Kopiera och transformera data från Hive med Azure Data Factory
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i en Azure Data Factory- eller Synapse Analytics-pipeline för att kopiera data från Hive. Den bygger på översiktsartikeln för kopieringsaktivitet som visar en allmän översikt över kopieringsaktiviteten.
Funktioner som stöds
Den här Hive-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| aktiviteten Kopiera (källa/-) | ① ② |
| Mappa dataflöde (källa/-) | ① |
| Sökningsaktivitet | ① ② |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor/mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Tjänsten tillhandahåller en inbyggd drivrutin för att aktivera anslutningen. Därför behöver du inte installera någon drivrutin manuellt med den här anslutningsappen.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Komma igång
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst till Hive med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Hive i azure-portalens användargränssnitt.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Hive och välj Hive-anslutningsappen.
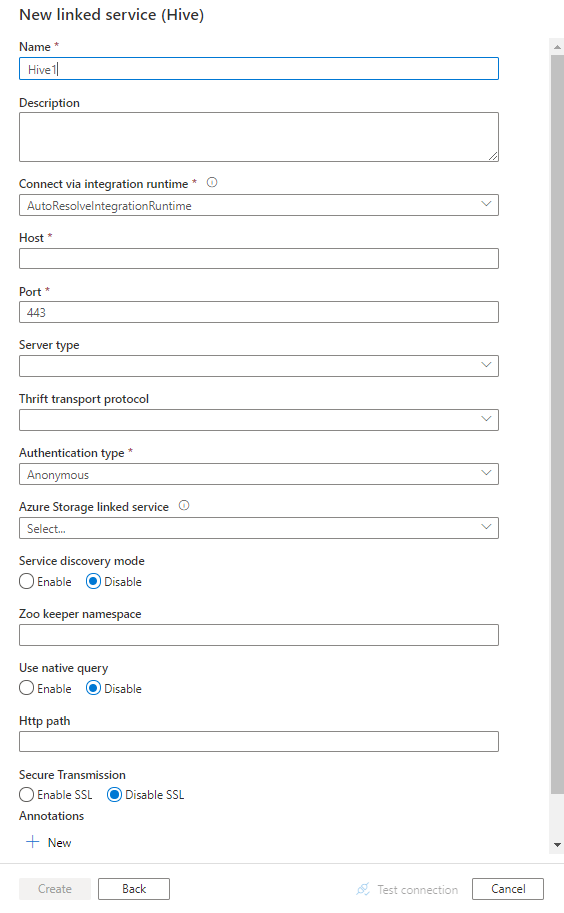
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Anslut eller konfigurationsinformation
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Hive-anslutningsprogrammet.
Länkade tjänstegenskaper
Följande egenskaper stöds för Hive-länkad tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till: Hive | Ja |
| värd | IP-adress eller värdnamn för Hive-servern, avgränsat med ";" för flera värdar (endast när serviceDiscoveryMode är aktiverat). | Ja |
| port | TCP-porten som Hive-servern använder för att lyssna efter klientanslutningar. Om du ansluter till Azure HDInsight anger du porten som 443. | Ja |
| serverType | Typ av Hive-server. Tillåtna värden är: HiveServer1, HiveServer2, HiveThriftServer |
Nej |
| thriftTransportProtocol | Transportprotokollet som ska användas i Thrift-lagret. Tillåtna värden är: Binär, SASL, HTTP |
Nej |
| authenticationType | Den autentiseringsmetod som används för att komma åt Hive-servern. Tillåtna värden är: Anonym, Användarnamn, AnvändarnamnAndPassword, WindowsAzureHDInsightService. Kerberos-autentisering stöds inte nu. |
Ja |
| serviceDiscoveryMode | sant för att ange användning av ZooKeeper-tjänsten, falskt inte. | Nej |
| zooKeeperNameSpace | Namnområdet på ZooKeeper under vilket Hive Server 2-noder läggs till. | Nej |
| useNativeQuery | Anger om drivrutinen använder interna HiveQL-frågor eller konverterar dem till ett motsvarande formulär i HiveQL. | Nej |
| användarnamn | Det användarnamn som du använder för att komma åt Hive Server. | Nej |
| password | Lösenordet som motsvarar användaren. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Nej |
| httpPath | Den partiella URL:en som motsvarar Hive-servern. | Nej |
| enableSsl | Anger om anslutningarna till servern krypteras med hjälp av TLS. Standardvärdet är "false". | Nej |
| trustedCertPath | Den fullständiga sökvägen till .pem-filen som innehåller betrodda CA-certifikat för att verifiera servern när du ansluter via TLS. Den här egenskapen kan bara anges när du använder TLS på lokalt installerad IR. Standardvärdet är filen cacerts.pem som är installerad med IR. | Nej |
| useSystemTrustStore | Anger om du vill använda ett CA-certifikat från systemförtroendearkivet eller från en angiven PEM-fil. Standardvärdet är "false". | Nej |
| allowHostNameCNMismatch | Anger om ett CA-utfärdat TLS/SSL-certifikatnamn ska matcha serverns värdnamn vid anslutning via TLS. Standardvärdet är "false". | Nej |
| allowSelfSignedServerCert | Anger om självsignerade certifikat ska tillåtas från servern. Standardvärdet är "false". | Nej |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
| storageReference | En referens till den länkade tjänsten för lagringskontot som används för mellanlagring av data i mappning av dataflöde. Detta krävs endast när du använder den Länkade Hive-tjänsten i mappning av dataflöde | Nej |
Exempel:
{
"name": "HiveLinkedService",
"properties": {
"type": "Hive",
"typeProperties": {
"host" : "<cluster>.azurehdinsight.net",
"port" : "<port>",
"authenticationType" : "WindowsAzureHDInsightService",
"username" : "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Hive-datauppsättningen.
Om du vill kopiera data från Hive anger du datamängdens typegenskap till HiveObject. Följande egenskaper stöds:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till: HiveObject | Ja |
| schema | Namnet på schemat. | Nej (om "fråga" i aktivitetskällan har angetts) |
| table | Tabellens namn. | Nej (om "fråga" i aktivitetskällan har angetts) |
| tableName | Namnet på tabellen inklusive schemadelen. Den här egenskapen stöds för bakåtkompatibilitet. För ny arbetsbelastning använder du schema och table. |
Nej (om "fråga" i aktivitetskällan har angetts) |
Exempel
{
"name": "HiveDataset",
"properties": {
"type": "HiveObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Hive linked service name>",
"type": "LinkedServiceReference"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Hive-källan.
HiveSource som källa
Om du vill kopiera data från Hive anger du källtypen i kopieringsaktiviteten till HiveSource. Följande egenskaper stöds i avsnittet kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till: HiveSource | Ja |
| query | Använd den anpassade SQL-frågan för att läsa data. Exempel: "SELECT * FROM MyTable". |
Nej (om "tableName" i datauppsättningen har angetts) |
Exempel:
"activities":[
{
"name": "CopyFromHive",
"type": "Copy",
"inputs": [
{
"referenceName": "<Hive input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "HiveSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Mappa dataflödesegenskaper
Hive-anslutningsappen stöds som en infogad datamängdskälla i mappning av dataflöden. Läsa med hjälp av en fråga eller direkt från en Hive-tabell i HDInsight. Hive-data mellanlagras i ett lagringskonto som parquet-filer innan de transformeras som en del av ett dataflöde.
Källegenskaper
Tabellen nedan visar de egenskaper som stöds av en hive-källa. Du kan redigera dessa egenskaper på fliken Källalternativ .
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Store | Arkivet måste vara hive |
ja | hive |
lager |
| Format | Oavsett om du läser från en tabell eller fråga | ja | table eller query |
format |
| Schemanamn | Om du läser från en tabell, schema för källtabellen | Ja, om formatet är table |
String | schemaName |
| Tabellnamn | Om du läser från en tabell, tabellnamnet | Ja, om formatet är table |
String | tableName |
| Fråga | Om formatet är är querykällfrågan på den Hive-länkade tjänsten |
Ja, om formatet är query |
String | query |
| Iscensatt | Hive-tabellen mellanlagras alltid. | ja | true |
Iscensatt |
| Lagringscontainer | Lagringscontainer som används för att mellanlagra data innan du läser från Hive eller skriver till Hive. Hive-klustret måste ha åtkomst till den här containern. | ja | String | storageContainer |
| Mellanlagringsdatabas | Schemat/databasen där användarkontot som anges i den länkade tjänsten har åtkomst till. Den används för att skapa externa tabeller under mellanlagringen och tas bort efteråt | no | true eller false |
stagingDatabaseName |
| För SQL-skript | SQL-kod som ska köras i Hive-tabellen innan data läss | no | String | preSQLs |
Källexempel
Nedan visas ett exempel på en Hive-källkonfiguration:
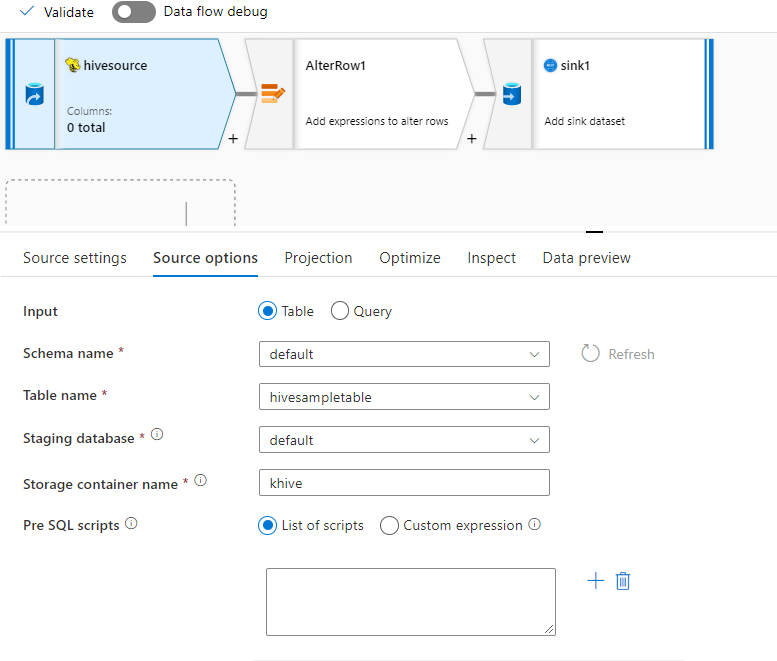
De här inställningarna översätts till följande dataflödesskript:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
format: 'table',
store: 'hive',
schemaName: 'default',
tableName: 'hivesampletable',
staged: true,
storageContainer: 'khive',
storageFolderPath: '',
stagingDatabaseName: 'default') ~> hivesource
Kända begränsningar
- Komplexa typer som matriser, kartor, structs och fackföreningar stöds inte för läsning.
- Hive-anslutningsappen stöder endast Hive-tabeller i Azure HDInsight av version 4.0 eller senare (Apache Hive 3.1.0)
- Som standard tillhandahåller Hive-drivrutinen "tableName.columnName" i mottagare. Om du inte vill se tabellnamnet i kolumnnamnet finns det två sätt att åtgärda detta. a. Kontrollera inställningen "hive.resultset.use.unique.column.names" på Hive-serversidan och ange den till false. b. Använd kolumnmappning för att byta namn på kolumnnamnet.
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.