Självstudie: Skapa en datapipeline från slutpunkt till slutpunkt för att härleda försäljningsinsikter i Azure HDInsight
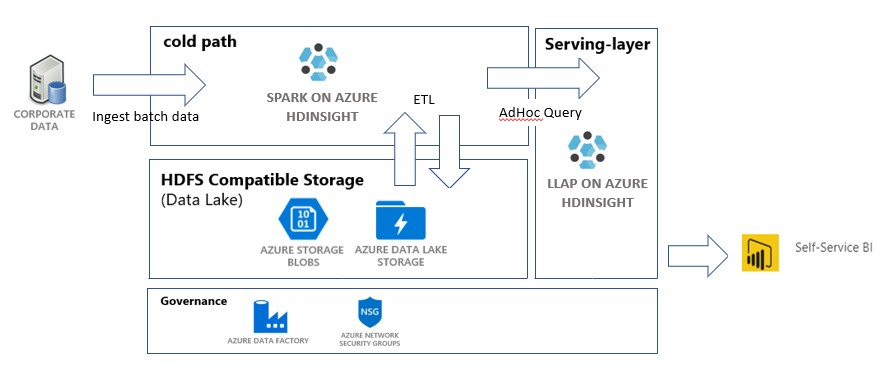
I den här självstudien skapar du en datapipeline från slutpunkt till slutpunkt som utför åtgärder för att extrahera, transformera och läsa in (ETL). Pipelinen använder Apache Spark - och Apache Hive-kluster som körs i Azure HDInsight för att fråga och manipulera data. Du kommer också att använda tekniker som Azure Data Lake Storage Gen2 för datalagring och Power BI för visualisering.
Den här datapipelinen kombinerar data från olika lager, tar bort oönskade data, lägger till nya data och läser in allt detta i din lagring för att visualisera affärsinsikter. Läs mer om ETL-pipelines i Extrahera, transformera och läsa in (ETL) i stor skala.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Azure CLI – minst version 2.2.0. Se Installera Azure CLI.
jq, en JSON-processor på kommandoraden. Se https://stedolan.github.io/jq/.
En medlem i den inbyggda Azure-rollen – ägare.
Om du använder PowerShell för att utlösa Data Factory-pipelinen behöver du Az-modulen.
Power BI Desktop för att visualisera affärsinsikter i slutet av den här självstudien.
Skapa resurser
Klona lagringsplatsen med skript och data
Logga in på din Azure-prenumeration. Om du planerar att använda Azure Cloud Shell väljer du Prova i det övre högra hörnet i kodblocket. Annars anger du kommandot nedan:
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Se till att du är medlem i Azure-rollens ägare. Ersätt
user@contoso.commed ditt konto och ange sedan kommandot:az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"Om ingen post returneras är du inte medlem och kommer inte att kunna slutföra den här självstudien.
Ladda ned data och skript för den här självstudien från ETL-lagringsplatsen för HDInsight Sales Insights. Ange följande kommando:
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlKontrollera att
salesdata scripts templateshar skapats. Kontrollera med följande kommando:ls
Distribuera Azure-resurser som behövs för pipelinen
Lägg till körningsbehörigheter för alla skript genom att ange:
chmod +x scripts/*.shAnge variabel för resursgrupp. Ersätt
RESOURCE_GROUP_NAMEmed namnet på en befintlig eller ny resursgrupp och ange sedan kommandot:RESOURCE_GROUP="RESOURCE_GROUP_NAME"Kör skriptet. Ersätt
LOCATIONmed ett önskat värde och ange sedan kommandot:./scripts/resources.sh $RESOURCE_GROUP LOCATIONOm du inte är säker på vilken region du vill ange kan du hämta en lista över regioner som stöds för din prenumeration med kommandot az account list-locations .
Kommandot distribuerar följande resurser:
- Ett Azure Blob Storage-konto. Det här kontot innehåller företagets försäljningsdata.
- Ett Azure Data Lake Storage Gen2-konto. Det här kontot fungerar som lagringskonto för båda HDInsight-kluster. Läs mer om HDInsight och Data Lake Storage Gen2 i Azure HDInsight-integrering med Data Lake Storage Gen2.
- En användartilldelad hanterad identitet. Det här kontot ger HDInsight-kluster åtkomst till Data Lake Storage Gen2-kontot.
- Ett Apache Spark-kluster. Det här klustret används för att rensa och transformera rådata.
- Ett Apache Hive-Interaktiv fråga kluster. Det här klustret gör det möjligt att köra frågor mot försäljningsdata och visualisera dem med Power BI.
- Ett virtuellt Azure-nätverk som stöds av NSG-regler (Network Security Group). Med det här virtuella nätverket kan klustren kommunicera och skydda sin kommunikation.
Det kan ta cirka 20 minuter att skapa kluster.
Standardlösenordet för SSH-åtkomst till klustren är Thisisapassword1. Om du vill ändra lösenordet går du till ./templates/resourcesparameters_remainder.json filen och ändrar lösenordet för parametrarna sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPasswordoch llapsshPassword .
Verifiera distributionen och samla in resursinformation
Om du vill kontrollera statusen för distributionen går du till resursgruppen på Azure-portalen. Under Inställningar väljer du Distributioner och sedan distributionen. Här kan du se de resurser som har distribuerats och de resurser som fortfarande pågår.
Om du vill visa namnen på klustren anger du följande kommando:
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEOm du vill visa Azure Storage-kontot och åtkomstnyckeln anger du följande kommando:
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYOm du vill visa Data Lake Storage Gen2-kontot och åtkomstnyckeln anger du följande kommando:
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Skapa en datafabrik
Azure Data Factory är ett verktyg som hjälper dig att automatisera Azure Pipelines. Det är inte det enda sättet att utföra dessa uppgifter, men det är ett bra sätt att automatisera processerna. Mer information om Azure Data Factory finns i Dokumentationen om Azure Data Factory.
Den här datafabriken har en pipeline med två aktiviteter:
- Den första aktiviteten kopierar data från Azure Blob Storage till Data Lake Storage Gen 2-lagringskontot för att efterlikna datainmatning.
- Den andra aktiviteten transformerar data i Spark-klustret. Skriptet transformerar data genom att ta bort oönskade kolumner. Den lägger också till en ny kolumn som beräknar de intäkter som en enskild transaktion genererar.
Om du vill konfigurera din Azure Data Factory-pipeline kör du kommandot nedan. Du bör fortfarande vara i hdinsight-sales-insights-etl katalogen.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
Det här skriptet gör följande:
- Skapar ett huvudnamn för tjänsten med
Storage Blob Data Contributorbehörigheter för Data Lake Storage Gen2-lagringskontot. - Hämtar en autentiseringstoken för att auktorisera POST-begäranden till REST-API:et för Data Lake Storage Gen2-filsystemet.
- Fyller i det faktiska namnet på ditt Data Lake Storage Gen2-lagringskonto i
sparktransform.pyfilerna ochquery.hql. - Hämtar lagringsnycklar för Data Lake Storage Gen2- och Blob Storage-kontona.
- Skapar en annan resursdistribution för att skapa en Azure Data Factory-pipeline med tillhörande länkade tjänster och aktiviteter. Den skickar lagringsnycklarna som parametrar till mallfilen så att de länkade tjänsterna kan komma åt lagringskontona korrekt.
Kör datapipelinen
Utlösa Data Factory-aktiviteterna
Den första aktiviteten i Data Factory-pipelinen som du har skapat flyttar data från Blob Storage till Data Lake Storage Gen2. Den andra aktiviteten tillämpar Spark-transformeringarna på data och sparar de transformerade .csv-filerna på en ny plats. Det kan ta några minuter att slutföra hela pipelinen.
Om du vill hämta Data Factory-namnet anger du följande kommando:
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
Om du vill utlösa pipelinen kan du antingen:
Utlös Data Factory-pipelinen i PowerShell. Ersätt
RESOURCEGROUPochDataFactoryNamemed lämpliga värden och kör sedan följande kommandon:# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipelineKör igen
Get-AzDataFactoryV2PipelineRunefter behov för att övervaka förloppet.Eller
Öppna datafabriken och välj Författare och Övervaka. Utlös pipelinen
IngestAndTransformfrån portalen. Information om hur du utlöser pipelines via portalen finns i Skapa Apache Hadoop-kluster på begäran i HDInsight med Azure Data Factory.
Om du vill kontrollera att pipelinen har körts kan du utföra något av följande steg:
- Gå till avsnittet Övervaka i datafabriken via portalen.
- I Azure Storage Explorer går du till ditt Data Lake Storage Gen 2-lagringskonto. Gå till
filesfilsystemet och gå sedan tilltransformedmappen och kontrollera innehållet för att se om pipelinen lyckades.
Andra sätt att transformera data med hjälp av HDInsight finns i den här artikeln om hur du använder Jupyter Notebook.
Skapa en tabell i Interaktiv fråga-klustret för att visa data i Power BI
query.hqlKopiera filen till LLAP-klustret med hjälp av SCP. Ange kommandot:LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/Påminnelse: Standardlösenordet är
Thisisapassword1.Använd SSH för att komma åt LLAP-klustret. Ange kommandot:
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.netAnvänd följande kommando för att köra skriptet:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlDet här skriptet skapar en hanterad tabell i det Interaktiv fråga kluster som du kan komma åt från Power BI.
Skapa en Power BI-instrumentpanel från försäljningsdata
Öppna Power BI Desktop.
Från menyn går du till Hämta data>Mer...>Azure>HDInsight-Interaktiv fråga.
Välj Anslut.
Från dialogrutan HDInsight Interaktiv fråga:
- I textrutan Server anger du namnet på ditt LLAP-kluster i formatet
https://LLAPCLUSTERNAME.azurehdinsight.net. - I textrutan databas anger du
default. - Välj OK.
- I textrutan Server anger du namnet på ditt LLAP-kluster i formatet
I dialogrutan AzureHive:
- I textrutan Användarnamn anger du
admin. - I textrutan Lösenord anger du
Thisisapassword1. - Välj Anslut.
- I textrutan Användarnamn anger du
I Navigatör väljer du
salesoch/ellersales_rawför att förhandsgranska data. När data har lästs in kan du experimentera med instrumentpanelen som du vill skapa. Se följande länkar för att komma igång med Power BI-instrumentpaneler:
- Introduktion till instrumentpaneler för Power BI-designers
- Självstudie: Kom igång med Power BI-tjänst
Rensa resurser
Om du inte fortsätter att använda det här programmet tar du bort alla resurser med hjälp av följande kommando så att du inte debiteras för dem.
Om du vill ta bort resursgruppen anger du kommandot:
az group delete -n $RESOURCE_GROUPOm du vill ta bort tjänstens huvudnamn anger du kommandona:
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL