Events
Mar 17, 9 PM - Mar 21, 10 AM
Join the meetup series to build scalable AI solutions based on real-world use cases with fellow developers and experts.
Register nowThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Gremlin
Gremlin
Azure Cosmos DB provides various analytics options for no-ETL, near real-time analytics over operational data. You can enable analytics on your Azure Cosmos DB data using following options:
To learn more about these options, see "Analytics and BI on your Azure Cosmos DB data."
Important
Mirroring Azure Cosmos DB in Microsoft Fabric is now available in preview for NoSql API. This feature provides all the capabilities of Azure Synapse Link with better analytical performance, ability to unify your data estate with Fabric OneLake and open access to your data in OneLake with Delta Parquet format. If you are considering Azure Synapse Link, we recommend that you try mirroring to assess overall fit for your organization. To get started with mirroring, click here.
No-ETL, near real-time analytics can open up various possibilities for your businesses. Here are three sample scenarios:
Research studies show that embedding big data analytics in supply chain operations leads to improvements in order-to-cycle delivery times and supply chain efficiency.
Manufacturers are onboarding to cloud-native technologies to break out of constraints of legacy Enterprise Resource Planning (ERP) and Supply Chain Management (SCM) systems. With supply chains generating increasing volumes of operational data every minute (order, shipment, transaction data), manufacturers need an operational database. This operational database should scale to handle the data volumes as well as an analytical platform to get to a level of real-time contextual intelligence to stay ahead of the curve.
The following architecture shows the power of using Azure Cosmos DB as the cloud-native operational database in supply chain analytics:
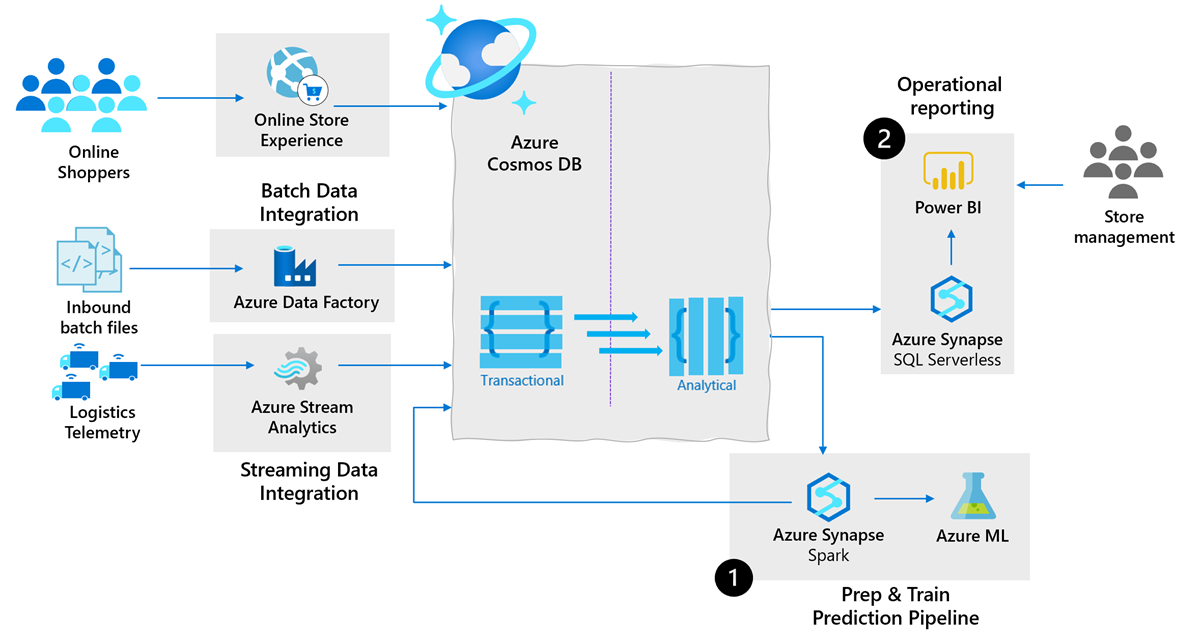
Based on previous architecture, you can achieve the following use cases:
Mirroring and Synapse Link allow you to analyze the changing operational data in Azure Cosmos DB without any manual ETL processes. These offerings save you from additional cost, latency, and operational complexity. They enable data engineers and data scientists to build robust predictive pipelines:
Query operational data from Azure Cosmos DB by using native integration with Apache Spark pools in Microsoft Fabric or Azure Synapse Analytics. You can query the data in an interactive notebook or scheduled remote jobs without complex data engineering.
Build Machine Learning (ML) models with Spark ML algorithms and Azure Machine Learning (AML) integration in Microsoft Fabric or Azure Synapse Analytics.
Write back the results after model inference into Azure Cosmos DB for operational near-real-time scoring.
Operational reporting: Supply chain teams need flexible and custom reports over real-time, accurate operational data. These reports are required to obtain a snapshot view of supply chain effectiveness, profitability, and productivity. It allows data analysts and other key stakeholders to constantly reevaluate the business and identify areas to tweak to reduce operational costs.
Mirroring and Synapse Link for Azure Cosmos DB enable rich business intelligence (BI)/reporting scenarios:
Query operational data from Azure Cosmos DB by using native integration with full expressiveness of T-SQL language.
Model and publish auto refreshing BI dashboards over Azure Cosmos DB through Power BI integrated in Microsoft Fabric or Azure Synapse Analytics.
The following is some guidance for data integration for batch & streaming data into Azure Cosmos DB:
Batch data integration & orchestration: With supply chains getting more complex, supply chain data platforms need to integrate with variety of data sources and formats. Microsoft Fabric and Azure Synapse come built-in with the same data integration engine and experiences as Azure Data Factory. This integration allows data engineers to create rich data pipelines without a separate orchestration engine:
Move data from 85+ supported data sources to Azure Cosmos DB with Azure Data Factory.
Write code-free ETL pipelines to Azure Cosmos DB including relational-to-hierarchical and hierarchical-to-hierarchical mappings with mapping data flows.
Streaming data integration & processing: With the growth of Industrial IoT (sensors tracking assets from 'floor-to-store', connected logistics fleets, etc.), there is an explosion of real-time data being generated in a streaming fashion that needs to be integrated with traditional slow moving data for generating insights. Azure Stream Analytics is a recommended service for streaming ETL and processing on Azure with a wide range of scenarios. Azure Stream Analytics supports Azure Cosmos DB as a native data sink.
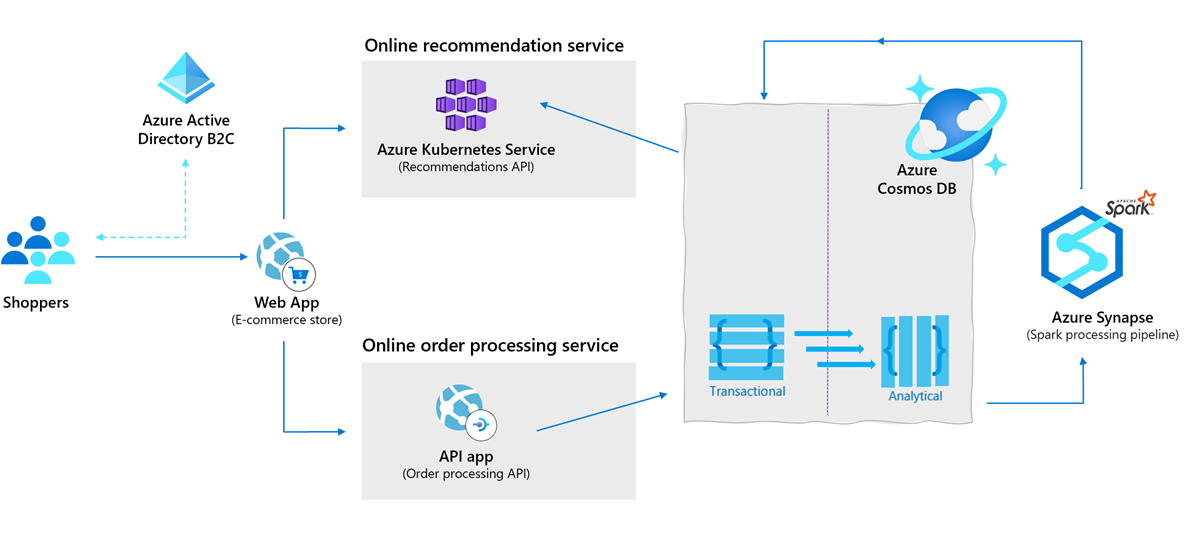
Retailers today must build secure and scalable e-commerce solutions that meet the demands of both customers and business. These e-commerce solutions need to engage customers through customized products and offers, process transactions quickly and securely, and focus on fulfillment and customer service. Azure Cosmos DB along with the latest Synapse Link for Azure Cosmos DB allows retailers to generate personalized recommendations for customers in real time. They use low-latency and tunable consistency settings for immediate insights as shown in the following architecture:
Industrial IOT innovations have drastically reduced downtimes of machinery and increased overall efficiency across all fields of industry. One of such innovations is predictive maintenance analytics for machinery at the edge of the cloud.
The following is an architecture using the cloud native HTAP capabilities in IoT predictive maintenance:
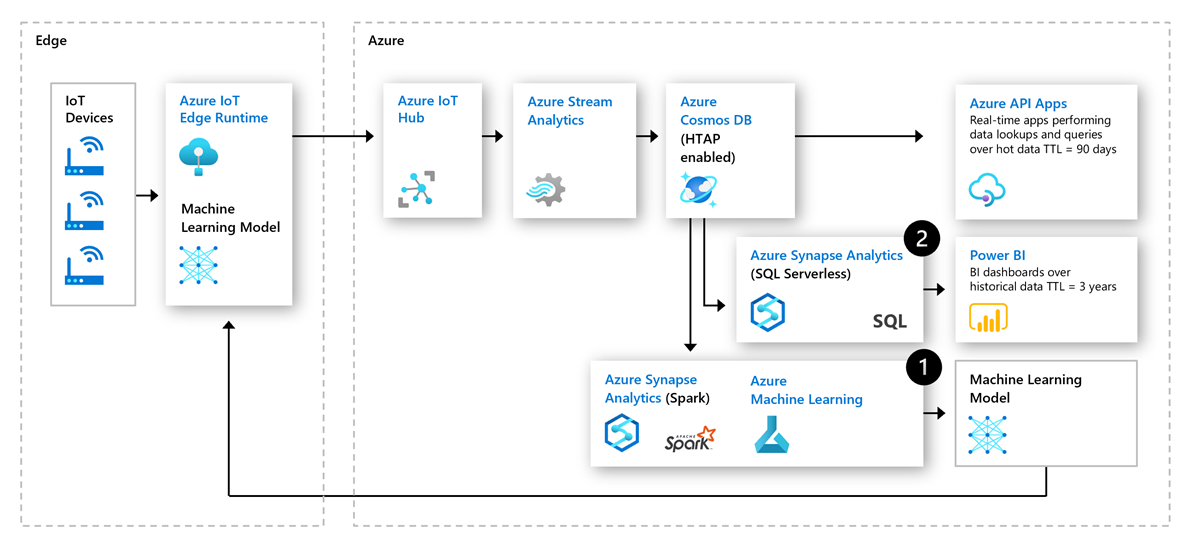
Prepare & train predictive pipeline: The historical operational data from IoT device sensors could be used to train predictive models such as anomaly detectors. These anomaly detectors are then deployed back to the edge for real-time monitoring. Such a virtuous loop allows for continuous retraining of the predictive models.
Operational reporting: With the growth of digital twin initiatives, companies are collecting vast amounts of operational data from large number of sensors to build a digital copy of each machine. This data powers BI needs to understand trends over historical data in addition to recent hot data.
Events
Mar 17, 9 PM - Mar 21, 10 AM
Join the meetup series to build scalable AI solutions based on real-world use cases with fellow developers and experts.
Register nowTraining
Module
Implement Azure Synapse Link with Azure Cosmos DB - Training
Implement Azure Synapse Link with Azure Cosmos DB
Certification
Microsoft Certified: Azure Cosmos DB Developer Specialty - Certifications
Write efficient queries, create indexing policies, manage, and provision resources in the SQL API and SDK with Microsoft Azure Cosmos DB.