Grundlegendes zu Datenspeichermodellen
Moderne Geschäftssysteme müssen mit immer mehr heterogenen Daten zurechtkommen. Diese Vielschichtigkeit bedeutet, dass ein einzelner Datenspeicher in der Regel nicht die beste Wahl ist. Stattdessen ist es oft besser, verschiedene Arten von Daten in verschiedenen Datenspeichern abzulegen, die jeweils auf eine bestimmte Workload oder ein bestimmtes Nutzungsmuster abgestimmt sind. Der Begriff Polyglot Persistence (automatisierte Verwendung verschiedener Datenbanksysteme) wird verwendet, um Lösungen zu beschreiben, die eine Mischung aus Datenspeichertechnologien nutzen. Daher ist es wichtig, sich mit den hauptsächlich verwendeten Speichermodellen und ihren Vor- und Nachteilen vertraut zu machen.
Die Wahl des richtigen Datenspeichers für Ihre Anforderungen ist eine wichtige Entwurfsentscheidung. Es gibt buchstäblich Hunderte von Implementierungen, aus denen Sie unter SQL- und NoSQL-Datenbanken wählen können. Datenspeicher werden häufig nach der Strukturierung von Daten und den von ihnen unterstützten Betriebsarten kategorisiert. In diesem Artikel werden einige der gängigsten Speichermodelle beschrieben. Beachten Sie, dass eine bestimmte Datenspeichertechnologie mehrere Speichermodelle unterstützen kann. Beispielsweise kann ein Managementsystem für relationale Datenbanken (RDBMS) auch die Speicherung von Schlüsseln/Werten oder Diagrammen unterstützen. Tatsächlich gibt es einen allgemeinen Trend zur sogenannten Multimodell-Unterstützung, bei der ein einziges Datenbanksystem mehrere Modelle unterstützt. Aber dennoch ist es sinnvoll, mit verschiedenen Modelle allgemein vertraut zu sein.
Nicht alle Datenspeicher in einer bestimmten Kategorie bieten den gleichen Funktionsumfang. Die meisten Datenspeicher bieten serverseitige Funktionalität zur Abfrage und Verarbeitung von Daten. In einigen Fällen ist diese Funktionalität in die Datenspeicher-Engine integriert. In anderen Fällen sind die Funktionen zur Datenspeicherung und -verarbeitung getrennt, und es gibt möglicherweise mehrere Optionen für Verarbeitung und Analyse. Datenspeicher unterstützen auch verschiedene programmgesteuerte und Verwaltungsschnittstellen.
Grundsätzlich sollten Sie sich zunächst überlegen, welches Speichermodell für Ihre Anforderungen am besten geeignet ist. Ziehen Sie anschließend basierend auf Faktoren wie Funktionsumfang, Kosten und Verwaltbarkeit einen bestimmten Datenspeicher innerhalb dieser Kategorie in Betracht.
Hinweis
Weitere Informationen zum Identifizieren und Überprüfen Ihrer Datendienstanforderungen für die Cloudeinführung finden Sie im Microsoft Cloud Adoption Framework für Azure. Ebenso können Sie sich auch über die Auswahl von Speichertools und -diensten informieren.
Managementsysteme für relationale Datenbanken (RDBMS)
In relationalen Datenbanken werden Daten als eine Reihe zweidimensionaler Tabellen mit Zeilen und Spalten organisiert. Die meisten Anbieter bieten eine SQL-Variante (Structured Query Language) zum Abrufen und Verwalten von Daten. Ein RDBMS implementiert typischerweise einen transaktionskonsistenten Mechanismus, der dem ACID-Modell (Atomic, Consistent, Isolated, Durable [Atomarität, Konsistenz, Isolation, Dauerhaftigkeit]) zur Aktualisierung von Informationen entspricht.
Ein RDBMS unterstützt üblicherweise ein Schema-on-Write-Modell, bei dem die Datenstruktur vorab definiert wird und alle Lese- oder Schreibvorgänge das Schema verwenden müssen.
Dieses Modell ist sehr nützlich, wenn strenge Konsistenzgarantien wichtig sind, wo alle Änderungen atomar sind, und Transaktionen die Daten immer in einem konsistenten Zustand belassen. Ein RDBMS kann jedoch im Allgemeinen nicht aufskaliert werden, ohne dass die Daten horizontal partitioniert (Sharding) werden. Außerdem müssen die Daten in einem RDBMS normalisiert werden – ein Vorgang, der nicht für jedes Dataset geeignet ist.
Azure-Dienste
- Azure SQL-Datenbank | (Sicherheitsbaseline)
- Azure Database for MySQL | (Sicherheitsbaseline)
- Azure Database for PostgreSQL | (Sicherheitsbaseline)
- Azure Database for MariaDB | (S)
Workload
- Datensätze werden häufig erstellt und aktualisiert.
- Mehrere Vorgänge müssen in einer einzelnen Transaktion abgeschlossen werden.
- Beziehungen werden mithilfe von Datenbankeinschränkungen erzwungen.
- Die Abfrageleistung wird mithilfe von Indizes optimiert.
Datentyp
- Daten sind stark normalisiert.
- Datenbankschemas sind erforderlich und werden erzwungen.
- m:n-Beziehungen zwischen Datenentitäten in der Datenbank.
- Einschränkungen werden im Schema definiert und gelten für alle Daten in der Datenbank.
- Daten erfordern eine hohe Integrität. Indizes und Beziehungen müssen genau verwaltet werden.
- Daten erfordern eine starke Konsistenz. Transaktionen werden so durchgeführt, dass sichergestellt wird, dass alle Daten für alle Benutzer und Prozesse 100 % konsistent sind.
- Die Größe der einzelnen Dateneinträge ist gering bis mittelgroß.
Beispiele
- Bestandsverwaltung
- Auftragsverwaltung
- Reporting-Datenbank
- Buchhaltung
Schlüssel-Wert-Speicher
Ein Schlüssel-Wert-Speicher ordnet jedem Datenwert einen eindeutigen Schlüssel zu. Die meisten Schlüssel-Wert-Speicher unterstützen nur einfache Abfrage-, Einfüge- und Löschvorgänge. Um einen Wert (teilweise oder vollständig) zu modifizieren, muss eine Anwendung die vorhandenen Daten für den gesamten Wert überschreiben. Bei den meisten Implementierungen ist das Lesen oder Schreiben eines einzelnen Werts ein atomischer Vorgang.
Eine Anwendung kann beliebige Daten als einen Satz von Werten speichern. Die Anwendung muss alle Schemainformationen bereitstellen. Der Schlüssel-Wert-Speicher ruft den Wert einfach ab oder speichert ihn mithilfe des Schlüssels.
Schlüssel-Wert-Speicher sind in hohem Maß für Anwendungen optimiert, die einfache Nachschlagevorgänge durchführen, jedoch weniger geeignet, wenn Sie Daten aus verschiedenen Schlüssel-Wert-Speichern abfragen müssen. Schlüssel-Wert-Speicher sind auch nicht für Abfragen nach Wert optimiert.
Ein einziger Schlüssel-Wert-Speicher kann überaus skalierbar sein, da der Datenspeicher Daten problemlos auf mehrere Knoten auf getrennten Computern verteilen kann.
Azure-Dienste
- Azure Cosmos DB for Table und Azure Cosmos DB for NoSQL | (Sicherheitsbaseline für Azure Cosmos DB)
- Azure Cache for Redis | (Sicherheitsbaseline)
- Azure Table Storage | (Sicherheitsbaseline)
Workload
- Der Zugriff auf Daten erfolgt mithilfe eines einzigen Schlüssels, z. B. über ein Wörterbuch.
- Keine Verknüpfungen, Sperren oder Unions sind erforderlich.
- Keine Aggregationsmechanismen werden verwendet.
- Sekundäre Indizes werden generell nicht verwendet.
Datentyp
- Jeder Schlüssel ist einem einzelnen Wert zugeordnet.
- Keine Schemas werden erzwungen.
- Keine Beziehungen zwischen Entitäten.
Beispiele
- Zwischenspeichern von Daten
- Sitzungsverwaltung
- Benutzereinstellungs- und Benutzerprofilverwaltung
- Produktempfehlungen und Ad-Serving
Dokumentdatenbanken
In einer Dokumentdatenbank wird eine Sammlung von Dokumenten gespeichert, wobei jedes Dokument aus benannten Feldern und Daten besteht. Bei den Daten kann es sich um einfache Werte oder komplexe Elemente wie Listen oder untergeordnete Sammlungen handeln. Dokumente werden anhand von eindeutigen Schlüsseln abgerufen.
In der Regel enthält ein Dokument die Daten für eine einzelne Entität, z. B. einen Kunden oder eine Bestellung. Ein Dokument kann Informationen enthalten, die auf mehrere relationale Tabellen in einem RDBMS verteilt sind. Die Dokumente müssen nicht dieselbe Struktur aufweisen. Anwendungen können unterschiedliche Daten in Dokumenten speichern, wenn sich die Geschäftsanforderungen ändern.

Azure-Dienst
Workload
- Einfüge- und Aktualisierungsvorgänge werden häufig durchgeführt.
- Keine objektrelationalen Impedanzabweichungen. Dokumente können besser mit den im Anwendungscode verwendeten Objektstrukturen abgeglichen werden.
- Einzelne Dokumente werden abgerufen und als einzelner Block geschrieben.
- Für die Daten ist ein Index für mehrere Felder erforderlich.
Datentyp
- Daten können auf denormalisierte Weise verwaltet werden.
- Die Größe der einzelnen Dokumentdaten ist relativ gering.
- Für jeden Dokumenttyp kann ein eigenes Schema verwendet werden.
- Dokumente können optionale Felder enthalten.
- Dokumentdaten sind teilweise strukturiert, d.h., die Datentypen der einzelnen Felder sind nicht streng definiert.
Beispiele
- Produktkatalog
- Content Management
- Bestandsverwaltung
Graphdatenbanken
In einer Diagrammdatenbank werden zwei Arten von Informationen gespeichert: Knoten und Edges. Edges geben die Beziehungen zwischen Knoten an. Knoten und Edges können Eigenschaften haben, die ähnlich wie Spalten in einer Tabelle Informationen zum Knoten oder Edge bereitstellen. Edges können auch eine Richtung haben, die die Art der Beziehung angibt.
Graphdatenbanken können Abfragen über das Netzwerk von Knoten und Edges effizient ausführen und die Beziehungen zwischen Entitäten analysieren. Das folgende Diagramm zeigt die Personaldatenbank einer Organisation in grafischer Form. Die Entitäten sind Mitarbeiter und Abteilungen, und die Edges zeigen die Hierarchiebeziehungen und Abteilungen der Mitarbeiter.
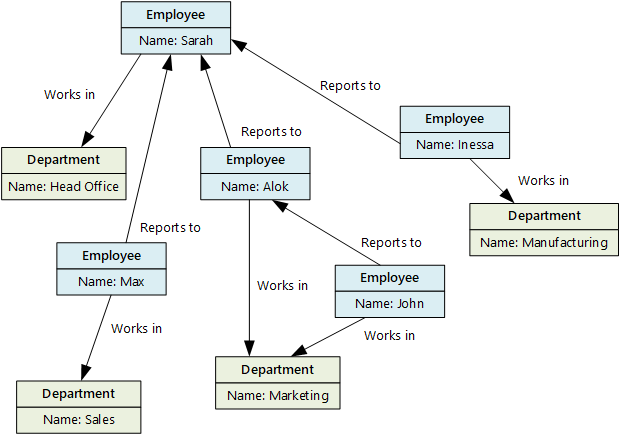
Diese Struktur macht es einfach, Abfragen wie „Alle Mitarbeiter*innen finden, die Sarah direkt oder indirekt unterstellt sind“ oder „Wer arbeitet in derselben Abteilung wie John?“ auszuführen. Bei großen Diagrammen mit vielen Entitäten und Beziehungen können Sie sehr komplexe Analysen sehr schnell durchführen. Viele Diagrammdatenbanken bieten eine Abfragesprache, mit der Sie ein Beziehungsnetz effizient durchlaufen können.
Azure-Dienste
Workload
- Komplexe Beziehungen zwischen Datenelementen mit vielen Hops zwischen den zugehörigen Datenelementen.
- Die Beziehungen zwischen Datenelementen sind dynamisch und ändern sich mit der Zeit.
- Beziehungen zwischen Objekten sind bevorzugte Beziehungen, bei denen keine Fremdschlüssel und Verknüpfungen durchlaufen werden müssen.
Datentyp
- Knoten und Beziehungen.
- Knoten ähneln Tabellenzeilen oder JSON-Dokumenten.
- Beziehungen sind genau so wichtig wie Knoten und werden direkt in der Abfragesprache verfügbar gemacht.
- Zusammengesetzte Objekte, z.B. eine Person mit mehreren Telefonnummern, werden meist in separate kleinere Knoten unterteilt und mit durchlaufbaren Beziehungen kombiniert.
Beispiele
- Organigramme
- Social Graphs
- Betrugserkennung
- Empfehlungs-Engines
Datenanalysen
Datenanalysespeicher bieten massiv parallele Lösungen für die Erfassung, Speicherung und Analyse von Daten. Die Daten werden auf mehrere Server verteilt, um die Skalierbarkeit zu maximieren. Bei der Datenanalyse werden sehr oft Formate für große Datendateien wie z. B. Dateien mit Trennzeichen (CSV), Parquet- und ORC-Dateien verwendet. Verlaufsdaten werden in der Regel in Datenspeichern wie Blob Storage oder Azure Data Lake Storage Gen2 gespeichert, auf die dann von Azure Synapse, Databricks oder HDInsight als externe Tabellen zugegriffen wird. Ein typisches Szenario, bei dem Daten verwendet werden, die aus Leistungsgründen als Parquet-Dateien gespeichert werden, ist im Artikel Verwenden externer Tabellen mit Synapse SQL beschrieben.
Azure-Dienste
- Azure Synapse Analytics | (Sicherheitsbaseline)
- Azure Data Lake | (Sicherheitsbaseline)
- Azure Data Explorer | (Sicherheitsbaseline)
- Azure Analysis Services
- HDInsight | (Sicherheitsbaseline)
- Azure Databricks | (Sicherheitsbaseline)
Workload
- Datenanalysen
- Enterprise BI
Datentyp
- Verlaufsdaten aus mehreren Quellen.
- In der Regel denormalisiert in einem „Stern“- oder „Schneeflocken“-Schema, das aus Fakten- und Dimensionstabellen besteht.
- Wird normalerweise mit neuen Daten auf Basis eines Zeitplans geladen.
- Dimensionstabellen enthalten häufig mehrere Verlaufsversionen einer Entität, die als langsam veränderliche Dimension bezeichnet wird.
Beispiele
- Data Warehouse für Unternehmen
Spaltenfamilien-Datenbanken
In einer Spaltenfamilien-Datenbank sind Daten in Zeilen und Spalten organisiert. In ihrer einfachsten Form kann eine Spaltenfamilien-Datenbank zumindest konzeptionell einer relationalen Datenbank sehr ähnlich erscheinen. Die eigentliche Stärke einer SpaltenfamilienFamily-Datenbank liegt in ihrem denormalisierten Ansatz zur Strukturierung von Daten mit geringer Dichte.
Sie können sich eine Spaltenfamilien-Datenbank als eine Datenbank mit tabellarischen Daten in Zeilen und Spalten vorstellen, wobei die Spalten in Gruppen unterteilt sind, die als Spaltenfamilien bezeichnet werden. Jede Spaltenfamilie enthält eine Reihe von Spalten, die logisch miteinander verknüpft sind und typischerweise als Einheit abgerufen oder bearbeitet werden. Andere Daten, auf die separat zugegriffen wird, können in separaten Spaltenfamilien gespeichert werden. Innerhalb einer Spaltenfamilie können neue Spalten dynamisch hinzugefügt werden, und Zeilen müssen nicht für jede Spalte einen Wert aufweisen.
Das folgende Diagramm zeigt ein Beispiel mit zwei Spaltenfamilien, Identity und Contact Info. Die Daten für eine einzelne Entität haben in jeder Spaltenfamilie den gleichen Zeilenschlüssel. Diese Struktur, bei der die Zeilen für ein beliebiges Objekt in einer Spaltenfamilie dynamisch variieren können, ist ein wichtiger Vorteil des Spaltenfamilienansatzes. Dadurch eignet sich diese Form der Datenspeicherung hervorragend für die Speicherung strukturierter, flüchtiger Daten.

Im Gegensatz zu einem Schlüssel-Wert-Speicher oder einer Dokumentendatenbank speichern die meisten Spaltenfamilien-Datenbanken Daten in Schlüsselreihenfolge und nicht durch die Berechnung eines Hashwerts. Viele Implementierungen erlauben, Indizes über bestimmte Spalten einer Spaltenfamilien zu erstellen. Indizes ermöglichen Ihnen, Daten nach Spaltenwert statt nach Zeilenschlüssel abzurufen.
Lese- und Schreibvorgänge für eine Zeile sind in der Regel mit einer einzigen Spaltenfamilien atomisch, obwohl einige Implementierungen Atomarität über die gesamte Zeile bieten und mehrere Spaltenfamilien umfassen.
Azure-Dienste
- Azure Cosmos DB for Apache Cassandra | (Sicherheitsbaseline)
- HBase in HDInsight | (Sicherheitsbaseline)
Workload
- In den meisten Column-Family-Datenbanken werden Schreibvorgänge extrem schnell durchgeführt.
- Aktualisierungs- und Löschvorgänge sind selten.
- Bietet Zugriff mit hohem Durchsatz und niedriger Latenz.
- Unterstützt den einfachen Abfragezugriff auf eine bestimmte Gruppe von Feldern in einem wesentlich größeren Datensatz.
- Extrem skalierbar.
Datentyp
- Daten werden in Tabellen gespeichert, die aus einer Schlüsselspalte und einer oder mehreren Spaltenfamilien bestehen.
- Bestimmte Spalten können nach einzelnen Zeilen variieren.
- Der Zugriff auf einzelne Zellen erfolgt über get- und put-Befehle.
- Mehrere Zeilen werden unter Verwendung eines scan-Befehls zurückgegeben.
Beispiele
- Empfehlungen
- Personalisierung
- Sensordaten
- Telemetrie
- Nachrichten
- Analysen sozialer Medien
- Webanalysen
- Aktivitätsüberwachung
- Wetter- und andere Zeitreihendaten
Suchmaschinen-Datenbanken
Eine Suchmaschinen-Datenbank ermöglicht Anwendungen die Suche nach Informationen, die sich in externen Datenspeichern befinden. Eine Suchmaschinen-Datenbank kann riesige Datenmengen indizieren und einen Zugriff in nahezu Echtzeit auf diese Indizes ermöglichen.
Indizes können mehrdimensional sein und Freitextsuchen über große Mengen von Textdaten unterstützen. Die Indizierung kann mithilfe eines Pullmodells erfolgen, das von der Suchmaschinen-Datenbank ausgelöst wird, oder mit Hilfe eines Pushmodells, das durch externen Anwendungscode ausgelöst wird.
Suchen können genau oder unscharf sein. Eine unscharfe Suche findet Dokumente, die mit einer Reihe von Begriffen übereinstimmen, und berechnet, wie genau diese übereinstimmen. Einige Suchmaschinen unterstützen auch linguistische Analysen, die Treffer auf der Basis von Synonymen, Gattungserweiterungen (z.B. Abgleich von dogs mit pets) und Wortstammerkennung (Abgleich von Wörtern mit demselben Wortstamm) liefern können.
Azure-Dienst
Workload
- Datenindizes aus mehreren Quellen und Diensten.
- Abfragen werden ad hoc durchgeführt und können komplex sein.
- Volltextsuche ist erforderlich.
- Ad-hoc-Self-Service-Abfragen sind erforderlich.
Datentyp
- Teilweise strukturierter oder unstrukturierter Text
- Text mit Verweis auf strukturierte Daten
Beispiele
- Produktkataloge
- Websitesuche
- Protokollierung
Zeitreihendatenbanken
Bei Zeitreihendaten handelt es sich um eine nach Zeit strukturierte Gruppe von Werten. Zeitreihen-Datenbanken sammeln typischerweise große Datenmengen in Echtzeit von einer großen Anzahl von Quellen. Aktualisierungen sind selten, und Löschvorgänge erfolgen oft als Massenvorgänge. Die Datensätze, die in eine Zeitreihen-Datenbank geschrieben werden, sind zwar in der Regel klein, ihre Anzahl ist jedoch häufig groß, sodass die Gesamtdatenmenge schnell zunehmen kann.
Azure-Dienst
Workload
- Datensätze werden generell sequenziell in zeitlicher Reihenfolge angefügt.
- Der überwiegende Anteil der Vorgänge sind Schreibvorgänge (95 bis 99%).
- Aktualisierungen sind selten.
- Löschvorgänge werden massenweise und in zusammenhängenden Blöcken oder Datensätzen durchgeführt.
- Die Daten werden sequenziell in aufsteigender oder absteigender zeitlicher Reihenfolge und oftmals parallel gelesen.
Datentyp
- Ein Zeitstempel wird als primärer Schlüssel und Sortiermechanismus verwendet.
- Mit Tags werden zusätzliche Informationen zum Typ oder Ursprung sowie andere Informationen zum Eintrag definiert.
Beispiele
- Überwachungs- und Ereignistelemetrie
- Sensor- oder andere IoT-Daten
Objektspeicher
Ein Objektspeicher ist optimiert für das Speichern und Abrufen großer binärer Objekte (Bilder, Dateien, Video- und Audiostreams, große Anwendungsdatenobjekte und -dokumente, VM-Datenträgerimages). In diesem Modell werden außerdem vielfach große Datendateien verwendet, z. B. Dateien mit Trennzeichen (CSV), Parquet- und ORC-Dateien. Objektspeicher können extrem große Mengen unstrukturierter Daten verwalten.
Azure-Dienst
Workload
- Identifizierung erfolgt nach Schlüssel.
- Inhalte sind normalerweise Ressourcen, z. B. ein Trennzeichen, ein Bild oder eine Videodatei.
- Inhalte müssen dauerhaft sein und sich außerhalb von Logikschichten befinden.
Datentyp
- Die Datengröße ist umfangreich.
- Wert ist nicht transparent.
Beispiele
- Bilder, Videos, Office-Dokumente, PDF-Dateien
- Statisches HTML, JSON, CSS
- Protokoll- und Überwachungsdateien
- Datenbanksicherungen
Freigegebene Dateien
Mitunter kann die Verwendung einfacher Flatfiles das effektivste Mittel zum Speichern und Abrufen von Informationen sein. Der Einsatz von Dateifreigaben ermöglicht den Zugriff auf Dateien über ein Netzwerk. Bei entsprechenden Sicherheits- und Kontrollmechanismen für den gleichzeitigen Zugriff kann die gemeinsame Nutzung von Daten auf diese Weise verteilten Diensten Folgendes ermöglichen: einen überaus skalierbaren Datenzugriff zur Durchführung grundlegender, allgemeiner Vorgänge wie beispielsweise einfacher Lese- und Schreibvorgänge.
Azure-Dienst
Workload
- Migration aus vorhandenen Apps, die mit dem Dateisystem interagieren.
- Erfordert eine SMB-Schnittstelle.
Datentyp
- Dateien in einer hierarchischen Gruppe von Ordnern.
- Zugänglich über E/A-Standardbibliotheken.
Beispiele
- Legacydateien
- Freigegebener Inhalt zugänglich innerhalb verschiedener virtueller Computer oder App-Instanzen
Wenn Sie die verschiedenen Datenspeichermodelle verstanden haben, sollten Sie im nächsten Schritt die Workload und Anwendung auswerten und entscheiden, welcher Datenspeicher Ihren speziellen Anforderungen am besten entspricht. Verwenden Sie dabei als Hilfe die Entscheidungsstruktur für Datenspeicher.
Nächste Schritte
- Azure Cloud Storage-Lösungen und -Dienste
- Überprüfen Ihrer Speicheroptionen
- Einführung in Azure Storage
- Einführung in Azure Data Explorer
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für