Kopiera data till och från Azure Databricks Delta Lake med hjälp av Azure Data Factory eller Azure Synapse Analytics
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder aktiviteten Kopiera i Azure Data Factory och Azure Synapse för att kopiera data till och från Azure Databricks Delta Lake. Den bygger på artikeln aktiviteten Kopiera, som visar en allmän översikt över kopieringsaktiviteten.
Funktioner som stöds
Den här Azure Databricks Delta Lake-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| aktiviteten Kopiera (källa/mottagare) | ① ② |
| Mappa dataflöde (källa/mottagare) | ① |
| Sökningsaktivitet | ① ② |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
I allmänhet stöder tjänsten Delta Lake med följande funktioner för att uppfylla dina olika behov.
- aktiviteten Kopiera stöder Azure Databricks Delta Lake Connector för att kopiera data från alla källdatalager som stöds till Azure Databricks Delta Lake-tabellen och från Delta Lake-tabellen till alla mottagardatalager som stöds. Det utnyttjar ditt Databricks-kluster för att utföra dataflytten, se information i avsnittet Förutsättningar.
- Mappning Dataflöde stöder allmänt Delta-format i Azure Storage som källa och mottagare för att läsa och skriva Delta-filer för kodfri ETL och körs på hanterad Azure Integration Runtime.
- Databricks-aktiviteter stöder orkestrering av din kodcentrerade ETL- eller maskininlärningsarbetsbelastning ovanpå Delta Lake.
Förutsättningar
Om du vill använda den här Azure Databricks Delta Lake-anslutningsappen måste du konfigurera ett kluster i Azure Databricks.
- För att kopiera data till Delta Lake anropar aktiviteten Kopiera Azure Databricks-klustret för att läsa data från en Azure Storage, som antingen är din ursprungliga källa eller ett mellanlagringsområde där tjänsten först skriver källdata via inbyggd mellanlagrad kopia. Lär dig mer från Delta Lake som handfat.
- För att kopiera data från Delta Lake anropar aktiviteten Kopiera Azure Databricks-klustret för att skriva data till en Azure Storage, som antingen är din ursprungliga mottagare eller ett mellanlagringsområde där tjänsten fortsätter att skriva data till slutmottagaren via en inbyggd mellanlagrad kopia. Läs mer från Delta Lake som källa.
Databricks-klustret måste ha åtkomst till Azure Blob- eller Azure Data Lake Storage Gen2-kontot, både lagringscontainern/filsystemet som används för källa/mottagare/mellanlagring och containern/filsystemet där du vill skriva Delta Lake-tabellerna.
Om du vill använda Azure Data Lake Storage Gen2 kan du konfigurera ett huvudnamn för tjänsten i Databricks-klustret som en del av Apache Spark-konfigurationen. Följ stegen i Åtkomst direkt med tjänstens huvudnamn.
Om du vill använda Azure Blob Storage kan du konfigurera en åtkomstnyckel för lagringskontot eller SAS-token i Databricks-klustret som en del av Apache Spark-konfigurationen. Följ stegen i Åtkomst till Azure Blob Storage med hjälp av RDD-API:et.
Om det kluster som du konfigurerade har avslutats under kopieringsaktiviteten startar tjänsten det automatiskt. Om du skapar pipeline med redigeringsgränssnittet behöver du för åtgärder som dataförhandsgranskning ha ett livekluster. Tjänsten startar inte klustret åt dig.
Ange klusterkonfigurationen
I listrutan Klusterläge väljer du Standard.
I listrutan Databricks Runtime Version väljer du en Databricks-körningsversion.
Aktivera Automatisk optimering genom att lägga till följande egenskaper i Spark-konfigurationen:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueKonfigurera klustret beroende på dina integrerings- och skalningsbehov.
Information om klusterkonfiguration finns i Konfigurera kluster.
Kom igång
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
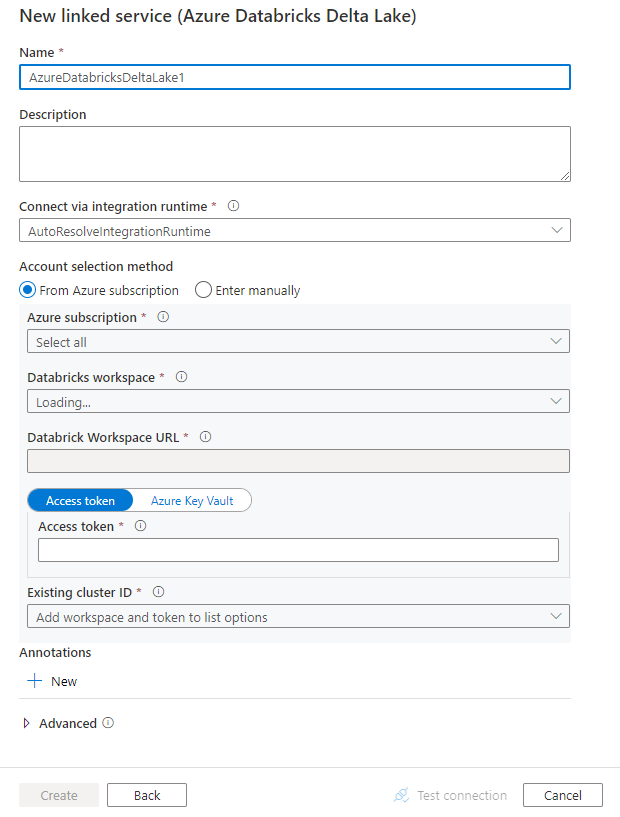
Skapa en länkad tjänst till Azure Databricks Delta Lake med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Azure Databricks Delta Lake i azure-portalens användargränssnitt.
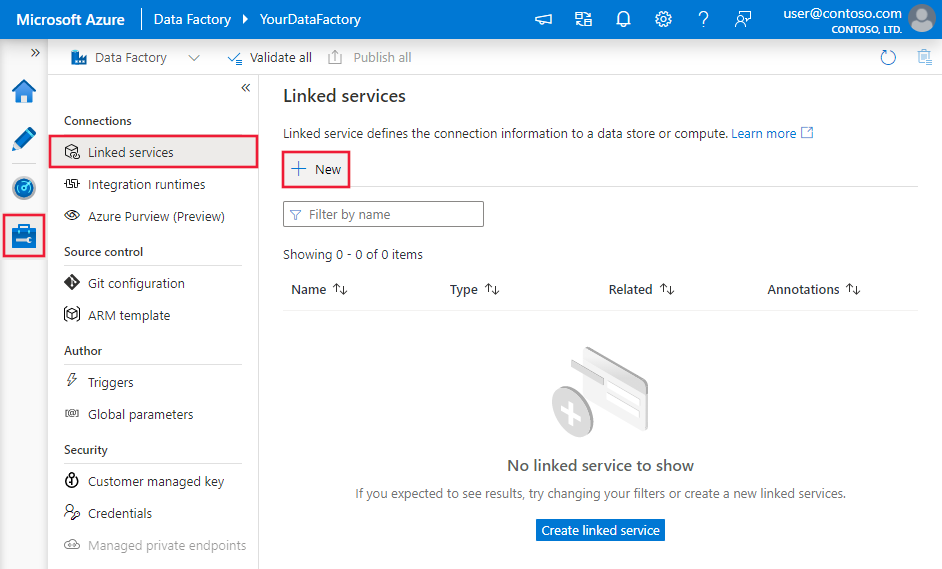
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter delta och välj Anslutningsprogrammet för Azure Databricks Delta Lake.

Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Anslut eller konfigurationsinformation
Följande avsnitt innehåller information om egenskaper som definierar entiteter som är specifika för en Azure Databricks Delta Lake-anslutning.
Länkade tjänstegenskaper
Den här Azure Databricks Delta Lake-anslutningsappen stöder följande autentiseringstyper. Mer information finns i motsvarande avsnitt.
- Åtkomsttoken
- Systemtilldelad autentisering av hanterad identitet
- Användartilldelad hanterad identitetsautentisering
Åtkomsttoken
Följande egenskaper stöds för den länkade Azure Databricks Delta Lake-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på AzureDatabricksDeltaLake. | Ja |
| domain | Ange URL:en för Azure Databricks-arbetsytan, t.ex. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | Ange kluster-ID för ett befintligt kluster. Det bör vara ett redan skapat interaktivt kluster. Du hittar kluster-ID:t för ett interaktivt kluster på Databricks-arbetsytan – Kluster –>> Interaktivt klusternamn –> Konfiguration –> Taggar. Läs mer. |
|
| accessToken | Åtkomsttoken krävs för att tjänsten ska kunna autentisera till Azure Databricks. Åtkomsttoken måste genereras från databricks-arbetsytan. Mer detaljerade steg för att hitta åtkomsttoken finns här. | |
| connectVia | Den integrationskörning som används för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller en lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
Systemtilldelad autentisering av hanterad identitet
Mer information om systemtilldelade hanterade identiteter för Azure-resurser finns i systemtilldelad hanterad identitet för Azure-resurser.
Om du vill använda systemtilldelad hanterad identitetsautentisering följer du dessa steg för att bevilja behörigheter:
Hämta den hanterade identitetsinformationen genom att kopiera värdet för det hanterade identitetsobjekt-ID som genererats tillsammans med din datafabrik eller Synapse-arbetsyta.
Ge den hanterade identiteten rätt behörigheter i Azure Databricks. I allmänhet måste du ge rollen Deltagare till din systemtilldelade hanterade identitet i Åtkomstkontroll (IAM ) för Azure Databricks.
Följande egenskaper stöds för den länkade Azure Databricks Delta Lake-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på AzureDatabricksDeltaLake. | Ja |
| domain | Ange URL:en för Azure Databricks-arbetsytan, t.ex. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ja |
| clusterId | Ange kluster-ID för ett befintligt kluster. Det bör vara ett redan skapat interaktivt kluster. Du hittar kluster-ID:t för ett interaktivt kluster på Databricks-arbetsytan – Kluster –>> Interaktivt klusternamn –> Konfiguration –> Taggar. Läs mer. |
Ja |
| workspaceResourceId | Ange arbetsytans resurs-ID för dina Azure Databricks. | Ja |
| connectVia | Den integrationskörning som används för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller en lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Användartilldelad hanterad identitetsautentisering
Mer information om användartilldelade hanterade identiteter för Azure-resurser finns i användartilldelade hanterade identiteter
Följ dessa steg om du vill använda användartilldelad hanterad identitetsautentisering:
Skapa en eller flera användartilldelade hanterade identiteter och bevilja behörighet i Azure Databricks. I allmänhet måste du bevilja minst deltagarrollentill din användartilldelade hanterade identitet i Åtkomstkontroll (IAM) för Azure Databricks.
Tilldela en eller flera användartilldelade hanterade identiteter till din datafabrik eller Synapse-arbetsyta och skapa autentiseringsuppgifter för varje användartilldelad hanterad identitet.
Följande egenskaper stöds för den länkade Azure Databricks Delta Lake-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på AzureDatabricksDeltaLake. | Ja |
| domain | Ange URL:en för Azure Databricks-arbetsytan, t.ex. https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
Ja |
| clusterId | Ange kluster-ID för ett befintligt kluster. Det bör vara ett redan skapat interaktivt kluster. Du hittar kluster-ID:t för ett interaktivt kluster på Databricks-arbetsytan – Kluster –>> Interaktivt klusternamn –> Konfiguration –> Taggar. Läs mer. |
Ja |
| autentiseringsuppgifter | Ange den användartilldelade hanterade identiteten som autentiseringsobjekt. | Ja |
| workspaceResourceId | Ange arbetsytans resurs-ID för dina Azure Databricks. | Ja |
| connectVia | Den integrationskörning som används för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller en lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar .
Följande egenskaper stöds för Azure Databricks Delta Lake-datauppsättningen.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till AzureDatabricksDeltaLakeDataset. | Ja |
| database | Namnet på databasen. | Nej för källa, ja för mottagare |
| table | Namnet på deltatabellen. | Nej för källa, ja för mottagare |
Exempel:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Azure Databricks Delta Lake-källan och mottagaren.
Delta lake som källa
Följande egenskaper stöds i avsnittet aktiviteten Kopiera källa för att kopiera data från Azure Databricks Delta Lake.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för den aktiviteten Kopiera källan måste anges till AzureDatabricksDeltaLakeSource. | Ja |
| query | Ange SQL-frågan för att läsa data. Följ nedanstående mönster för tidsresekontrollen: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
Nej |
| export Inställningar | Avancerade inställningar som används för att hämta data från deltatabellen. | Nej |
Under exportSettings: |
||
| type | Typ av exportkommando, inställt på AzureDatabricksDeltaLakeExportCommand. | Ja |
| dateFormat | Formatera datumtyp till sträng med ett datumformat. Anpassade datumformat följer formaten i datetime-mönstret. Om det inte anges används standardvärdet yyyy-MM-dd. |
Nej |
| timestampFormat | Formatera tidsstämpeltyp till sträng med tidsstämpelformat. Anpassade datumformat följer formaten i datetime-mönstret. Om det inte anges används standardvärdet yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
Nej |
Direktkopiering från Delta Lake
Om ditt datalager och format för mottagare uppfyller de kriterier som beskrivs i det här avsnittet kan du använda aktiviteten Kopiera för att kopiera direkt från Azure Databricks Delta-tabellen till mottagare. Tjänsten kontrollerar inställningarna och misslyckas med aktiviteten Kopiera köras om följande villkor inte uppfylls:
Den länkade tjänsten för mottagare är Azure Blob Storage eller Azure Data Lake Storage Gen2. Kontoautentiseringsuppgifterna ska vara förkonfigurerade i Azure Databricks-klusterkonfigurationen, läs mer i Krav.
Dataformatet för mottagare är av Parquet, avgränsad text eller Avro med följande konfigurationer och pekar på en mapp i stället för en fil.
- För Parquet-format är komprimeringskodcen ingen, snabb eller gzip.
- För avgränsat textformat :
rowDelimiterär ett enskilt tecken.compressionkan vara ingen, bzip2, gzip.encodingNameUTF-7 stöds inte.
- För Avro-format är komprimeringskodcen ingen, deflatera eller snabb.
I den aktiviteten Kopiera källan
additionalColumnsanges inte.Om du kopierar data till avgränsad text måste du i kopieringsaktivitetsmottagaren
fileExtensionvara ".csv".I aktiviteten Kopiera mappning är typkonvertering inte aktiverat.
Exempel:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mellanlagrad kopia från Delta Lake
När ditt datalager eller format för mottagare inte matchar kriterierna för direktkopiering, som du nämnde i det förra avsnittet, aktiverar du den inbyggda mellanlagrade kopian med hjälp av en mellanliggande Azure Storage-instans. Den mellanlagrade kopieringsfunktionen ger dig också bättre dataflöde. Tjänsten exporterar data från Azure Databricks Delta Lake till mellanlagring, kopierar sedan data till mottagare och rensar slutligen dina tillfälliga data från mellanlagringen. Mer information om hur du kopierar data med mellanlagring finns i Mellanlagrad kopia .
Om du vill använda den här funktionen skapar du en länkad Azure Blob Storage-tjänst eller en länkad Azure Data Lake Storage Gen2-tjänst som refererar till lagringskontot som mellanlagring. Ange enableStaging sedan egenskaperna och stagingSettings i aktiviteten Kopiera.
Kommentar
Autentiseringsuppgifterna för mellanlagringskontot bör vara förkonfigurerade i Azure Databricks-klusterkonfigurationen, läs mer i Krav.
Exempel:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta lake som mottagare
För att kopiera data till Azure Databricks Delta Lake stöds följande egenskaper i avsnittet aktiviteten Kopiera mottagare.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för aktiviteten Kopiera mottagare, inställd på AzureDatabricksDeltaLakeSink. | Ja |
| preCopyScript | Ange en SQL-fråga för aktiviteten Kopiera som ska köras innan du skriver data till Databricks deltatabell i varje körning. Exempel: VACUUM eventsTable DRY RUN Du kan använda den här egenskapen för att rensa inlästa data eller lägga till en trunkeringstabell eller vacuum-instruktion. |
Nej |
| importera Inställningar | Avancerade inställningar som används för att skriva data till deltatabellen. | Nej |
Under importSettings: |
||
| type | Typ av importkommando, inställt på AzureDatabricksDeltaLakeImportCommand. | Ja |
| dateFormat | Formatera sträng till datumtyp med ett datumformat. Anpassade datumformat följer formaten i datetime-mönstret. Om det inte anges används standardvärdet yyyy-MM-dd. |
Nej |
| timestampFormat | Formatera sträng till tidsstämpeltyp med ett tidsstämpelformat. Anpassade datumformat följer formaten i datetime-mönstret. Om det inte anges används standardvärdet yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
Nej |
Direktkopiering till Delta Lake
Om källdatalagret och formatet uppfyller kriterierna som beskrivs i det här avsnittet kan du använda aktiviteten Kopiera för att kopiera direkt från källan till Azure Databricks Delta Lake. Tjänsten kontrollerar inställningarna och misslyckas med aktiviteten Kopiera köras om följande villkor inte uppfylls:
Den länkade källtjänsten är Azure Blob Storage eller Azure Data Lake Storage Gen2. Kontoautentiseringsuppgifterna ska vara förkonfigurerade i Azure Databricks-klusterkonfigurationen, läs mer i Krav.
Källdataformatet är av Parquet, avgränsad text eller Avro med följande konfigurationer och pekar på en mapp i stället för en fil.
- För Parquet-format är komprimeringskodcen ingen, snabb eller gzip.
- För avgränsat textformat :
rowDelimiterär standard eller ett enskilt tecken.compressionkan vara ingen, bzip2, gzip.encodingNameUTF-7 stöds inte.
- För Avro-format är komprimeringskodcen ingen, deflatera eller snabb.
I aktiviteten Kopiera källa:
wildcardFileNameinnehåller endast jokertecken*men inte?, ochwildcardFolderNamehar inte angetts.prefix,modifiedDateTimeStart,modifiedDateTimeEndochenablePartitionDiscoveryhar inte angetts.additionalColumnshar inte angetts.
I aktiviteten Kopiera mappning är typkonvertering inte aktiverat.
Exempel:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReadrQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
Mellanlagrad kopia till Delta Lake
När ditt källdatalager eller -format inte matchar kriterierna för direktkopiering, som du nämnde i det förra avsnittet, aktiverar du den inbyggda mellanlagrade kopian med hjälp av en mellanliggande Azure Storage-instans. Den mellanlagrade kopieringsfunktionen ger dig också bättre dataflöde. Tjänsten konverterar automatiskt data för att uppfylla kraven för dataformat till mellanlagring och läser sedan in data till Delta Lake därifrån. Slutligen rensas dina tillfälliga data från lagringen. Mer information om hur du kopierar data med mellanlagring finns i Mellanlagrad kopia .
Om du vill använda den här funktionen skapar du en länkad Azure Blob Storage-tjänst eller en länkad Azure Data Lake Storage Gen2-tjänst som refererar till lagringskontot som mellanlagring. Ange enableStaging sedan egenskaperna och stagingSettings i aktiviteten Kopiera.
Kommentar
Autentiseringsuppgifterna för mellanlagringskontot bör vara förkonfigurerade i Azure Databricks-klusterkonfigurationen, läs mer i Krav.
Exempel:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Övervakning
Samma övervakningsupplevelse för kopieringsaktivitet tillhandahålls som för andra anslutningsappar. Eftersom inläsning av data från/till Delta Lake körs på ditt Azure Databricks-kluster kan du dessutom visa detaljerade klusterloggar och övervaka prestanda.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare efter aktiviteten Kopiera finns i datalager och format som stöds.