Transform data by running a Databricks notebook
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
The Azure Databricks Notebook Activity in a pipeline runs a Databricks notebook in your Azure Databricks workspace. This article builds on the data transformation activities article, which presents a general overview of data transformation and the supported transformation activities. Azure Databricks is a managed platform for running Apache Spark.
You can create a Databricks notebook with an ARM template using JSON, or directly through the Azure Data Factory Studio user interface. For a step-by-step walkthrough of how to create a Databricks notebook activity using the user interface, reference the tutorial Run a Databricks notebook with the Databricks Notebook Activity in Azure Data Factory.
To use a Notebook activity for Azure Databricks in a pipeline, complete the following steps:
Search for Notebook in the pipeline Activities pane, and drag a Notebook activity to the pipeline canvas.
Select the new Notebook activity on the canvas if it isn't already selected.
Select the Azure Databricks tab to select or create a new Azure Databricks linked service that will execute the Notebook activity.
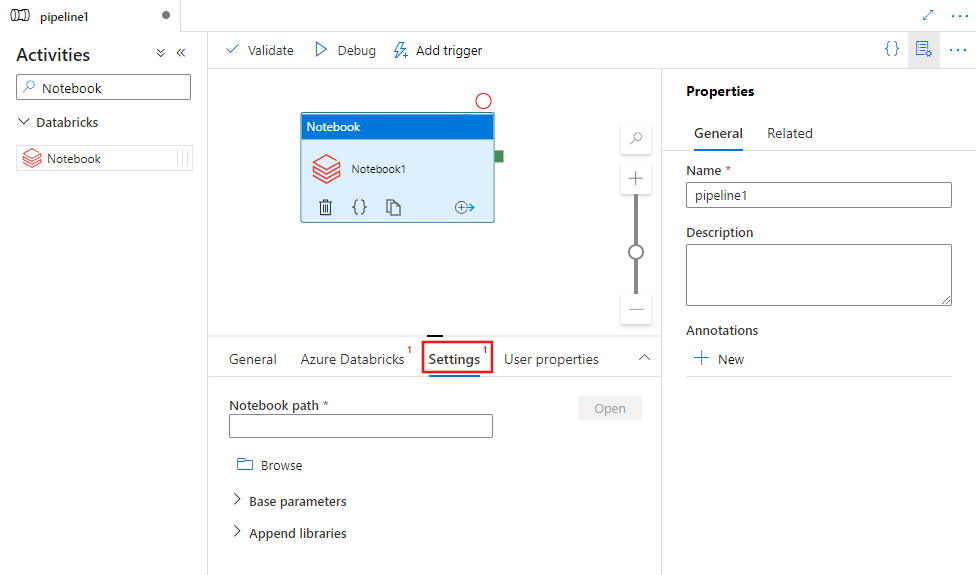
Select the Settings tab and specify the notebook path to be executed on Azure Databricks, optional base parameters to be passed to the notebook, and any other libraries to be installed on the cluster to execute the job.
Here's the sample JSON definition of a Databricks Notebook Activity:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
The following table describes the JSON properties used in the JSON definition:
| Property | Description | Required |
|---|---|---|
| name | Name of the activity in the pipeline. | Yes |
| description | Text describing what the activity does. | No |
| type | For Databricks Notebook Activity, the activity type is DatabricksNotebook. | Yes |
| linkedServiceName | Name of the Databricks Linked Service on which the Databricks notebook runs. To learn about this linked service, see Compute linked services article. | Yes |
| notebookPath | The absolute path of the notebook to be run in the Databricks Workspace. This path must begin with a slash. | Yes |
| baseParameters | An array of Key-Value pairs. Base parameters can be used for each activity run. If the notebook takes a parameter that isn't specified, the default value from the notebook will be used. Find more on parameters in Databricks Notebooks. | No |
| libraries | A list of libraries to be installed on the cluster that will execute the job. It can be an array of <string, object>. | No |
In the above Databricks activity definition, you specify these library types: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
For more information, see the Databricks documentation for library types.
You can pass parameters to notebooks using baseParameters property in databricks activity.
In certain cases, you might require to pass back certain values from notebook back to the service, which can be used for control flow (conditional checks) in the service or be consumed by downstream activities (size limit is 2 MB).
In your notebook, you can call dbutils.notebook.exit("returnValue") and corresponding "returnValue" will be returned to the service.
You can consume the output in the service by using expression such as
@{activity('databricks notebook activity name').output.runOutput}.Important
If you're passing JSON object, you can retrieve values by appending property names. Example:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
To obtain the dbfs path of the library added using UI, you can use Databricks CLI.
Typically the Jar libraries are stored under dbfs:/FileStore/jars while using the UI. You can list all through the CLI: databricks fs ls dbfs:/FileStore/job-jars
Use Databricks CLI (installation steps)
As an example, to copy a JAR to dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar