Kopieren von Daten aus Amazon RDS für Oracle mithilfe von Azure Data Factory oder Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Dieser Artikel beschreibt, wie die Kopieraktivität in Azure Data Factory verwendet wird, um Daten aus einer Amazon RDS für Oracle-Datenbank zu kopieren. Der Artikel baut auf der Übersicht über die Kopieraktivität auf.
Unterstützte Funktionen
Dieser Amazon RDS for Oracle Connector wird für die folgenden Aktivitäten unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Kopieraktivität (Quelle/-) | 1.6 |
| Lookup-Aktivität | 1.6 |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Insbesondere unterstützt dieser Amazon RDS für Oracle Connector:
- Die folgenden Versionen einer Amazon RDS für Oracle-Datenbank:
- Amazon RDS für Oracle 19c R1 (19.1) und höher
- Amazon RDS für Oracle 18c R1 (18.1) und höher
- Amazon RDS für Oracle 12c R1 (12.1) und höher
- Amazon RDS für Oracle 11g R1 (11.1) und höher
- Paralleles Kopieren aus einer Amazon RDS für Oracle-Quelle. Einzelheiten finden Sie im Abschnitt Parallele Kopie von Amazon RDS für Oracle.
Hinweis
Amazon RDS für Oracle Proxy-Server wird nicht unterstützt.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in einer virtuellen privaten Amazon-Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Die Integrationslaufzeit bietet einen integrierten Amazon RDS für Oracle-Treiber. Daher müssen Sie keinen Treiber manuell installieren, wenn Sie Daten von Amazon RDS für Oracle kopieren.
Erste Schritte
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
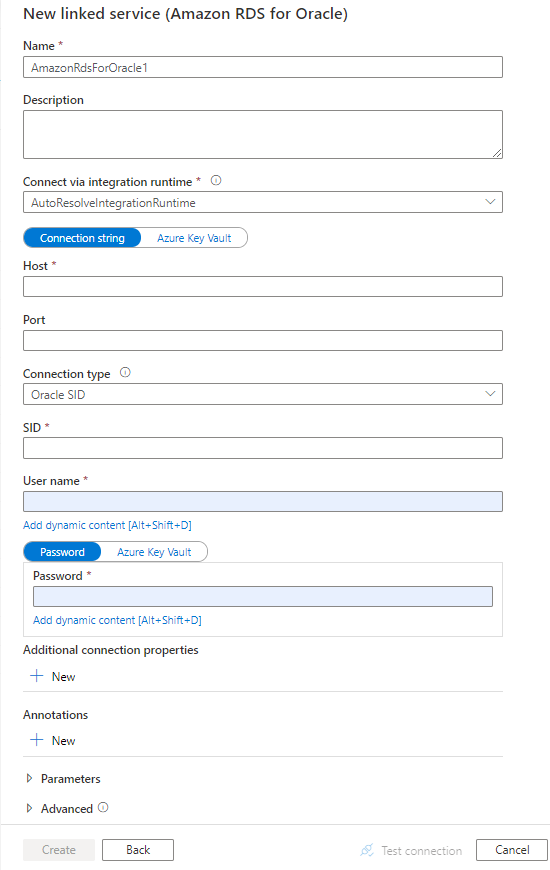
Erstellen Sie einen verknüpften Service mit Amazon RDS für Oracle über die Benutzeroberfläche
Gehen Sie wie folgt vor, um einen mit Amazon RDS für Oracle verknüpften Service in der Benutzeroberfläche des Azure-Portals zu erstellen.
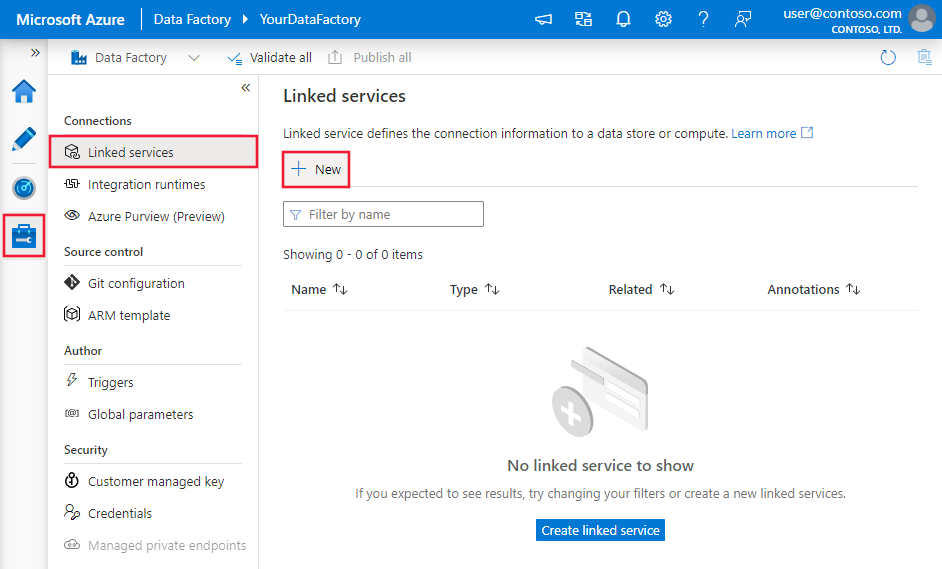
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zu der Registerkarte „Verwalten“. Wählen Sie die Option „Verknüpfte Dienste“ aus, und klicken Sie anschließend auf „Neu“:
Suchen Sie nach Amazon RDS für Oracle und wählen Sie den Amazon RDS für Oracle Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
Details zur Connectorkonfiguration
Die folgenden Abschnitte geben Details an zu Eigenschaften, die zum Definieren von Entitäten speziell für den Amazon RDS für Oracle Connector verwendet werden.
Eigenschaften des verknüpften Diensts
Der verknüpfte Dienst Amazon RDS für Oracle unterstützt folgende Eigenschaften:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft „Typ“ muss auf AmazonRdsForOracle gesetzt werden. | Ja |
| connectionString | Gibt die Informationen an, die zur Verbindung mit der Amazon RDS für Oracle Database-Instanz erforderlich sind. Sie können auch ein Kennwort in Azure Key Vault speichern und die password-Konfiguration aus der Verbindungszeichenfolge pullen. Ausführlichere Informationen finden Sie in den folgenden Beispielen sowie unter Speichern von Anmeldeinformationen in Azure Key Vault. Unterstützter Verbindungstyp: Sie können Amazon RDS für Oracle SID oder Amazon RDS für Oracle Service Name verwenden, um Ihre Datenbank zu identifizieren: – Wenn Sie die SID verwenden: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;– Wenn Sie den Dienstnamen verwenden: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;Für fortgeschrittene Amazon RDS für Oracle native Verbindungsoptionen können Sie einen Eintrag in der Datei JTNSNAMES.ORA auf dem Amazon RDS für Oracle-Server hinzufügen und im verknüpften Dienst Amazon RDS für Oracle entscheiden, den Verbindungstyp „Amazon RDS für Oracle Dienstname“ zu verwenden und den korrespondierenden Dienstnamen zu konfigurieren. |
Ja |
| connectVia | Die Integration Runtime, die zum Herstellen einer Verbindung mit dem Datenspeicher verwendet werden soll. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn keine Option angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Wenn Sie mehrere Amazon RDS für Oracle-Instanzen für ein Failover-Szenario haben, können Sie einen mit Amazon RDS für Oracle verknüpften Dienst erstellen und den Benutzernamen des primären Host-Ports, das Kennwort usw. eingeben und neue „Zusätzliche Verbindungseigenschaften“ mit dem Eigenschaftsnamen AlternateServers und dem Wert (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>) hinzufügen – vergessen Sie die Klammern nicht und achten Sie auf die Doppelpunkte (:) als Trennzeichen. Beispielsweise definiert der folgende Wert von alternativen Servern zwei alternative Datenbankserver für das Verbindungsfailover: (HostName=AccountingAmazonRdsForOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Weitere Verbindungseigenschaften, die Sie abhängig von Ihrem Anwendungsfall in der Verbindungszeichenfolge festlegen können:
| Eigenschaft | BESCHREIBUNG | Zulässige Werte |
|---|---|---|
| ArraySize | Die Anzahl von Bytes, die der Connector in einem einzelnen Netzwerkroundtrip abrufen kann. Beispielsweise ArraySize=10485760.Größere Werte erhöhen den Durchsatz, indem seltener Daten über das Netzwerk abgerufen werden. Kleinere Werte erhöhen die Reaktionszeit, da weniger lange auf die Übertragung von Daten durch den Server gewartet werden muss. |
Eine ganze Zahl zwischen 1 und 4.294.967.296 (4 GB). Der Standardwert ist 60000. Der Wert 1 definiert nicht die Anzahl von Bytes, sondern gibt die Zuordnung von Speicherplatz für genau eine Datenzeile an. |
Um die Verschlüsselung bei der Verbindung mit Amazon RDS für Oracle zu aktivieren, haben Sie zwei Möglichkeiten:
Um Triple-DES-Verschlüsselung (3DES) und Advanced Encryption Standard (AES) zu verwenden, gehen Sie auf der Amazon RDS für Oracle-Serverseite zu Oracle Advanced Security (OAS) und konfigurieren die Verschlüsselungseinstellungen. Ausführliche Informationen finden Sie in der Oracle-Dokumentation. Der Amazon RDS für Oracle Application Development Framework(ADF)-Connector handelt automatisch die Verschlüsselungsmethode aus und verwendet die von Ihnen in OAS konfigurierte Methode, wenn eine Verbindung zu Amazon RDS für Oracle hergestellt wird.
So verwenden Sie TLS:
Rufen Sie die TLS/SSL-Zertifikatinformationen ab. Rufen Sie die mit Distinguished Encoding Rules (DER) codierten Zertifikatinformationen Ihres TLS/SSL-Zertifikats ab, und speichern Sie die Ausgabe (----- Begin Certificate … End Certificate -----) als Textdatei.
openssl x509 -inform DER -in [Full Path to the DER Certificate including the name of the DER Certificate] -textBeispiel: Extrahieren Sie Zertifikatinformationen aus „DERcert.cer“, und speichern Sie die Ausgabe in „cert.txt“.
openssl x509 -inform DER -in DERcert.cer -text Output: -----BEGIN CERTIFICATE----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXX -----END CERTIFICATE-----Erstellen Sie
keystoreodertruststore. Mit dem folgenden Befehl wird die Dateitruststore(mit oder ohne Kennwort) im PKCS-12-Format erstellt.openssl pkcs12 -in [Path to the file created in the previous step] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -nokeys -exportBeispiel: Erstellen Sie eine PKCS12-Datei vom Typ
truststorenamens „MyTrustStoreFile“ mit einem Kennwort.openssl pkcs12 -in cert.txt -out MyTrustStoreFile -passout pass:ThePWD -nokeys -exportPlatzieren Sie die Datei
truststoreauf dem Computer mit der selbstgehosteten Integration Runtime. Platzieren Sie die Datei beispielsweise unter „C:\MyTrustStoreFile“.Konfigurieren Sie in dem Dienst die Amazon RDS für Oracle-Verbindungszeichenfolge mit
EncryptionMethod=1und dem entsprechenden Wert fürTrustStore/TrustStorePassword. Beispiel:Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Beispiel:
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Speichern des Kennworts in Azure Key Vault
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset-Eigenschaften
Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom Amazon RDS für Oracle-Dataset unterstützt werden. Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets.
Um Daten von Amazon RDS für Oracle zu kopieren, setzen Sie die Eigenschaft „Typ“ des Datasets auf AmazonRdsForOracleTable. Die folgenden Eigenschaften werden unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft „type“ des Datasets muss auf AmazonRdsForOracleTable festgelegt werden. |
Ja |
| schema | Name des Schemas. | Nein |
| table | Name der Tabelle/Ansicht. | Nein |
| tableName | Name der Tabelle/Ansicht mit Schema. Diese Eigenschaft wird aus Gründen der Abwärtskompatibilität weiterhin unterstützt. Verwenden Sie für eine neue Workload schema und table. |
Nein |
Beispiel:
{
"name": "AmazonRdsForOracleDataset",
"properties":
{
"type": "AmazonRdsForOracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Amazon RDS for Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Eigenschaften der Kopieraktivität
Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der Amazon RDS für Oracle-Quelle unterstützt werden. Eine vollständige Liste der verfügbaren Abschnitte und Eigenschaften zum Definieren von Aktivitäten finden Sie unter Pipelines.
Amazon RDS für Oracle als Quelle
Tipp
Mehr über das effiziente Laden von Daten aus Amazon RDS für Oracle unter Verwendung von Datenpartitionierung erfahren Sie unter Paralleles Kopieren aus Amazon RDS für Oracle.
Um Daten von Amazon RDS für Oracle zu kopieren, setzen Sie den Quellentyp in der Kopieraktivität auf AmazonRdsForOracleSource. Die folgenden Eigenschaften werden im Abschnitt source der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die Eigenschaft „type“ der Quelle der Kopieraktivität muss auf AmazonRdsForOracleSource festgelegt werden. |
Ja |
| oracleReaderQuery | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. z. B. "SELECT * FROM MyTable".Wenn Sie partitioniertes Laden aktivieren, müssen Sie die entsprechenden integrierten Partitionsparameter in Ihre Abfrage integrieren. Beispiele finden Sie im Abschnitt Paralleles Kopieren aus Amazon RDS für Oracle. |
Nein |
| partitionOptions | Gibt die Datenpartitionierungsoptionen an, die zum Laden von Daten aus Amazon RDS für Oracle verwendet werden. Zulässige Werte sind: None (Standardwert), PhysicalPartitionsOfTable und DynamicRange. Wenn eine Partitionsoption aktiviert ist (d. h. nicht None), wird der Grad der Parallelität zum gleichzeitigen Laden von Daten aus einer Amazon RDS für Oracle-Datenbank durch die parallelCopies-Einstellung der Kopieraktivität gesteuert. |
Nein |
| partitionSettings | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie diese Option, wenn die Partitionsoption nicht None lautet. |
Nein |
| partitionNames | Die Liste der physischen Partitionen, die kopiert werden müssen. Verwenden Sie diese Option, wenn die Partitionsoption PhysicalPartitionsOfTable lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfTabularPartitionName in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Amazon RDS für Oracle. |
Nein |
| partitionColumnName | Geben Sie den Namen der Quellspalte als Integer an, der von der Bereichspartitionierung für den parallelen Kopiervorgang verwendet wird. Ohne Angabe wird der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfRangePartitionColumnName in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Amazon RDS für Oracle. |
Nein |
| partitionUpperBound | Der Höchstwert der Partitionsspalte zum Herauskopieren von Daten. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfRangePartitionUpbound in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Amazon RDS für Oracle. |
Nein |
| partitionLowerBound | Der Mindestwert der Partitionsspalte zum Herauskopieren von Daten. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?AdfRangePartitionLowbound in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus Amazon RDS für Oracle. |
Nein |
Beispiel: Kopieren von Daten mit einer einfachen Abfrage ohne Partition
"activities":[
{
"name": "CopyFromAmazonRdsForOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForOracleSource",
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Paralleles Kopieren aus Amazon RDS für Oracle
Der Amazon RDS für Oracle Connector stellt eine integrierte Datenpartitionierung bereit, um Daten von Amazon RDS für Oracle parallel zu kopieren. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.

Wenn Sie partitioniertes Kopieren aktivieren, führt der Dienst parallele Abfragen gegen Ihre Amazon RDS für Oracle-Quelle aus, um Daten nach Partitionen zu laden. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie z. B. parallelCopies auf vier einstellen, generiert der Dienst gleichzeitig vier Abfragen, die auf der von Ihnen angegebenen Partitionsoption und den Einstellungen basieren, und führt sie aus, wobei jede Abfrage einen Teil der Daten aus Ihrer Amazon RDS für Oracle-Datenbank abruft.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung vor allem dann zu aktivieren, wenn Sie große Datenmengen aus Ihrer Amazon RDS für Oracle-Datenbank laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben. (Geben Sie nur den Ordnernamen an.) In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen | Partitionsoption: Physische Partitionen der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert Daten nach Partitionen. |
| Vollständiges Laden aus einer großen Tabelle ohne physische Partitionen, aber mit einer Integerspalte für die Datenpartitionierung | Partitionsoptionen: Dynamische Bereichspartitionierung Partitionsspalte: Geben Sie die Spalte für die Datenpartitionierung an. Ohne Angabe wird die Primärschlüsselspalte verwendet. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage mit physischen Partitionen | Partitionsoption: Physische Partitionen der Tabelle. Abfrage: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>Partitionsname: Geben Sie den Namen der Partitionen an, aus denen Daten kopiert werden sollen. Wenn nicht angegeben: Der Dienst erkennt automatisch die physischen Partitionen in der Tabelle, die Sie im Amazon RDS für Oracle-Datensatz angegeben haben. Während der Ausführung ersetzt der Dienst ?AdfTabularPartitionName durch den tatsächlichen Partitionsnamen und sendet diesen zu Amazon RDS für Oracle. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage ohne physische Partitionen, aber mit einer Integerspalte für die Datenpartitionierung | Partitionsoptionen: Dynamische Bereichspartitionierung Abfrage: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte für die Datenpartitionierung an. Die Partitionierung kann auf der Grundlage der Spalte mit dem Datentyp „Integer“ erfolgen. Obergrenze der Partition und Untergrenze der Partition: Geben Sie an, ob Sie anhand der Partitionsspalte filtern möchten, um nur Daten zwischen der Ober- und der Untergrenze zu erhalten. Während der Ausführung ersetzt der Dienst ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound und ?AdfRangePartitionLowbound durch die tatsächlichen Spaltennamen und Wertebereiche für jede Partition und sendet sie zu Amazon RDS für Oracle. Wenn z. B. für Ihre Partitionsspalte „ID“ die untere Grenze auf 1 und die obere Grenze auf 80 festgelegt ist und die Parallelkopie auf 4 eingestellt ist, ruft der Dienst Daten nach 4 Partitionen ab. Die ID-Bereiche sehen dann wie folgt aus: [1, 20], [21, 40], [41, 60], und [61, 80]. |
Tipp
Beim Kopieren von Daten aus einer nicht partitionierten Tabelle können Sie die Partitionsoption „Dynamischer Bereich“ verwenden, um eine Partitionierung auf Grundlage einer ganzzahlige Spalte durchzuführen. Wenn die Quelldaten keinen solchen Spaltentyp enthalten, können Sie mithilfe der ORA_HASH-Funktion in der Quellabfrage eine Spalte generieren und diese als Partitionsspalte verwenden.
Beispiel: Abfrage mit physischer Partition
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Zugehöriger Inhalt
Eine Liste der Datenspeicher, die als Quelles und Senken für die Kopieraktivität unterstützt werden, finden Sie in Unterstützte Datenspeicher.