Copy and transform data in Microsoft Fabric Warehouse using Azure Data Factory or Azure Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use Copy Activity to copy data from and to Microsoft Fabric Warehouse. To learn more, read the introductory article for Azure Data Factory or Azure Synapse Analytics.
Supported capabilities
This Microsoft Fabric Warehouse connector is supported for the following capabilities:
| Supported capabilities | IR | Managed private endpoint |
|---|---|---|
| Copy activity (source/sink) | ① ② | ✓ |
| Lookup activity | ① ② | ✓ |
| GetMetadata activity | ① ② | ✓ |
| Script activity | ① ② | ✓ |
| Stored procedure activity | ① ② | ✓ |
① Azure integration runtime ② Self-hosted integration runtime
Get started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create a Microsoft Fabric Warehouse linked service using UI
Use the following steps to create a Microsoft Fabric Warehouse linked service in the Azure portal UI.
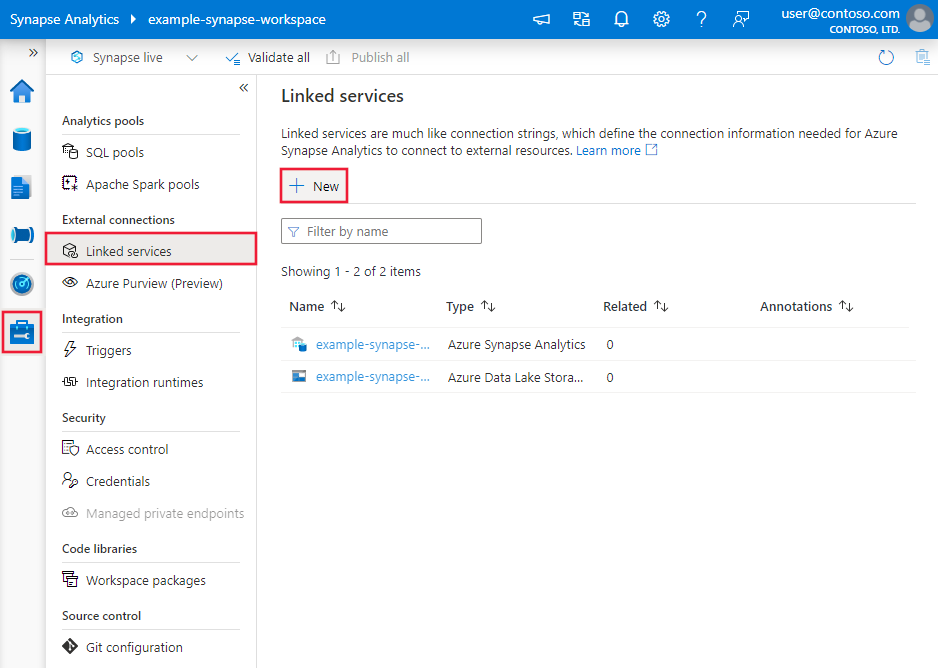
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then select New:
Search for Warehouse and select the connector.
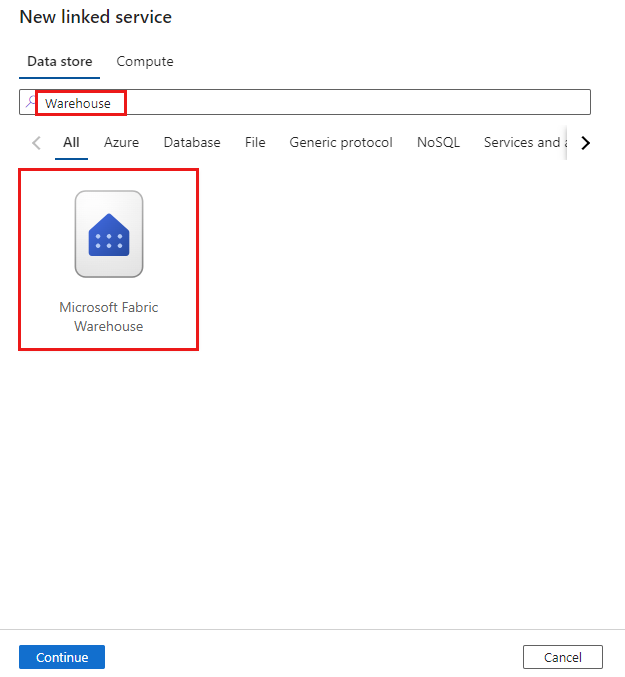
Configure the service details, test the connection, and create the new linked service.
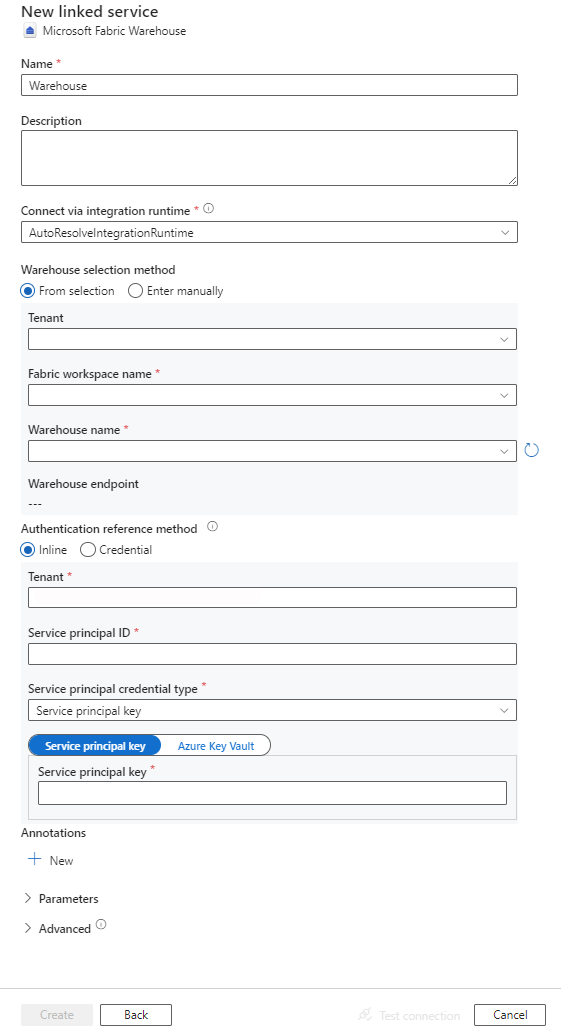

Connector configuration details
The following sections provide details about properties that are used to define Data Factory entities specific to Microsoft Fabric Warehouse.
Linked service properties
The Microsoft Fabric Warehouse connector supports the following authentication types. See the corresponding sections for details:
Service principal authentication
To use service principal authentication, follow these steps.
Register an application with the Microsoft Identity platform and add a client secret. Afterwards, make note of these values, which you use to define the linked service:
- Application (client) ID, which is the service principal ID in the linked service.
- Client secret value, which is the service principal key in the linked service.
- Tenant ID
Grant the service principal at least the Contributor role in Microsoft Fabric workspace. Follow these steps:
Go to your Microsoft Fabric workspace, select Manage access on the top bar. Then select Add people or groups.
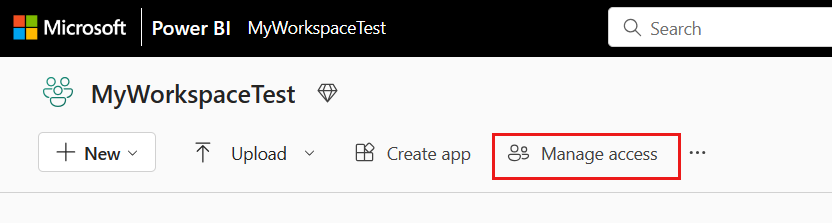
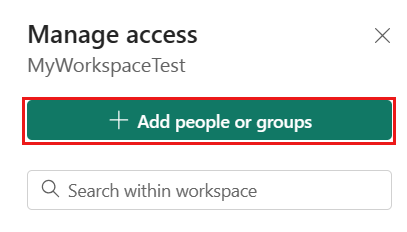
In Add people pane, enter your service principal name, and select your service principal from the drop-down list.
Specify the role as Contributor or higher (Admin, Member), then select Add.
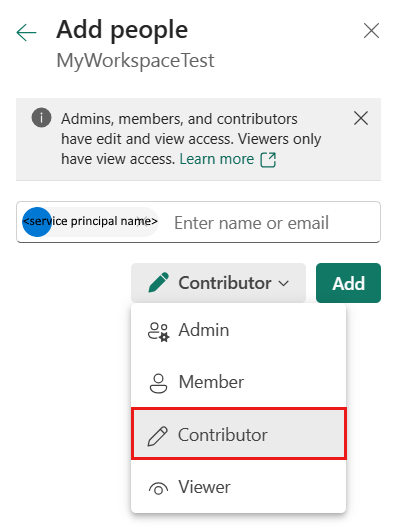
Your service principal is displayed on Manage access pane.
These properties are supported for the linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to Warehouse. | Yes |
| endpoint | The endpoint of Microsoft Fabric Warehouse server. | Yes |
| workspaceId | The Microsoft Fabric workspace ID. | Yes |
| artifactId | The Microsoft Fabric Warehouse object ID. | Yes |
| tenant | Specify the tenant information (domain name or tenant ID) under which your application resides. Retrieve it by hovering the mouse in the upper-right corner of the Azure portal. | Yes |
| servicePrincipalId | Specify the application's client ID. | Yes |
| servicePrincipalCredentialType | The credential type to use for service principal authentication. Allowed values are ServicePrincipalKey and ServicePrincipalCert. | Yes |
| servicePrincipalCredential | The service principal credential. When you use ServicePrincipalKey as the credential type, specify the application's client secret value. Mark this field as SecureString to store it securely, or reference a secret stored in Azure Key Vault. When you use ServicePrincipalCert as the credential, reference a certificate in Azure Key Vault, and ensure the certificate content type is PKCS #12. |
Yes |
| connectVia | The integration runtime to be used to connect to the data store. You can use the Azure integration runtime or a self-hosted integration runtime if your data store is in a private network. If not specified, the default Azure integration runtime is used. | No |
Example: using service principal key authentication
You can also store service principal key in Azure Key Vault.
{
"name": "MicrosoftFabricWarehouseLinkedService",
"properties": {
"type": "Warehouse",
"typeProperties": {
"endpoint": "<Microsoft Fabric Warehouse server endpoint>",
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Warehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see the Datasets article.
The following properties are supported for Microsoft Fabric Warehouse dataset:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to WarehouseTable. | Yes |
| schema | Name of the schema. | No for source, Yes for sink |
| table | Name of the table/view. | No for source, Yes for sink |
Dataset properties example
{
"name": "FabricWarehouseTableDataset",
"properties": {
"type": "WarehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Warehouse linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring >
],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see Copy activity configurations and Pipelines and activities. This section provides a list of properties supported by the Microsoft Fabric Warehouse source and sink.
Microsoft Fabric Warehouse as the source
Tip
To load data from Microsoft Fabric Warehouse efficiently by using data partitioning, learn more from Parallel copy from Microsoft Fabric Warehouse.
To copy data from Microsoft Fabric Warehouse, set the type property in the Copy Activity source to WarehouseSource. The following properties are supported in the Copy Activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the Copy Activity source must be set to WarehouseSource. | Yes |
| sqlReaderQuery | Use the custom SQL query to read data. Example: select * from MyTable. |
No |
| sqlReaderStoredProcedureName | The name of the stored procedure that reads data from the source table. The last SQL statement must be a SELECT statement in the stored procedure. | No |
| storedProcedureParameters | Parameters for the stored procedure. Allowed values are name or value pairs. Names and casing of parameters must match the names and casing of the stored procedure parameters. |
No |
| queryTimeout | Specifies the timeout for query command execution. Default is 120 minutes. | No |
| isolationLevel | Specifies the transaction locking behavior for the SQL source. The allowed value is Snapshot. If not specified, the database's default isolation level is used. For more information, see system.data.isolationlevel. | No |
| partitionOptions | Specifies the data partitioning options used to load data from Microsoft Fabric Warehouse. Allowed values are: None (default), and DynamicRange. When a partition option is enabled (that is, not None), the degree of parallelism to concurrently load data from a Microsoft Fabric Warehouse is controlled by the parallelCopies setting on the copy activity. |
No |
| partitionSettings | Specify the group of the settings for data partitioning. Apply when the partition option isn't None. |
No |
Under partitionSettings: |
||
| partitionColumnName | Specify the name of the source column in integer or date/datetime type (int, smallint, bigint, date, datetime2) that will be used by range partitioning for parallel copy. If not specified, the index or the primary key of the table is detected automatically and used as the partition column.Apply when the partition option is DynamicRange. If you use a query to retrieve the source data, hook ?DfDynamicRangePartitionCondition in the WHERE clause. For an example, see the Parallel copy from Microsoft Fabric Warehouse section. |
No |
| partitionUpperBound | The maximum value of the partition column for partition range splitting. This value is used to decide the partition stride, not for filtering the rows in table. All rows in the table or query result will be partitioned and copied. If not specified, copy activity auto detect the value. Apply when the partition option is DynamicRange. For an example, see the Parallel copy from Microsoft Fabric Warehouse section. |
No |
| partitionLowerBound | The minimum value of the partition column for partition range splitting. This value is used to decide the partition stride, not for filtering the rows in table. All rows in the table or query result will be partitioned and copied. If not specified, copy activity auto detect the value. Apply when the partition option is DynamicRange. For an example, see the Parallel copy from Microsoft Fabric Warehouse section. |
No |
Note
When using stored procedure in source to retrieve data, note if your stored procedure is designed as returning different schema when different parameter value is passed in, you may encounter failure or see unexpected result when importing schema from UI or when copying data to Microsoft Fabric Warehouse with auto table creation.
Example: using SQL query
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Example: using stored procedure
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Sample stored procedure:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Microsoft Fabric Warehouse as a sink type
Azure Data Factory and Synapse pipelines support Use COPY statement to load data into Microsoft Fabric Warehouse.
To copy data to Microsoft Fabric Warehouse, set the sink type in Copy Activity to WarehouseSink. The following properties are supported in the Copy Activity sink section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the Copy Activity sink must be set to WarehouseSink. | Yes |
| allowCopyCommand | Indicates whether to use COPY statement to load data into Microsoft Fabric Warehouse. See Use COPY statement to load data into Microsoft Fabric Warehouse section for constraints and details. The allowed value is True. |
Yes |
| copyCommandSettings | A group of properties that can be specified when allowCopyCommand property is set to TRUE. |
No |
| writeBatchTimeout | This property specifies the wait time for the insert, upsert and stored procedure operation to complete before it times out. Allowed values are for the timespan. An example is "00:30:00" for 30 minutes. If no value is specified, the timeout defaults to "00:30:00" |
No |
| preCopyScript | Specify a SQL query for Copy Activity to run before writing data into Microsoft Fabric Warehouse in each run. Use this property to clean up the preloaded data. | No |
| tableOption | Specifies whether to automatically create the sink table if not exists based on the source schema. Allowed values are: none (default), autoCreate. |
No |
| disableMetricsCollection | The service collects metrics for copy performance optimization and recommendations, which introduce additional master DB access. If you are concerned with this behavior, specify true to turn it off. |
No (default is false) |
Example: Microsoft Fabric Warehouse sink
"activities":[
{
"name": "CopyToMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Warehouse output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"tableOption": "autoCreate",
"disableMetricsCollection": false
}
}
}
]
Parallel copy from Microsoft Fabric Warehouse
The Microsoft Fabric Warehouse connector in copy activity provides built-in data partitioning to copy data in parallel. You can find data partitioning options on the Source tab of the copy activity.
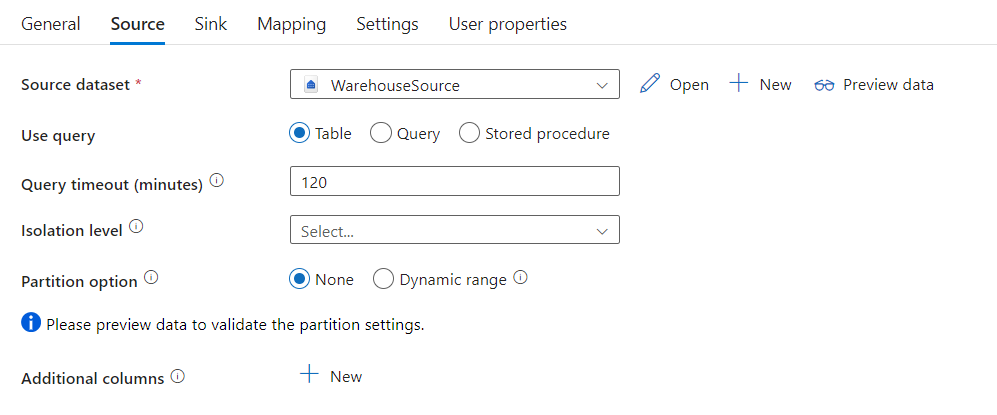
When you enable partitioned copy, copy activity runs parallel queries against your Microsoft Fabric Warehouse source to load data by partitions. The parallel degree is controlled by the parallelCopies setting on the copy activity. For example, if you set parallelCopies to four, the service concurrently generates and runs four queries based on your specified partition option and settings, and each query retrieves a portion of data from your Microsoft Fabric Warehouse.
You are suggested to enable parallel copy with data partitioning especially when you load large amount of data from your Microsoft Fabric Warehouse. The following are suggested configurations for different scenarios. When copying data into file-based data store, it's recommended to write to a folder as multiple files (only specify folder name), in which case the performance is better than writing to a single file.
| Scenario | Suggested settings |
|---|---|
| Full load from large table, while with an integer or datetime column for data partitioning. | Partition options: Dynamic range partition. Partition column (optional): Specify the column used to partition data. If not specified, the index or primary key column is used. Partition upper bound and partition lower bound (optional): Specify if you want to determine the partition stride. This is not for filtering the rows in table, and all rows in the table will be partitioned and copied. If not specified, copy activity auto detect the values. For example, if your partition column "ID" has values range from 1 to 100, and you set the lower bound as 20 and the upper bound as 80, with parallel copy as 4, the service retrieves data by 4 partitions - IDs in range <=20, [21, 50], [51, 80], and >=81, respectively. |
| Load a large amount of data by using a custom query, while with an integer or date/datetime column for data partitioning. | Partition options: Dynamic range partition. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partition column: Specify the column used to partition data. Partition upper bound and partition lower bound (optional): Specify if you want to determine the partition stride. This is not for filtering the rows in table, and all rows in the query result will be partitioned and copied. If not specified, copy activity auto detect the value. For example, if your partition column "ID" has values range from 1 to 100, and you set the lower bound as 20 and the upper bound as 80, with parallel copy as 4, the service retrieves data by 4 partitions- IDs in range <=20, [21, 50], [51, 80], and >=81, respectively. Here are more sample queries for different scenarios: 1. Query the whole table: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Query from a table with column selection and additional where-clause filters: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Query with subqueries: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Query with partition in subquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Best practices to load data with partition option:
- Choose distinctive column as partition column (like primary key or unique key) to avoid data skew.
- If you use Azure Integration Runtime to copy data, you can set larger "Data Integration Units (DIU)" (>4) to utilize more computing resource. Check the applicable scenarios there.
- "Degree of copy parallelism" control the partition numbers, setting this number too large sometime hurts the performance, recommend setting this number as (DIU or number of Self-hosted IR nodes) * (2 to 4).
- Note that Microsoft Fabric Warehouse can execute a maximum of 32 queries at a moment, setting "Degree of copy parallelism" too large may cause a Warehouse throttling issue.
Example: query with dynamic range partition
"source": {
"type": "WarehouseSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Use COPY statement to load data into Microsoft Fabric Warehouse
Using COPY statement is a simple and flexible way to load data into Microsoft Fabric Warehouse with high throughput. To learn more details, check Bulk load data using the COPY statement
- If your source data is in Azure Blob or Azure Data Lake Storage Gen2, and the format is COPY statement compatible, you can use copy activity to directly invoke COPY statement to let Microsoft Fabric Warehouse pull the data from source. For details, see Direct copy by using COPY statement.
- If your source data store and format isn't originally supported by COPY statement, use the Staged copy by using COPY statement feature instead. The staged copy feature also provides you with better throughput. It automatically converts the data into COPY statement compatible format, stores the data in Azure Blob storage, then calls COPY statement to load data into Microsoft Fabric Warehouse.
Tip
When using COPY statement with Azure Integration Runtime, effective Data Integration Units (DIU) is always 2. Tuning the DIU doesn't impact the performance.
Direct copy by using COPY statement
Microsoft Fabric Warehouse COPY statement directly supports Azure Blob, Azure Data Lake Storage Gen1 and Azure Data Lake Storage Gen2. If your source data meets the criteria described in this section, use COPY statement to copy directly from the source data store to Microsoft Fabric Warehouse. Otherwise, use Staged copy by using COPY statement. The service checks the settings and fails the copy activity run if the criteria is not met.
The source linked service and format are with the following types and authentication methods:
Supported source data store type Supported format Supported source authentication type Azure Blob Delimited text Account key authentication, shared access signature authentication Parquet Account key authentication, shared access signature authentication Azure Data Lake Storage Gen2 Delimited text
ParquetAccount key authentication, shared access signature authentication Format settings are with the following:
- For Parquet:
compressioncan be no compression, Snappy, orGZip. - For Delimited text:
rowDelimiteris explicitly set as single character or "\r\n", the default value is not supported.nullValueis left as default or set to empty string ("").encodingNameis left as default or set to utf-8 or utf-16.escapeCharmust be same asquoteChar, and is not empty.skipLineCountis left as default or set to 0.compressioncan be no compression orGZip.
- For Parquet:
If your source is a folder,
recursivein copy activity must be set to true, andwildcardFilenameneed to be*or*.*.wildcardFolderPath,wildcardFilename(other than*or*.*),modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryandadditionalColumnsare not specified.
The following COPY statement settings are supported under allowCopyCommand in copy activity:
| Property | Description | Required |
|---|---|---|
| defaultValues | Specifies the default values for each target column in Microsoft Fabric Warehouse. The default values in the property overwrite the DEFAULT constraint set in the data warehouse, and identity column cannot have a default value. | No |
| additionalOptions | Additional options that will be passed to a Microsoft Fabric Warehouse COPY statement directly in "With" clause in COPY statement. Quote the value as needed to align with the COPY statement requirements. | No |
"activities":[
{
"name": "CopyFromAzureBlobToMicrosoftFabricWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Staged copy by using COPY statement
When your source data is not natively compatible with COPY statement, enable data copying via an interim staging Azure Blob or Azure Data Lake Storage Gen2 (it can't be Azure Premium Storage). In this case, the service automatically converts the data to meet the data format requirements of COPY statement. Then it invokes COPY statement to load data into Microsoft Fabric Warehouse. Finally, it cleans up your temporary data from the storage. See Staged copy for details about copying data via a staging.
To use this feature, create an Azure Blob Storage linked service or Azure Data Lake Storage Gen2 linked service with account key or system-managed identity authentication that refers to the Azure storage account as the interim storage.
Important
- When you use managed identity authentication for your staging linked service, learn the needed configurations for Azure Blob and Azure Data Lake Storage Gen2 respectively.
- If your staging Azure Storage is configured with VNet service endpoint, you must use managed identity authentication with "allow trusted Microsoft service" enabled on storage account, refer to Impact of using VNet Service Endpoints with Azure storage.
Important
If your staging Azure Storage is configured with Managed Private Endpoint and has the storage firewall enabled, you must use managed identity authentication and grant Storage Blob Data Reader permissions to the Synapse SQL Server to ensure it can access the staged files during the COPY statement load.
"activities":[
{
"name": "CopyFromSQLServerToMicrosoftFabricWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Lookup activity properties
To learn details about the properties, check Lookup activity.
GetMetadata activity properties
To learn details about the properties, check GetMetadata activity
Data type mapping for Microsoft Fabric Warehouse
When you copy data from Microsoft Fabric Warehouse, the following mappings are used from Microsoft Fabric Warehouse data types to interim data types within the service internally. To learn about how the copy activity maps the source schema and data type to the sink, see Schema and data type mappings.
| Microsoft Fabric Warehouse data type | Data Factory interim data type |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| date | DateTime |
| datetime2 | DateTime |
| Decimal | Decimal |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Float | Double |
| int | Int32 |
| numeric | Decimal |
| real | Single |
| smallint | Int16 |
| time | TimeSpan |
| uniqueidentifier | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
Next steps
For a list of data stores supported as sources and sinks by the copy activity, see Supported data stores.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for