Diese Referenzarchitektur zeigt eine Reihe bewährter Methoden zum Ausführen einer n-schichtigen Anwendung in mehreren Azure-Regionen, um Verfügbarkeit und eine stabile Infrastruktur für die Notfallwiederherstellung zu erzielen.
Aufbau
Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
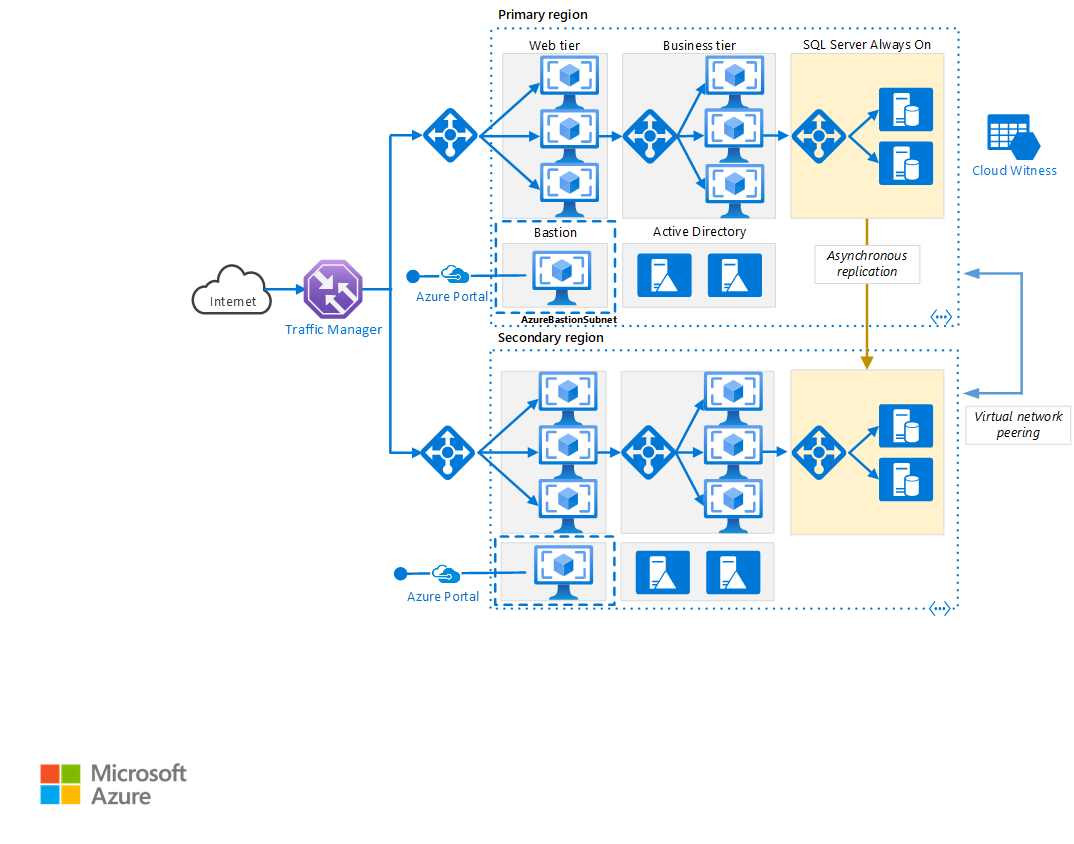
Primäre und sekundäre Regionen. Verwenden Sie zwei Regionen, um eine höhere Verfügbarkeit zu erreichen. Eine ist die primäre Region. Die andere Region ist für das Failover.
Azure Traffic Manager. Traffic Manager leitet eingehende Anforderungen an eine der Regionen weiter. Während des normalen Betriebs werden Anforderungen an die primäre Region weitergeleitet. Wenn diese Region nicht mehr verfügbar ist, führt Traffic Manager ein Failover zur sekundären Region aus. Weitere Informationen finden Sie im Abschnitt Traffic Manager-Konfiguration.
Ressourcengruppen: Erstellen Sie separate Ressourcengruppen für die primäre Region, die sekundäre Region und für Traffic Manager. Diese Methode bietet Ihnen die Flexibilität, jede Region als eine einzelne Ressourcensammlung zu verwalten. Sie können beispielsweise eine Region erneut bereitstellen, ohne die andere außer Betrieb zu nehmen. Verknüpfen Sie die Ressourcengruppen, damit Sie eine Abfrage zum Auflisten aller Ressourcen für die Anwendung ausführen können.
Virtuelle Netzwerke. Erstellen Sie für jede Region ein separates virtuelles Netzwerk. Stellen Sie sicher, dass sich die Adressräume nicht überschneiden.
SQL Server Always On-Verfügbarkeitsgruppe. Bei Verwendung von SQL Server werden SQL Always On-Verfügbarkeitsgruppen empfohlen, um Hochverfügbarkeit zu erzielen. Erstellen Sie eine einzelne Verfügbarkeitsgruppe, die SQL Server-Instanzen in beiden Regionen enthält.
Hinweis
Ziehen Sie auch eine Azure SQL-Datenbank in Betracht, die eine relationale Datenbank als Clouddienst bereitstellt. Mit einer SQL-Datenbank müssen Sie weder eine Verfügbarkeitsgruppe konfigurieren noch das Failover verwalten.
Peering virtueller Netzwerke. Konfigurieren Sie ein Peering der zwei virtuellen Netzwerke, um eine Datenreplikation von der primären Region zur sekundären Region zuzulassen. Weitere Informationen finden Sie unter Peering in virtuellen Netzwerken.
Komponenten
- Verfügbarkeitsgruppen sorgen dafür, dass die von Ihnen in Azure bereitgestellten virtuellen Computer auf mehrere isolierte Hardwareknoten in einem Cluster verteilt werden. Dadurch wirken sich Hardware- oder Softwarefehler in Azure nur auf einen Teil Ihrer virtuellen Computer aus, und Ihre Lösung bleibt insgesamt verfügbar und betriebsbereit.
- Verfügbarkeitszonen schützen Ihre Anwendungen und Daten vor Datencenterausfällen. Bei Verfügbarkeitszonen handelt es sich um separate physische Standorte in einer Azure-Region. Jede Zone besteht aus mindestens einem Datencenter mit eigener Stromversorgung, Kühlung und Netzwerk.
- Azure Traffic Manager ist ein DNS-basierter Lastenausgleich, der Datenverkehr optimal verteilt. Er bietet Dienste in Azure-Regionen auf der ganzen Welt, bei gleichzeitiger Hochverfügbarkeit und guter Reaktionsfähigkeit.
- Azure Load Balancer verteilt eingehenden Datenverkehr auf der Grundlage von definierten Regeln und Integritätstests. Ein Load Balancer sorgt für kurze Wartezeiten und hohen Durchsatz und kann auf Millionen von Flows für alle TCP- und UDP-Anwendungen skalieren. In diesem Szenario wird ein öffentlicher Lastenausgleich verwendet, um eingehenden Clientdatenverkehr auf der Webebene zu verteilen. Außerdem wird in diesem Szenario ein interner Lastenausgleich verwendet, um Datenverkehr von der Geschäftsebene auf den SQL Server-Back-End-Cluster zu verteilen.
- Azure Bastion bietet sichere RDP- und SSH-Verbindungen mit allen virtuellen Computern in dem virtuellen Netzwerk, in dem der Dienst bereitgestellt wird. Durch die Verwendung von Azure Bastion wird verhindert, dass Ihre virtuellen Computer RDP- und SSH-Ports öffentlich verfügbar machen. Gleichzeitig wir weiterhin der sichere Zugriff per RDP/SSH ermöglicht.
Empfehlungen
Eine Architektur mit mehreren Regionen kann eine höhere Verfügbarkeit als eine Bereitstellung in einer einzelnen Region bieten. Wenn ein regionaler Ausfall die primäre Region beeinträchtigt, können Sie mit Traffic Manager ein Failover zur sekundären Region ausführen. Diese Architektur kann auch hilfreich sein, wenn bei einem einzelnen Subsystem der Anwendung ein Fehler auftritt.
Es gibt mehrere allgemeine Vorgehensweisen für das Erreichen von Hochverfügbarkeit mit mehreren Regionen:
- Aktiv/passiv mit Hot Standby. Der Datenverkehr wird an eine Region weitergeleitet, während die andere im Hot Standby wartet. „Unmittelbar betriebsbereit“ (Hot Standby) bedeutet, dass die virtuellen Computer in der sekundären Region jederzeit zugeordnet sind und immer ausgeführt werden.
- Aktiv/passiv mit Cold Standby. Der Datenverkehr wird an eine Region weitergeleitet, während die andere im Cold Standby wartet. „Verzögert betriebsbereit“ (Cold Standby) bedeutet, dass die VMs in der sekundären Region erst zugeordnet werden, wenn sie für das Failover benötigt werden. Dieser Ansatz erfordert weniger Ausführungszeit, es dauert aber im Allgemeinen länger, bis bei einem Ausfall alle Komponenten online geschaltet sind.
- Aktiv/aktiv. Beide Regionen sind aktiv, und Anforderungen werden per Lastenausgleich zwischen ihnen verteilt. Wenn eine Region nicht mehr verfügbar ist, wird sie aus der Rotation genommen.
In dieser Referenzarchitektur liegt der Fokus auf aktiv/passiv mit Hot Standby, wobei Traffic Manager für das Failover verwendet wird. Sie können ein paar virtuelle Computer für Hot Standby bereitstellen und dann nach Bedarf aufskalieren.
Regionspaare
Jede Azure-Region ist mit einer anderen Region innerhalb desselben Gebiets gepaart. Sie wählen im Allgemeinen Regionen aus dem gleichen Regionspaar aus (z.B. „USA, Osten 2“ und „USA, Mitte“). Das bietet die folgenden Vorteile:
- Bei einem umfassenden Ausfall wird die Wiederherstellung mindestens einer Region aus jedem Paar priorisiert.
- Geplante Azure-Systemupdates werden in Regionspaaren nacheinander ausgeführt, um mögliche Ausfallzeiten zu minimieren.
- Regionspaare befinden sich innerhalb des gleichen geografischen Gebiets, um Anforderungen in Bezug auf den Datenspeicherort zu erfüllen.
Sie sollten allerdings sicherstellen, dass beide Regionen alle Azure-Dienste unterstützen, die für Ihre Anwendung erforderlich sind (siehe Dienste nach Region). Weitere Informationen zu Regionspaaren finden Sie unter Geschäftskontinuität und Notfallwiederherstellung: Azure-Regionspaare.
Traffic Manager-Konfiguration
Beachten Sie beim Konfigurieren von Traffic Manager die folgenden Punkte:
- Routing: Traffic Manager unterstützt mehrere Routingalgorithmen. Verwenden Sie für das in diesem Artikel beschriebenen Szenario Routing nach Priorität (ehemals Routingmethode Failover). Bei dieser Einstellung sendet Traffic Manager alle Anforderungen an die primäre Region, bis die primäre Region nicht mehr erreichbar ist. Zu diesem Zeitpunkt wird automatisch ein Failover zur sekundären Region ausgeführt. Weitere Informationen finden Sie unter Konfigurieren der Routingmethode „Failover“.
- Integritätstest: Traffic Manager verwendet einen HTTP- oder HTTPS-Test, um die Verfügbarkeit jeder Region zu überwachen. Der Test prüft auf eine HTTP 200-Antwort für einen angegebenen URL-Pfad. Es hat sich bewährt, einen Endpunkt zu erstellen, der die Gesamtintegrität der Anwendung meldet, und diesen Endpunkt für den Integritätstest zu verwenden. Andernfalls meldet der Test eventuell einen fehlerfreien Endpunkt, obwohl wichtige Teile der Anwendung fehlerhaft sind. Weitere Informationen finden Sie unter Überwachungsmuster für den Integritätsendpunkt.
Wenn Traffic Manager ein Failover ausführt, können die Clients die Anwendung für eine bestimmte Zeit nicht erreichen. Die Dauer wird durch folgende Faktoren beeinflusst:
- Der Integritätstest muss erkennen, dass die primäre Region nicht erreichbar ist.
- Die DNS-Server müssen die zwischengespeicherten DNS-Einträge für die IP-Adresse aktualisieren, die von der DNS-Gültigkeitsdauer (TTL) abhängig ist. Die Standardgültigkeitsdauer beträgt 300 Sekunden (5 Minuten), Sie können diesen Wert aber bei der Erstellung des Traffic Manager-Profils anpassen.
Weitere Informationen finden Sie unter Traffic Manager-Überwachung.
Bei Failovern durch Traffic Manager sollten Sie ein manuelles Failback ausführen, anstatt ein automatisches Failback zu implementieren. Andernfalls könnte eine Situation eintreten, bei der die Anwendung zwischen den Regionen hin und her wechselt. Überprüfen Sie vor einem Failback, ob alle Subsysteme der Anwendung fehlerfrei sind.
Traffic Manager führt in der Standardeinstellung automatisch Failbacks aus. Um dieses Problem zu verhindern, verringern Sie die Priorität der primären Region nach einem Failover manuell. Angenommen, die primäre Region hat die Priorität 1 und die sekundäre Datenbank die Priorität 2. Nach einem Failover legen Sie dann die Priorität der primären Region auf 3 fest, um ein automatisches Failback zu verhindern. Wenn Sie wieder zurückwechseln möchten, ändern Sie die Priorität wieder in 1.
Mit dem folgenden Befehl für die Azure-Befehlszeilenschnittstelle wird die Priorität aktualisiert:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
Ein anderer Ansatz besteht darin, den Endpunkt vorübergehend zu deaktivieren, bis Sie zum Ausführen eines Failbacks bereit sind:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
Je nach Ursache eines Failovers müssen Sie die Ressourcen innerhalb einer Region möglicherweise erneut bereitstellen. Testen Sie vor dem Failback die Betriebsbereitschaft. Beim Test sollten z.B. folgende Punkte geprüft werden:
- Virtuelle Computer sind richtig konfiguriert. (Alle erforderliche Software ist installiert, IIS wird ausgeführt usw.)
- Subsysteme der Anwendung sind fehlerfrei.
- Funktionstests. (Beispielsweise, dass die Datenbankebene von der Webebene aus erreichbar ist.)
Konfigurieren von SQL Server Always On-Verfügbarkeitsgruppen
Bei früheren Versionen als Windows Server 2016 erfordern SQL Server Always On-Verfügbarkeitsgruppen einen Domänencontroller, und alle Knoten in der Verfügbarkeitsgruppe müssen sich in der gleichen Active Directory (AD)-Domäne befinden.
So konfigurieren Sie die Verfügbarkeitsgruppe:
Platzieren Sie mindestens zwei Domänencontroller in jeder Region.
Weisen Sie jedem Domänencontroller eine statische IP-Adresse zu.
Konfigurieren Sie ein Peering der zwei virtuellen Netzwerke, um eine Kommunikation zwischen ihnen zu ermöglichen.
Fügen Sie für jedes virtuelle Netzwerk die IP-Adressen der Domänencontroller (beider Regionen) zur DNS-Serverliste hinzu. Sie können den folgenden CLI-Befehl verwenden. Weitere Informationen finden Sie unter Ändern von DNS-Servern.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Erstellen Sie einen Windows Server-Failovercluster (WSFC), der die SQL Server-Instanzen in beiden Regionen enthält.
Erstellen Sie eine SQL Server Always On-Verfügbarkeitsgruppe, die SQL Server-Instanzen sowohl in der primären als auch der sekundären Region enthält. Die Schritte finden Sie unter Erweitern der Always On-Verfügbarkeitsgruppe auf ein Azure-Remoterechenzentrum (PowerShell).
Legen Sie das primäre Replikat in der primären Region ab.
Legen Sie ein oder mehrere sekundäre Replikate in der primären Region ab. Konfigurieren Sie diese Replikate für die Verwendung synchroner Commits mit automatischem Failover.
Legen Sie ein oder mehrere sekundäre Replikate in der sekundären Region ab. Konfigurieren Sie diese Replikate aus Leistungsgründen für die Verwendung asynchroner Commits. (Andernfalls müssen alle T-SQL-Transaktionen auf einem Roundtrip über das Netzwerk zur sekundären Region warten.)
Hinweis
Replikate mit asynchronem Commit unterstützen kein automatisches Failover.
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Verfügbarkeit
Bei einer komplexen n-schichtigen Anwendung müssen Sie möglicherweise nicht die gesamte Anwendung in der sekundären Region replizieren. Stattdessen replizieren Sie nur ein kritisches Subsystem, das zur Unterstützung der Geschäftskontinuität erforderlich ist.
Traffic Manager ist eine mögliche Schwachstelle im System. Wenn beim Traffic Manager-Dienst ein Fehler auftritt, können Clients während der Ausfallzeit nicht auf Ihre Anwendung zugreifen. In der Vereinbarung zum Servicelevel (SLA) für Traffic Manager erfahren Sie, ob Ihre geschäftlichen Anforderungen für Hochverfügbarkeit mit Traffic Manager allein erfüllt werden. Wenn dies nicht der Fall ist, erwägen Sie als Failback eine andere Verwaltungslösung für den Datenverkehr. Wenn der Azure Traffic Manager-Dienst fehlerhaft ist, ändern Sie die CNAME-Einträge im DNS so, dass diese auf die andere Verwaltungslösung für den Datenverkehr verweisen. (Dieser Schritt muss manuell durchgeführt werden. Bis die DNS-Änderungen weitergegeben wurden, ist die Anwendung nicht verfügbar.)
Für den SQL Server-Cluster sind zwei Failoverszenarien zu berücksichtigen:
Bei allen SQL Server-Datenbankreplikaten in der primären Region treten Fehler auf. Dieser Fehler kann z. B. während eines regionalen Ausfalls auftreten. In diesem Fall müssen Sie für die Verfügbarkeitsgruppe ein manuelles Failover ausführen, obwohl Traffic Manager automatisch ein Failover auf dem Front-End ausführt. Führen Sie die Schritte unter Ausführen eines erzwungenen manuellen Failovers einer SQL Server-Verfügbarkeitsgruppe aus, in denen beschrieben ist, wie ein erzwungenes Failover mithilfe von SQL Server Management Studio, Transact-SQL oder PowerShell in SQL Server 2016 ausgeführt wird.
Warnung
Bei einem erzwungenem Failover besteht das Risiko eines Datenverlusts. Sobald die primäre Region wieder online ist, erstellen Sie eine Momentaufnahme der Datenbank, und verwenden Sie tablediff, um die Unterschiede zu ermitteln.
Traffic Manager führt ein Failover zur sekundären Region aus, doch ist das primäre SQL Server-Datenbankreplikat weiterhin verfügbar. So kann beispielsweise die Front-End-Ebene fehlgeschlagen, ohne dass dies Auswirkungen auf die virtuellen SQL Server-Computer hat. In diesem Fall wird der Internetdatenverkehr an die sekundäre Region weitergeleitet, und diese Region kann immer noch eine Verbindung mit dem primären Replikat herstellen. Es kommt jedoch zu erhöhter Latenz, da die SQL Server-Verbindungen regionsübergreifend verlaufen. In dieser Situation sollten Sie auf folgende Weise ein manuelles Failover ausführen:
- Wechseln Sie bei einem SQL Server-Datenbankreplikat in der sekundären Region vorübergehend zu synchronen Commits. Durch diesen Schritt wird sichergestellt, dass während des Failovers kein Datenverlust auftritt.
- Führen Sie ein Failover zu diesem Replikat aus.
- Wenn Sie ein Failback zur primären Region ausführen, ändern Sie die Einstellung wieder in asynchrone Commits.
Verwaltbarkeit
Beim Aktualisieren der Bereitstellung aktualisieren Sie immer jeweils eine Region, um die Möglichkeit eines globalen Fehlers aufgrund einer falschen Konfiguration oder eines Fehlers in der Anwendung zu reduzieren.
Testen Sie die Resilienz des Systems gegenüber Fehlern. Hier sind einige häufige Fehlerszenarien aufgeführt, die getestet werden können:
- Herunterfahren von VM-Instanzen
- Auslasten von Ressourcen, z.B. CPU und Speicher
- Trennen/Verzögern des Netzwerks
- Absturz von Prozessen
- Ablauf von Zertifikaten
- Simulieren von Hardwarefehlern
- Herunterfahren des DNS-Diensts auf den Domänencontrollern
Messen Sie die Wiederherstellungszeiten, und stellen Sie sicher, dass diese Ihren geschäftlichen Anforderungen entsprechen. Testen Sie auch Kombinationen von Fehlermodi.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Verwenden Sie den Azure-Preisrechner, um die Kosten zu ermitteln. Hier finden Sie einige weitere Überlegungen dazu.
Virtual Machine Scale Sets
VM-Skalierungsgruppen sind für alle Windows-VM-Größen verfügbar. Ihnen werden nur die Azure-VMs in Rechnung gestellt, die Sie bereitstellen, sowie alle zusätzlich genutzten zugrunde liegenden Infrastrukturressourcen, z. B. Speicher und Netzwerk. Für den VM-Skalierungsgruppendienst fallen keine inkrementellen Gebühren an.
Preisoptionen für einzelne VMS finden Sie unter Virtuelle Windows-Computer – Preise.
Datenbank importieren
Wenn Sie Azure SQL DBaas auswählen, können Sie Kosten sparen, da Sie keine Always On-Verfügbarkeitsgruppen und Domänencontrollercomputer konfigurieren müssen. Es gibt mehrere Bereitstellungsoptionen, beginnend mit einer einzelnen Datenbank bis hin zu einer verwalteten Instanz oder Pools für elastische Datenbanken. Weitere Informationen finden Sie in der Azure-Preisübersicht.
Die Preisoptionen für virtuelle SQL Server-Computer finden Sie unter Preisübersicht für SQL-VMs.
Load Balancer
Die Gebühren werden nur anhand der Anzahl von konfigurierten Lastenausgleichsregeln und Ausgangsregeln berechnet. Für NAT-Regeln für eingehenden Datenverkehr fallen keine Gebühren an. Für Load Balancer Standard fallen keine Kosten auf Stundenbasis an, wenn keine Regeln konfiguriert sind.
Traffic Manager – Preise
Die Abrechnung für Traffic Manager basiert auf der Anzahl von empfangenen DNS-Abfragen. Für Dienste, die über eine Milliarde Abfragen pro Monat empfangen, gibt es einen Rabatt. Ihnen werden außerdem alle überwachten Endpunkte in Rechnung gestellt.
Weitere Informationen finden Sie im Abschnitt zu Kosten im Microsoft Azure Well-Architected Framework.
Preise für VNET-Peering
Bei einer Hochverfügbarkeitsbereitstellung mit mehreren Azure-Regionen wird das VNET-Peering genutzt. Für VNET-Peering innerhalb der gleichen Region und für globales VNET-Peering fallen jeweils unterschiedliche Gebühren an.
Weitere Informationen finden Sie unter Virtual Network – Preise.
DevOps
Sie benötigen nur eine Azure Resource Manager-Vorlage, um die Azure-Ressourcen und die zugehörigen Abhängigkeiten bereitzustellen. Verwenden Sie dieselbe Vorlage, um die Ressourcen sowohl in der primären als auch in der sekundären Region bereitzustellen. Nehmen Sie alle Ressourcen in dasselbe virtuelle Netzwerk auf, sodass sie in derselben grundlegenden Workload isoliert sind. Durch die Aufnahme aller Ressourcen erleichtern Sie die Zuordnung der spezifischen Ressourcen der Workload zu einem DevOps-Team, damit das Team unabhängig alle Aspekte dieser Ressourcen verwalten kann. Diese Isolation ermöglicht DevOps-Teams und -Diensten die Durchführung von Continuous Integration- und Continuous Delivery-Vorgängen (CI/CD).
Außerdem können Sie verschiedene Azure Resource Manager-Vorlagen verwenden und in Azure DevOps Services integrieren, um in wenigen Minuten unterschiedliche Umgebungen bereitzustellen. Beispielsweise können Sie das Replizieren von produktionsähnlichen Szenarien oder das Laden von Testumgebungen nur bei Bedarf durchführen, um Kosten zu sparen.
Erwägen Sie die Nutzung von Azure Monitor, um die Leistung Ihrer Infrastruktur zu analysieren und zu optimieren, die Überwachung durchzuführen und Netzwerkprobleme zu diagnostizieren, ohne dass Sie sich bei Ihren virtuellen Computern anmelden müssen. Application Insights ist tatsächlich einer der Komponenten von Azure Monitor, die Ihnen umfassende Metriken und Protokolle zum Überprüfen des Status Ihrer gesamten Azure-Landschaft an die Hand gibt. Mit Azure Monitor können Sie den Status Ihrer Infrastruktur verfolgen.
Achten Sie darauf, nicht nur die Compute-Elemente zu überwachen, die Ihren Anwendungscode unterstützen, sondern auch Ihre Datenplattformen. Dies gilt vor allem für Ihre Datenbanken, da eine schlechte Leistung der Datenebene einer Anwendung schwerwiegende Folgen haben kann.
Um die Umgebung zu testen, in der die Anwendungen ausgeführt werden, sollte eine Versionskontrolle vorhanden sein, und für die Bereitstellung sollten die gleichen Mechanismen wie für den Anwendungscode verwendet werden. Dies ermöglicht es, die Umgebung ebenfalls anhand von DevOps-Testparadigmen zu testen und zu validieren.
Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework im Abschnitt mit den Informationen zum optimalen Betrieb.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Donnie Trumpower | Senior Cloud Solution Architect
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
Zugehörige Ressourcen
In der folgenden Architektur werden einige der gleichen Technologien verwendet: