Snabbstart: Skapa en serverlös Apache Spark-pool i Azure Synapse Analytics med hjälp av webbverktyg
I den här snabbstarten får du lära dig hur du skapar en serverlös Apache Spark-pool i Azure Synapse med hjälp av webbverktyg. Sedan lär du dig att ansluta till Apache Spark-poolen och köra Spark SQL-frågor mot filer och tabeller. Apache Spark möjliggör snabb data-analys och kluster-computing med minnesintern bearbetning. Information om Spark i Azure Synapse finns i Översikt: Apache Spark på Azure Synapse.
Viktigt
Faktureringen för Spark-instanser proportionellt per minut, oavsett om du använder dem eller inte. Se till att stänga av Spark-instansen när du har använt den eller ange en kort tidsgräns. Mer information finns i avsnittet Rensa resurser i den här artikeln.
Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Du behöver en Azure-prenumeration. Om det behövs skapar du ett kostnadsfritt Azure-konto
- Synapse Analytics-arbetsyta
- Serverlös Apache Spark-pool
Logga in på Azure Portal
Logga in på Azure-portalen.
Om du inte har en Azure-prenumeration kan du skapa ett kostnadsfritt Azure-konto innan du börjar.
Skapa en notebook-fil
En notebook-fil är en interaktiv miljö som stöder olika programmeringsspråk. Med notebook-filen kan du interagera med dina data, kombinera kod med markdown, text och utföra enkla visualiseringar.
Välj Starta Synapse Studio i vyn Azure Portal för den Azure Synapse arbetsyta som du vill använda.
När Synapse Studio har startats väljer du Utveckla. Välj sedan ikonen "+" för att lägga till en ny resurs.
Därifrån väljer du Notebook. En ny anteckningsbok skapas och öppnas med ett automatiskt genererat namn.

I fönstret Egenskaper anger du ett namn för anteckningsboken.
Klicka på Publicera i verktygsfältet.
Om det bara finns en Apache Spark-pool på din arbetsyta väljs den som standard. Använd listrutan för att välja rätt Apache Spark-pool om ingen har valts.
Klicka på Lägg till kod. Standardspråket är
Pyspark. Du kommer att använda en blandning av Pyspark och Spark SQL, så standardvalet är bra. Andra språk som stöds är Scala och .NET för Spark.Sedan skapar du ett enkelt Spark DataFrame-objekt som ska manipuleras. I det här fallet skapar du den från kod. Det finns tre rader och tre kolumner:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Kör cellen med någon av följande metoder:
Tryck på SKIFT + RETUR.
Välj den blå uppspelningsikonen till vänster om cellen.
Välj knappen Kör alla i verktygsfältet.
Om Apache Spark-poolinstansen inte redan körs startas den automatiskt. Du kan se statusen för Apache Spark-poolinstansen under cellen som du kör och även på statuspanelen längst ned i anteckningsboken. Beroende på poolens storlek bör det ta 2–5 minuter att starta. När koden har körts visas information under cellen som visar hur lång tid det tog att köra och dess körning. I utdatacellen visas utdata.
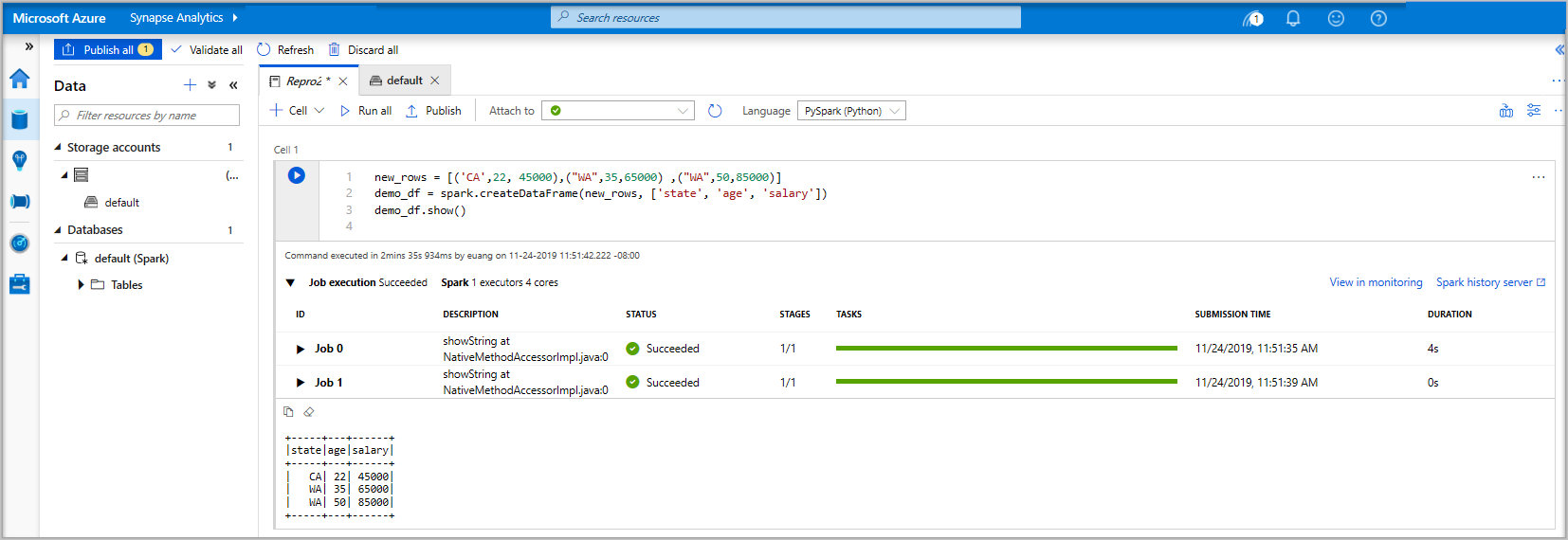
Data finns nu i en DataFrame därifrån du kan använda data på många olika sätt. Du kommer att behöva det i olika format för resten av den här snabbstarten.
Ange koden nedan i en annan cell och kör den. Då skapas en Spark-tabell, en CSV och en Parquet-fil med kopior av data:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Om du använder lagringsutforskaren kan du se effekten av de två olika sätten att skriva en fil som används ovan. När inget filsystem anges används standardinställningen i det här fallet
default>user>trusted-service-user>demo_df. Data sparas på platsen för det angivna filsystemet.Observera i både "csv" och "parquet" format, skrivåtgärder en katalog skapas med många partitionerade filer.


Kör Spark SQL-instruktioner
Structured Query Language (SQL) är det vanligaste och mest använda språket för att fråga och definiera data. Spark SQL fungerar som ett tillägg till Apache Spark för bearbetning av strukturerade data med den välbekanta SQL-syntaxen.
Klistra in följande kod i en tom cell och kör sedan koden. Kommandot visar tabellerna i poolen.
%%sql SHOW TABLESNär du använder en notebook-fil med din Azure Synapse Apache Spark-pool får du en förinställning
sqlContextsom du kan använda för att köra frågor med Spark SQL.%%sqlinstruerar anteckningsboken att använda förinställningensqlContextför att köra frågan. Frågan hämtar de översta 10 raderna från en systemtabell som levereras med alla Azure Synapse Apache Spark-pooler som standard.Kör ytterligare en fråga för att visa data i
demo_df.%%sql SELECT * FROM demo_dfKoden genererar två utdataceller, en som innehåller dataresultat den andra, som visar jobbvyn.
Som standard visar resultatvyn ett rutnät. Men det finns en vyväxlare under rutnätet som gör att vyn kan växla mellan rutnäts- och grafvyer.

I växlaren Visa väljer du Diagram.
Välj ikonen Visa alternativ längst till höger.
I fältet Diagramtyp väljer du "stapeldiagram".
I kolumnfältet X-axel väljer du "tillstånd".
I kolumnfältet Y-axel väljer du "lön".
I fältet Sammansättning väljer du till "AVG".
Välj Använd.

Det går att få samma upplevelse av att köra SQL, men utan att behöva byta språk. Du kan göra detta genom att ersätta SQL-cellen ovan med den här PySpark-cellen. Utdataupplevelsen är densamma eftersom visningskommandot används:
display(spark.sql('SELECT * FROM demo_df'))Var och en av cellerna som tidigare kördes hade möjlighet att gå till Historikserver och Övervakning. Om du klickar på länkarna kommer du till olika delar av användarupplevelsen.
Anteckning
En del av den officiella Dokumentationen för Apache Spark förlitar sig på att använda Spark-konsolen, som inte är tillgänglig i Synapse Spark. Använd notebook- eller IntelliJ-upplevelserna i stället.
Rensa resurser
Azure Synapse sparar dina data i Azure Data Lake Storage. Du kan på ett säkert sätt låta en Spark-instans stängas av när den inte används. Du debiteras för en serverlös Apache Spark-pool så länge den körs, även om den inte används.
Eftersom avgifterna för poolen är många gånger högre än avgifterna för lagring är det ekonomiskt meningsfullt att låta Spark-instanser stängas av när de inte används.
För att säkerställa att Spark-instansen stängs av avslutar du alla anslutna sessioner (notebook-filer). Poolen stängs av när den inaktiva tid som anges i Apache Spark-poolen nås. Du kan också välja slutsession från statusfältet längst ned i anteckningsboken.
Nästa steg
I den här snabbstarten har du lärt dig hur du skapar en serverlös Apache Spark-pool och kör en grundläggande Spark SQL-fråga.