy obszar roboczy zostanie przypisany do pojemności, możesz wdrożyć zawartość w tym obszarze roboczym.
Jeśli używasz warstwy Premium na użytkownika (PPU), obszar roboczy jest automatycznie skojarzony z twoją jednostki PPU. W takich przypadkach uprawnienia nie są wymagane. Jeśli jednak utworzysz obszar roboczy z ppu, tylko inni użytkownicy PPU będą mogli uzyskać do niego dostęp. Ponadto tylko użytkownicy PPU mogą korzystać z zawartości utworzonej w takich obszarach roboczych.
Użytkownik wdrażający automatycznie staje się właścicielem sklonowanych modeli semantycznych i jedynym administratorem nowego obszaru roboczego.
Wdrażanie zawartości w istniejącym obszarze roboczym
Wdrażanie zawartości z roboczego potoku produkcyjnego do etapu, który ma istniejący obszar roboczy, obejmuje następujące kroki:
Wdrażanie nowej zawartości jako dodatku do zawartości już tam.
Wdrażanie zaktualizowanej zawartości w celu zastąpienia części zawartości już tam.
Proces wdrażania
Gdy zawartość z bieżącego etapu jest kopiowana do etapu docelowego, sieć szkieletowa identyfikuje istniejącą zawartość na etapie docelowym i zastępuje ją. Aby określić, który element zawartości należy zastąpić, potoki wdrażania używają połączenia między elementem nadrzędnym a jego klonami. To połączenie jest zachowywane podczas tworzenia nowej zawartości. Operacja zastępowania zastępuje tylko zawartość elementu. Identyfikator, adres URL i uprawnienia elementu pozostają niezmienione.
Na etapie docelowym właściwości elementu, które nie są kopiowane, pozostają tak jak przed wdrożeniem. Nowa zawartość i nowe elementy są kopiowane z bieżącego etapu do etapu docelowego.
Automatyczne łączenie
W obszarze Sieć szkieletowa, gdy elementy są połączone, jeden z elementów zależy od drugiego. Na przykład raport zawsze zależy od modelu semantycznego, z który jest połączony. Model semantyczny może zależeć od innego modelu semantycznego i może być również połączony z kilkoma raportami, które od niego zależą. Jeśli istnieje połączenie między dwoma elementami, potoki wdrażania zawsze próbują zachować to połączenie.
Podczas wdrażania potoki wdrażania sprawdzają zależności. Wdrożenie zakończy się powodzeniem lub niepowodzeniem, w zależności od lokalizacji elementu, który dostarcza dane, od których zależy wdrożony element.
Element połączony istnieje na etapie docelowym — potoki wdrażania automatycznie łączą wdrożony element z elementem, który zależy od wdrożonego etapu. Jeśli na przykład wdrożysz raport podzielony na strony z programowania do testowania i jest połączony z modelem semantycznym, który został wcześniej wdrożony na etapie testowania, automatycznie łączy się z tym modelem semantycznym.
Element połączony nie istnieje na etapie docelowym — potoki wdrażania kończą się niepowodzeniem, jeśli element ma zależność od innego elementu, a element dostarczający dane nie jest wdrożony i nie znajduje się na etapie docelowym. Jeśli na przykład wdrożysz raport z programowania do testowania, a etap testu nie zawiera jego modelu semantycznego, wdrożenie zakończy się niepowodzeniem. Aby uniknąć nieudanych wdrożeń z powodu braku wdrożeń elementów zależnych, użyj przycisku Wybierz powiązane . Wybranie pozycji Powiązane automatycznie wybiera wszystkie powiązane elementy, które zapewniają zależności do elementów, które mają zostać wdrożone.
Automatyczne łączenie działa tylko z elementami obsługiwanymi przez potoki wdrażania i znajdują się w sieci szkieletowej. Aby wyświetlić zależności elementu, w menu Więcej opcji elementu wybierz pozycję Wyświetl pochodzenie.
Automatyczne łączenie między potokami
Potoki wdrażania automatycznie powiążą elementy połączone między potokami, jeśli znajdują się one na tym samym etapie potoku. Podczas wdrażania takich elementów potoki wdrażania próbują ustanowić nowe połączenie między wdrożonym elementem a elementem, z którym jest połączony w innym potoku. Jeśli na przykład masz raport na etapie testowania potoku A połączony z modelem semantycznym na etapie testowania potoku B, potoki wdrażania rozpoznają to połączenie.
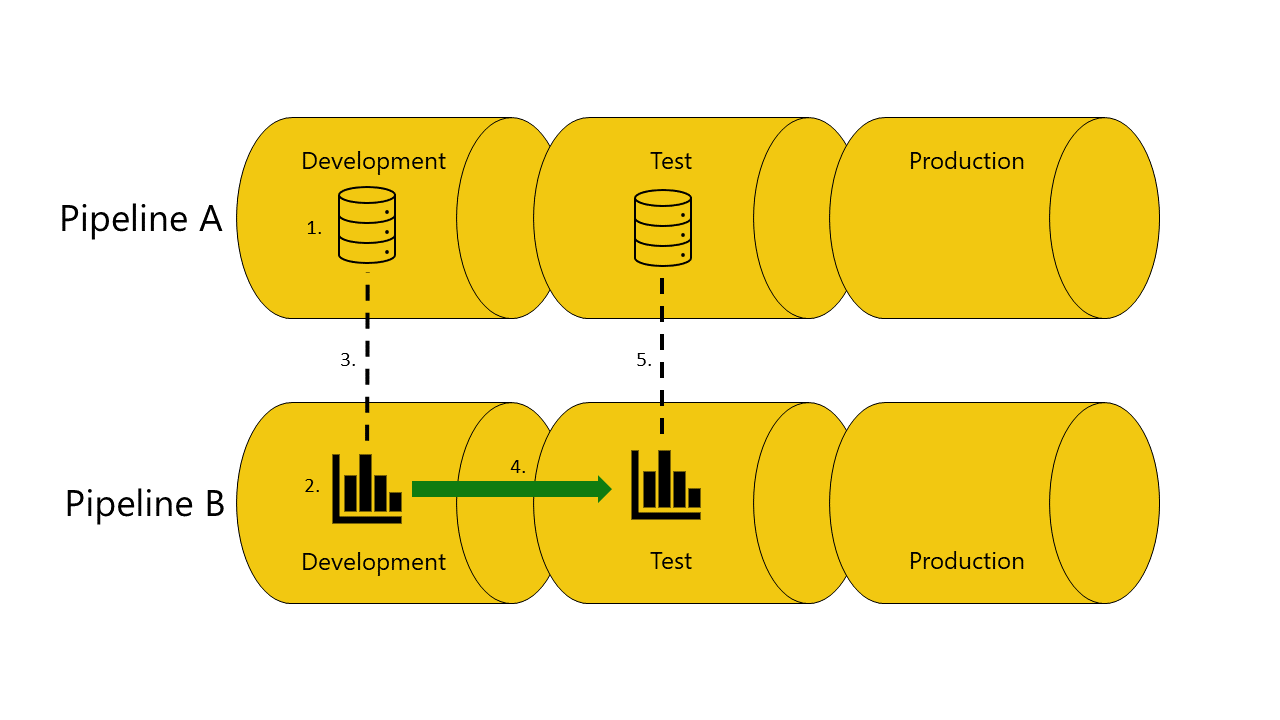
Oto przykład z ilustracjami, które ułatwiają pokazanie, jak działa automatyczne łączenie między potokami:
Masz semantyczny model na etapie programowania potoku A.
Raport jest również dostępny na etapie programowania potoku B.
Raport w potoku B jest połączony z modelem semantycznym w potoku A. Raport zależy od tego semantycznego modelu.
Raport jest wdrażany w potoku B z etapu programowania do etapu testowania.
Wdrożenie kończy się powodzeniem lub niepowodzeniem w zależności od tego, czy masz kopię modelu semantycznego, od którego zależy etap testu potoku A:
Jeśli masz kopię modelu semantycznego, raport zależy od etapu testowania potoku A:
Wdrożenie powiedzie się, a potoki wdrażania łączą (automatycznie) raport w etapie testowania potoku B z modelem semantycznym na etapie testowania potoku A.
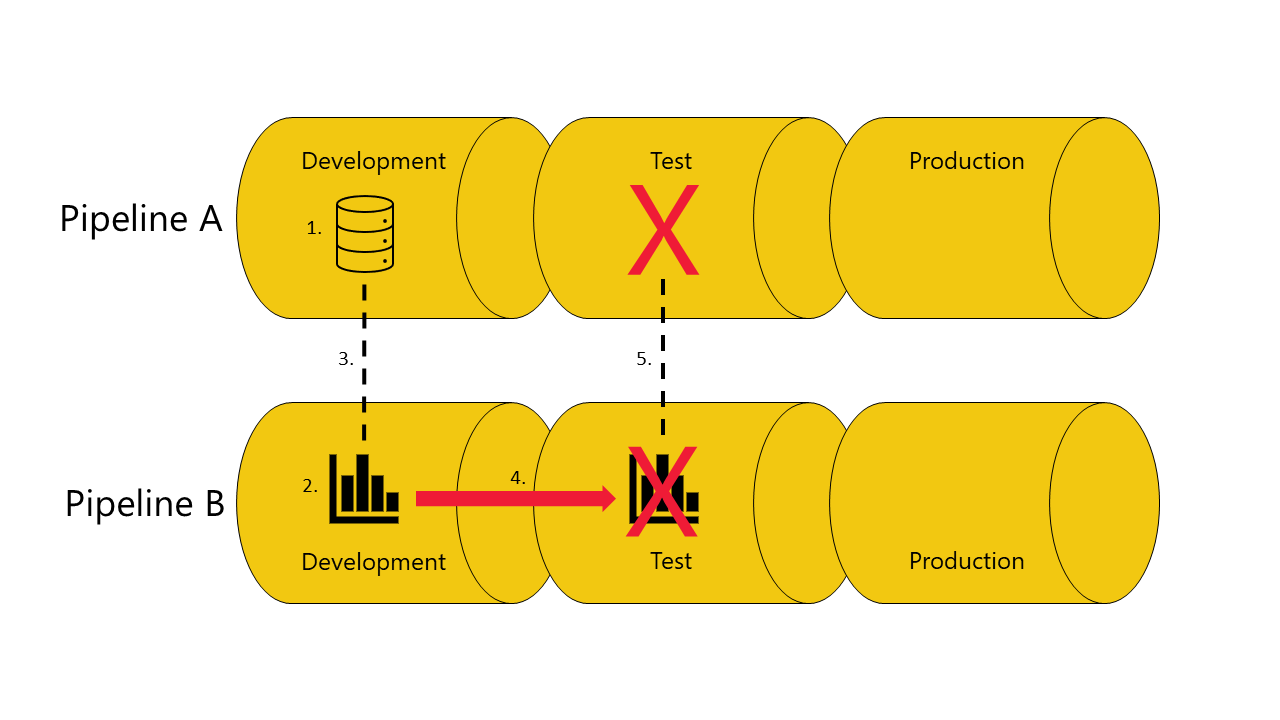
Jeśli nie masz kopii modelu semantycznego, raport zależy od etapu testu potoku A:
Wdrożenie kończy się niepowodzeniem, ponieważ potoki wdrażania nie mogą łączyć (automatycznie) raportu w etapie testowania w potoku B, z modelem semantycznym, od których zależy na etapie testowania potoku A.
Unikaj używania automatycznego łączenia
W niektórych przypadkach możesz nie chcieć używać automatycznego łączenia. Jeśli na przykład masz jeden potok do tworzenia modeli semantycznych organizacji, a drugi do tworzenia raportów. W takim przypadku możesz chcieć, aby wszystkie raporty były zawsze połączone z modelami semantycznymi na etapie produkcyjnym potoku, do którego należą. Aby to osiągnąć, należy unikać używania funkcji automatycznego łączenia.
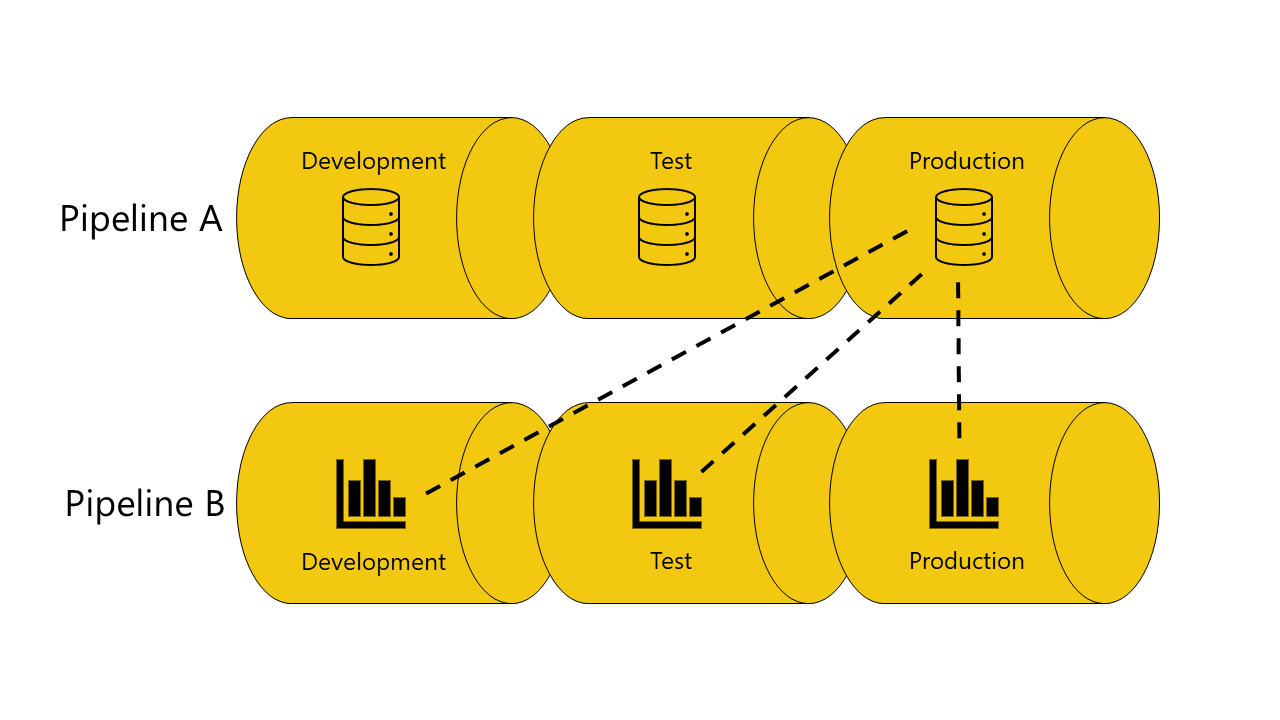
Istnieją trzy metody, których można użyć, aby uniknąć używania automatycznego łączenia:
Nie należy łączyć elementu z odpowiednimi etapami. Gdy elementy nie są połączone na tym samym etapie, potoki wdrażania utrzymują oryginalne połączenie. Jeśli na przykład masz raport na etapie programowania potoku B, który jest połączony z modelem semantycznym na etapie produkcyjnym potoku A. Podczas wdrażania raportu na etapie testowania potoku B pozostaje on połączony z modelem semantycznym na etapie produkcyjnym potoku A.
Zdefiniuj regułę parametru. Ta opcja nie jest dostępna dla raportów. Można go używać tylko z semantycznymi modelami i przepływami danych.
Połączenie raportów, pulpitów nawigacyjnych i kafelków do semantycznego modelu serwera proxy lub przepływu danych, który nie jest połączony z potokiem.
Autobindowanie i parametry
Parametry mogą służyć do kontrolowania połączeń między modelami semantycznymi lub przepływami danych a elementami, od których zależą. Gdy parametr kontroluje połączenie, automatyczne powiązanie po wdrożeniu nie zostanie wykonane, nawet jeśli połączenie zawiera parametr, który ma zastosowanie do identyfikatora modelu semantycznego lub przepływu danych lub identyfikatora obszaru roboczego. W takich przypadkach należy ponownie połączyć elementy po wdrożeniu, zmieniając wartość parametru lub używając reguł parametrów.
Uwaga
Jeśli używasz reguł parametrów do ponownego powiązania elementów, parametry muszą być typu Text.
Odświeżanie danych
Dane w elemencie docelowym, takie jak semantyczny model lub przepływ danych, są przechowywane, gdy jest to możliwe. Jeśli nie ma żadnych zmian w elemencie, który przechowuje dane, dane są przechowywane tak jak przed wdrożeniem.
W wielu przypadkach, gdy masz niewielką zmianę, taką jak dodawanie lub usuwanie tabeli, sieć szkieletowa przechowuje oryginalne dane. W przypadku zmian schematu powodującego niezgodność lub zmian w połączeniu ze źródłem danych wymagane jest pełne odświeżenie.
Wymagania dotyczące wdrażania na etapie z istniejącym obszarem roboczym
Każdy licencjonowany użytkownik będący członkiem obszarów roboczych wdrożenia docelowego i źródłowego może wdrożyć zawartość, która znajduje się w pojemności na etapie z istniejącym obszarem roboczym. Aby uzyskać więcej informacji, zapoznaj się z sekcją uprawnień .
Foldery w potokach wdrażania (wersja zapoznawcza)
Foldery w obszarze roboczym umożliwiają użytkownikom efektywne organizowanie elementów obszaru roboczego i zarządzanie nimi w znany sposób. Podczas wdrażania zawartości zawierającej foldery na innym etapie automatycznie jest stosowana hierarchia folderów zastosowanych elementów.
Reprezentacja folderów
Ponieważ wdrożenie zawiera tylko elementy, zawartość obszaru roboczego jest wyświetlana w potokach wdrażania jako płaska lista elementów. Pełna ścieżka elementu jest wyświetlana po umieszczeniu wskaźnika myszy na jego nazwie na liście. W obszarze Potoki wdrażania foldery są uznawane za część nazwy elementu (nazwa elementu zawiera pełną ścieżkę). Po wdrożeniu elementu po zmianie ścieżki (na przykład przeniesionej z folderu A do folderu B), potoki wdrażania stosują tę zmianę do sparowanego elementu podczas wdrażania — sparowany element zostanie przeniesiony również do folderu B. Jeśli folder B nie istnieje na etapie wdrażania, zostanie on najpierw utworzony w obszarze roboczym. Foldery można wyświetlać i zarządzać tylko na stronie obszaru roboczego.
Identyfikowanie elementów przeniesionych do różnych folderów
Ponieważ foldery są uznawane za część nazwy elementu, elementy przeniesione do innego folderu w obszarze roboczym są identyfikowane na stronie Potoki wdrażania jako Różne w trybie porównywania . Ponadto, chyba że istnieje również zmiana schematu, opcja obok etykiety w celu otwarcia okna Przegląd zmian , które przedstawia zmiany schematu, jest wyłączona. Umieszczenie kursora na nim spowoduje wyświetlenie notatki z informacją, że zmiana jest zmianą ustawień (na przykład zmiana nazwy). Wynika to z faktu, że w porównaniu z sparowanymi elementami na etapie źródłowym zmiana nie została jeszcze wdrożona.
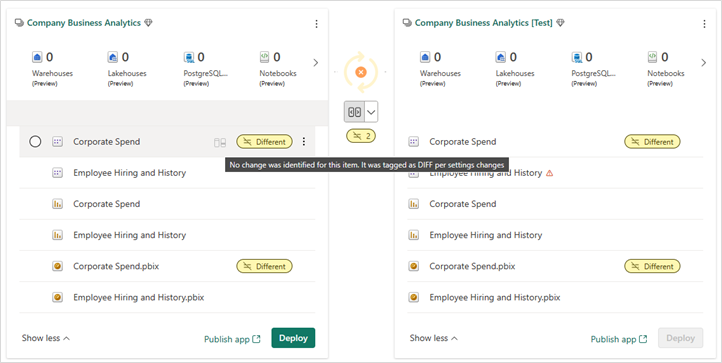
Nie można wdrażać poszczególnych folderów ręcznie w potokach wdrażania. Wdrożenie jest wyzwalane automatycznie po wdrożeniu co najmniej jednego z elementów.
Hierarchia folderów sparowanych elementów jest aktualizowana tylko podczas wdrażania. Podczas przypisywania po procesie parowania hierarchia sparowanych elementów nie jest jeszcze aktualizowana.
Ponieważ folder jest wdrażany tylko w przypadku wdrożenia jednego z jego elementów, nie można wdrożyć pustego folderu.
Wdrożenie jednego elementu z kilku w folderze aktualizuje również strukturę elementów, które nie są wdrażane na etapie docelowym, mimo że same elementy nie są wdrażane.
Obsługiwane elementy
Podczas wdrażania zawartości z jednego etapu potoku do innego skopiowana zawartość może zawierać następujące elementy:
- Potoki danych
- Przepływy danych Gen1
- Magazyny danych
- Lakehouse
- Notesy
- Raporty podzielone na strony
- Raporty (oparte na obsługiwanych modelach semantycznych)
- Modele semantyczne (z wyjątkiem modeli semantycznych usługi Direct Lake)
- Magazyny
Właściwości elementu skopiowane podczas wdrażania
Podczas wdrażania następujące właściwości elementu są kopiowane i zastępowane właściwości elementu na etapie docelowym:
Źródła danych (obsługiwane są reguły wdrażania)
Parametry (obsługiwane są reguły wdrażania)
Wizualizacje raportów
Strony raportu
Kafelki pulpitu nawigacyjnego
Metadane modelu
Relacje elementów
Etykiety poufności są kopiowane tylko wtedy, gdy zostanie spełniony jeden z następujących warunków. Jeśli te warunki nie zostaną spełnione, etykiety poufności nie zostaną skopiowane podczas wdrażania.
Nowy element jest wdrażany lub istniejący element jest wdrażany na pustym etapie.
Uwaga
W przypadkach, gdy domyślne etykietowanie jest włączone w dzierżawie, a etykieta domyślna jest prawidłowa, jeśli wdrażany element jest modelem semantycznym lub przepływem danych, etykieta zostanie skopiowana z elementu źródłowego tylko wtedy, gdy etykieta ma ochronę. Jeśli etykieta nie jest chroniona, domyślna etykieta zostanie zastosowana do nowo utworzonego docelowego modelu lub przepływu danych.
Element źródłowy ma etykietę z ochroną, a element docelowy nie. W takich przypadkach zostanie wyświetlone okno podręczne z prośbą o zgodę na zastąpienie docelowej etykiety poufności.
Właściwości elementu, które nie są kopiowane
Następujące właściwości elementu nie są kopiowane podczas wdrażania:
Dane — dane nie są kopiowane. Kopiowane są tylko metadane
URL
ID
Uprawnienia — dla obszaru roboczego lub określonego elementu
Ustawienia obszaru roboczego — każdy etap ma własny obszar roboczy
Zawartość i ustawienia aplikacji — aby zaktualizować aplikacje, zobacz Aktualizowanie zawartości w aplikacjach usługi Power BI
Następujące właściwości modelu semantycznego nie są również kopiowane podczas wdrażania:
Przypisanie roli
Harmonogram odświeżania
Poświadczenia źródła danych
Ustawienia buforowania zapytań (można dziedziczyć z pojemności)
Ustawienia poręczenia
Obsługiwane funkcje modelu semantycznego
Potoki wdrażania obsługują wiele funkcji modelu semantycznego. W tej sekcji wymieniono dwie funkcje modelu semantycznego, które mogą zwiększyć środowisko potoków wdrażania:
Odświeżanie przyrostowe
Potoki wdrażania obsługują odświeżanie przyrostowe, funkcję, która umożliwia szybsze i bardziej niezawodne odświeżanie dużych modeli semantycznych przy mniejszym użyciu.
Potoki wdrażania umożliwiają aktualizowanie modelu semantycznego z odświeżaniem przyrostowym przy zachowaniu zarówno danych, jak i partycji. Podczas wdrażania modelu semantycznego zasady są kopiowane.
Aby dowiedzieć się, jak odświeżanie przyrostowe zachowuje się w przypadku przepływów danych, zobacz, dlaczego widzę dwa źródła danych połączone z przepływem danych po użyciu reguł przepływu danych?
Aktywowanie odświeżania przyrostowego w potoku
Aby włączyć odświeżanie przyrostowe, skonfiguruj je w programie Power BI Desktop, a następnie opublikuj model semantyczny. Po opublikowaniu zasady odświeżania przyrostowego są podobne w potoku i mogą być tworzone tylko w programie Power BI Desktop.
Po skonfigurowaniu potoku przy użyciu odświeżania przyrostowego zalecamy użycie następującego przepływu:
Wprowadź zmiany w pliku pbix w programie Power BI Desktop. Aby uniknąć długich czasów oczekiwania, możesz wprowadzić zmiany przy użyciu próbki danych.
Przekaż plik pbix do pierwszego etapu (zwykle programowania).
Wdróż zawartość na następnym etapie. Po wdrożeniu wprowadzone zmiany zostaną zastosowane do całego używanego modelu semantycznego.
Przejrzyj zmiany wprowadzone na każdym etapie, a po ich zweryfikowaniu wdróż je na następnym etapie, aż do ostatniego etapu.
Przykłady użycia
Poniżej przedstawiono kilka przykładów sposobu integrowania odświeżania przyrostowego z potokami wdrażania.
Utwórz nowy potok i połącz go z obszarem roboczym przy użyciu modelu semantycznego z włączonym odświeżaniem przyrostowym.
Włącz odświeżanie przyrostowe w modelu semantycznym, który znajduje się już w obszarze roboczym programowania .
Utwórz potok na podstawie produkcyjnego obszaru roboczego z semantycznym modelem korzystającym z odświeżania przyrostowego. Na przykład przypisz obszar roboczy do etapu produkcyjnego nowego potoku i użyj wdrożenia wstecznego do wdrożenia na etapie testowania, a następnie do etapu programowania.
Publikowanie modelu semantycznego, który używa odświeżania przyrostowego do obszaru roboczego będącego częścią istniejącego potoku.
Ograniczenia odświeżania przyrostowego
W przypadku odświeżania przyrostowego potoki wdrażania obsługują tylko modele semantyczne korzystające z rozszerzonych metadanych modelu semantycznego. Wszystkie semantyczne modele utworzone lub zmodyfikowane za pomocą programu Power BI Desktop automatycznie implementują rozszerzone metadane modelu semantycznego.
Podczas ponownego publikowania modelu semantycznego w aktywnym potoku z włączonym odświeżaniem przyrostowym następujące zmiany powodują niepowodzenie wdrożenia z powodu potencjalnego utraty danych:
Ponowne opublikowanie modelu semantycznego, który nie używa odświeżania przyrostowego, w celu zastąpienia modelu semantycznego z włączonym odświeżaniem przyrostowym.
Zmiana nazwy tabeli z włączonym odświeżaniem przyrostowym.
Zmiana nazwy nieliczonych kolumn w tabeli z włączonym odświeżaniem przyrostowym.
Inne zmiany, takie jak dodawanie kolumny, usuwanie kolumny i zmiana nazwy kolumny obliczeniowej, są dozwolone. Jeśli jednak zmiany mają wpływ na ekran, należy odświeżyć, zanim zmiana będzie widoczna.
Modele złożone
Za pomocą modeli złożonych można skonfigurować raport z wieloma połączeniami danych.
Funkcje modeli złożonych umożliwiają łączenie modelu semantycznego sieci szkieletowej z zewnętrznym modelem semantycznym, takim jak usługi Azure Analysis Services. Aby uzyskać więcej informacji, zobacz Using DirectQuery for Fabric semantic models and Azure Analysis Services (Korzystanie z trybu DirectQuery dla modeli semantycznych sieci szkieletowej) i Azure Analysis Services.
W potoku wdrażania można używać modeli złożonych do łączenia modelu semantycznego z innym semantycznym modelem sieci szkieletowej zewnętrznym z potokiem.
Agregacje automatyczne
Agregacje automatyczne są oparte na agregacjach zdefiniowanych przez użytkownika i używają uczenia maszynowego do ciągłego optymalizowania modeli semantycznych DirectQuery w celu uzyskania maksymalnej wydajności zapytań raportu.
Każdy model semantyczny zachowuje automatyczne agregacje po wdrożeniu. Potoki wdrażania nie zmieniają automatycznej agregacji modelu semantycznego. Oznacza to, że jeśli wdrożysz model semantyczny z automatyczną agregacją, automatyczna agregacja na etapie docelowym pozostanie taka, jak jest, i nie zostanie zastąpiona przez automatyczną agregację wdrożona z etapu źródłowego.
Aby włączyć agregacje automatyczne, postępuj zgodnie z instrukcjami w temacie Konfigurowanie agregacji automatycznej.
Tabele hybrydowe
Tabele hybrydowe to tabele z odświeżaniem przyrostowym, które mogą mieć partycje importu i zapytań bezpośrednich. Podczas czystego wdrożenia są kopiowane zarówno zasady odświeżania, jak i partycje tabeli hybrydowej. Podczas wdrażania na etapie potoku, który ma już partycje tabeli hybrydowej, kopiowane są tylko zasady odświeżania. Aby zaktualizować partycje, odśwież tabelę.
Aktualizowanie zawartości do aplikacji usługi Power BI
Aplikacje usługi Power BI to zalecany sposób dystrybucji zawartości do użytkowników bezpłatnej sieci Szkieletowej. Zawartość aplikacji usługi Power BI można zaktualizować przy użyciu potoku wdrażania, co zapewnia większą kontrolę i elastyczność w zakresie cyklu życia aplikacji.
Utwórz aplikację dla każdego etapu potoku wdrażania, aby można było przetestować każdą aktualizację z punktu widzenia użytkownika końcowego. Użyj przycisku Publikuj lub wyświetl na karcie obszaru roboczego, aby opublikować lub wyświetlić aplikację na określonym etapie potoku.

Na etapie produkcji przycisk akcji głównej w prawym dolnym rogu otwiera stronę aktualizacji aplikacji w sieci szkieletowej, dzięki czemu wszystkie aktualizacje zawartości staną się dostępne dla użytkowników aplikacji.

Ważne
Proces wdrażania nie obejmuje aktualizowania zawartości ani ustawień aplikacji. Aby zastosować zmiany w zawartości lub ustawieniach, należy ręcznie zaktualizować aplikację na wymaganym etapie potoku.
Uprawnienia
Uprawnienia są wymagane dla potoku i dla obszarów roboczych, które są do niego przypisane. Uprawnienia potoku i uprawnienia obszaru roboczego są przyznawane i zarządzane oddzielnie.
Potoki mają tylko jedno uprawnienie, Administracja, które jest wymagane do udostępniania, edytowania i usuwania potoku.
Obszary robocze mają różne uprawnienia, nazywane również rolami. Role obszaru roboczego określają poziom dostępu do obszaru roboczego w potoku.
Potoki wdrażania nie obsługują grup platformy Microsoft 365 jako administratorów potoku.
Aby wdrożyć z jednego etapu do innego w potoku, musisz być administratorem potoku i członkiem lub administratorem obszarów roboczych przypisanych do zaangażowanych etapów. Na przykład administrator potoku, który nie ma przypisanej roli obszaru roboczego, może wyświetlić potok i udostępnić go innym osobom. Jednak ten użytkownik nie może wyświetlić zawartości obszaru roboczego w potoku ani w usłudze i nie może wykonywać wdrożeń.
Tabela uprawnień
W tej sekcji opisano uprawnienia potoku wdrażania. Uprawnienia wymienione w tej sekcji mogą mieć różne aplikacje w innych funkcjach sieci Szkieletowej.
Najniższym uprawnieniem potoku wdrożenia jest administrator potoku i jest wymagane dla wszystkich operacji potoku wdrażania.
| User | Uprawnienia potoku | Komentarze |
|---|---|---|
| Administrator potoku |
|
Dostęp do potoku nie udziela uprawnień do wyświetlania ani podejmowania akcji w zawartości obszaru roboczego. |
| Przeglądarka obszarów roboczych (i administrator potoku) |
|
Członkowie obszaru roboczego przypisyli rolę Osoba przeglądająca bez uprawnień do kompilacji , nie mogą uzyskać dostępu do semantycznego modelu ani edytować zawartości obszaru roboczego. |
| Współautor obszaru roboczego (i administrator potoku) |
|
|
| Członek obszaru roboczego (i administrator potoku) |
|
Jeśli ustawienie blokuj ponowne publikowanie i wyłączanie odświeżania pakietu znajdujące się w sekcji zabezpieczeń modelu semantycznego dzierżawy jest włączone, tylko właściciele semantycznych modeli mogą aktualizować modele semantyczne. |
| Administratora obszaru roboczego (i administrator potoku) |
|
Przyznane uprawnienia
Podczas wdrażania elementów usługi Power BI własność wdrożonego elementu może ulec zmianie. Zapoznaj się z poniższą tabelą, aby dowiedzieć się, kto może wdrożyć każdy element i jak wdrożenie wpływa na własność elementu.
| Element sieci szkieletowej | Wymagane uprawnienie do wdrożenia istniejącego elementu | Własność elementu po pierwszym wdrożeniu | Własność elementu po wdrożeniu do etapu z elementem |
|---|---|---|---|
| Model semantyczny | Członek obszaru roboczego | Użytkownik, który dokonał wdrożenia, staje się właścicielem | Niezmienione |
| Przepływ danych | Właściciel przepływu danych | Użytkownik, który dokonał wdrożenia, staje się właścicielem | Niezmienione |
| Datamart | Właściciel obiektu Datamart | Użytkownik, który dokonał wdrożenia, staje się właścicielem | Niezmienione |
| Raport podzielony na strony | Członek obszaru roboczego | Użytkownik, który dokonał wdrożenia, staje się właścicielem | Użytkownik, który dokonał wdrożenia, staje się właścicielem |
Wymagane uprawnienia do popularnych akcji
W poniższej tabeli wymieniono wymagane uprawnienia do popularnych akcji potoku wdrażania. O ile nie określono inaczej, dla każdej akcji potrzebne są wszystkie wymienione uprawnienia.
| Akcja | Wymagane uprawnienia |
|---|---|
| Wyświetlanie listy potoków w organizacji | Brak wymaganej licencji (bezpłatny użytkownik) |
| Tworzenie potoku | Użytkownik z jedną z następujących licencji:
|
| Usuwanie potoku | Administrator potoku |
| Dodawanie lub usuwanie użytkownika potoku | Administrator potoku |
| Przypisywanie obszaru roboczego do etapu |
|
| Anulowanie przypisania obszaru roboczego do etapu | Jedna z następujących:
|
| Wdrażanie na pustym etapie |
|
| Wdrażanie elementów na następnym etapie |
|
| Wyświetlanie lub ustawianie reguły |
|
| Zarządzanie ustawieniami potoku | Administrator potoku |
| Wyświetlanie etapu potoku |
|
| Wyświetlanie listy elementów na etapie | Administrator potoku |
| Porównanie dwóch etapów |
|
| Wyświetlanie historii wdrażania | Administrator potoku |
Rozważania i ograniczenia
W tej sekcji wymieniono większość ograniczeń potoków wdrażania.
- Obszar roboczy musi znajdować się w pojemności sieci szkieletowej.
- Maksymalna liczba elementów, które można wdrożyć w jednym wdrożeniu, wynosi 300.
- Pobieranie pliku pbix po wdrożeniu nie jest obsługiwane.
- Grupy platformy Microsoft 365 nie są obsługiwane jako administratorzy potoku.
- Podczas wdrażania elementu usługi Power BI po raz pierwszy, jeśli inny element na etapie docelowym jest podobny do typu (na przykład jeśli oba pliki są raportami) i ma taką samą nazwę, wdrożenie zakończy się niepowodzeniem.
- Aby uzyskać listę ograniczeń obszaru roboczego, zobacz ograniczenia przypisania obszaru roboczego.
- Aby uzyskać listę obsługiwanych elementów, zobacz obsługiwane elementy. Żaden element, który nie znajduje się na liście, nie jest obsługiwany.
- Wdrożenie kończy się niepowodzeniem, jeśli którykolwiek z elementów ma zależności cykliczne lub samodzielne (na przykład element A odwołuje się do elementu B i elementu B odwołuje się do elementu A).
- Tylko elementy usługi Power BI można wdrożyć w obszarze roboczym w innym regionie pojemności. Nie można wdrożyć innych elementów sieci szkieletowej w obszarze roboczym w innym regionie pojemności.
Ograniczenia modelu semantycznego
Nie można wdrożyć zestawów danych korzystających z łączności danych w czasie rzeczywistym.
Model semantyczny z trybem directQuery lub trybem łączności złożonej korzystającym z tabel odmiany lub automatycznej daty/godziny nie jest obsługiwany. Aby uzyskać więcej informacji, zobacz Co mogę zrobić, jeśli mam zestaw danych z trybem DirectQuery lub trybem łączności złożonej, który używa tabel odmian lub kalendarzy?.
Podczas wdrażania, jeśli docelowy model semantyczny korzysta z połączenia na żywo, źródłowy model semantyczny musi również używać tego trybu połączenia.
Po wdrożeniu pobieranie modelu semantycznego (z etapu, w ramach którego został wdrożony) nie jest obsługiwane.
Aby uzyskać listę ograniczeń reguł wdrażania, zobacz Ograniczenia reguł wdrażania.
Wdrożenie nie jest obsługiwane w modelu semantycznym, który używa zapytań natywnych i zapytania bezpośredniego razem, a automatyczne powiązanie jest zaangażowane w źródło danych DirectQuery.
Ograniczenia przepływu danych
Podczas wdrażania przepływu danych na pustym etapie potoki wdrażania tworzą nowy obszar roboczy i ustawiają magazyn przepływu danych w magazynie obiektów blob sieci szkieletowej. Magazyn obiektów blob jest używany nawet wtedy, gdy źródłowy obszar roboczy jest skonfigurowany do używania usługi Azure Data Lake Storage Gen2 (ADLS Gen2).
Jednostka usługi nie jest obsługiwana w przypadku przepływów danych.
Wdrażanie wspólnego modelu danych (CDM) nie jest obsługiwane.
Aby uzyskać informacje o ograniczeniach reguł potoku wdrażania, które mają wpływ na przepływy danych, zobacz Ograniczenia reguł wdrażania.
Jeśli przepływ danych jest odświeżany podczas wdrażania, wdrożenie zakończy się niepowodzeniem.
W przypadku porównywania etapów podczas odświeżania przepływu danych wyniki są nieprzewidywalne.
Ograniczenia dotyczące funkcji Datamart
Nie można wdrożyć obiektu datamart z etykietami poufności.
Aby wdrożyć element datamart, musisz być właścicielem obiektu datamart.
Powiązana zawartość
Wprowadzenie do potoków wdrażania.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla