Features and terminology in Azure Event Hubs
Azure Event Hubs is a scalable event processing service that ingests and processes large volumes of events and data, with low latency and high reliability. For a high-level overview of the service, see What is Event Hubs?.
This article builds on the information in the overview article, and provides technical and implementation details about Event Hubs components and features.
Namespace
An Event Hubs namespace is a management container for event hubs (or topics, in Kafka parlance). It provides DNS-integrated network endpoints and a range of access control and network integration management features such as IP filtering, virtual network service endpoint, and Private Link.

Partitions
Event Hubs organizes sequences of events sent to an event hub into one or more partitions. As newer events arrive, they're added to the end of this sequence.

A partition can be thought of as a commit log. Partitions hold event data that contains the following information:
- Body of the event
- User-defined property bag describing the event
- Metadata such as its offset in the partition, its number in the stream sequence
- Service-side timestamp at which it was accepted

Advantages of using partitions
Event Hubs is designed to help with processing of large volumes of events, and partitioning helps with that in two ways:
- Even though Event Hubs is a PaaS service, there's a physical reality underneath. Maintaining a log that preserves the order of events requires that these events are being kept together in the underlying storage and its replicas and that results in a throughput ceiling for such a log. Partitioning allows for multiple parallel logs to be used for the same event hub and therefore multiplying the available raw input-output (IO) throughput capacity.
- Your own applications must be able to keep up with processing the volume of events that are being sent into an event hub. It might be complex and requires substantial, scaled-out, parallel processing capacity. The capacity of a single process to handle events is limited, so you need several processes. Partitions are how your solution feeds those processes and yet ensures that each event has a clear processing owner.
Number of partitions
The number of partitions is specified at the time of creating an event hub. It must be between one and the maximum partition count allowed for each pricing tier. For the partition count limit for each tier, see this article.
We recommend that you choose at least as many partitions as you expect that are required during the peak load of your application for that particular event hub. For tiers other than the premium and dedicated tiers, you can't change the partition count for an event hub after its creation. For an event hub in a premium or dedicated tier, you can increase the partition count after its creation, but you can't decrease them. The distribution of streams across partitions will change when it's done as the mapping of partition keys to partitions changes, so you should try hard to avoid such changes if the relative order of events matters in your application.
Setting the number of partitions to the maximum permitted value is tempting, but always keep in mind that your event streams need to be structured such that you can indeed take advantage of multiple partitions. If you need absolute order preservation across all events or only a handful of substreams, you might not be able to take advantage of many partitions. Also, many partitions make the processing side more complex.
It doesn't matter how many partitions are in an event hub when it comes to pricing. It depends on the number of pricing units (throughput units (TUs) for the standard tier, processing units (PUs) for the premium tier, and capacity units (CUs) for the dedicated tier) for the namespace or the dedicated cluster. For example, an event hub of the standard tier with 32 partitions or with one partition incur the exact same cost when the namespace is set to one TU capacity. Also, you can scale TUs or PUs on your namespace or CUs of your dedicated cluster independent of the partition count.
As partition is a data organization mechanism that allows you to publish and consume data in a parallel manner. We recommend that you balance scaling units (throughput units for the standard tier, processing units for the premium tier, or capacity units for the dedicated tier) and partitions to achieve optimal scale. In general, we recommend a maximum throughput of 1 MB/s per partition. Therefore, a rule of thumb for calculating the number of partitions would be to divide the maximum expected throughput by 1 MB/s. For example, if your use case requires 20 MB/s, we recommend that you choose at least 20 partitions to achieve the optimal throughput.
However, if you have a model in which your application has an affinity to a particular partition, increasing the number of partitions isn't beneficial. For more information, see availability and consistency.
Mapping of events to partitions
You can use a partition key to map incoming event data into specific partitions for the purpose of data organization. The partition key is a sender-supplied value passed into an event hub. It's processed through a static hashing function, which creates the partition assignment. If you don't specify a partition key when publishing an event, a round-robin assignment is used.
The event publisher is only aware of its partition key, not the partition to which the events are published. This decoupling of key and partition insulates the sender from needing to know too much about the downstream processing. A per-device or user unique identity makes a good partition key, but other attributes such as geography can also be used to group related events into a single partition.
Specifying a partition key enables keeping related events together in the same partition and in the exact order in which they arrived. The partition key is some string that is derived from your application context and identifies the interrelationship of the events. A sequence of events identified by a partition key is a stream. A partition is a multiplexed log store for many such streams.
Note
While you can send events directly to partitions, we don't recommend it, especially when high availability is important to you. It downgrades the availability of an event hub to partition-level. For more information, see Availability and Consistency.
Event publishers
Any entity that sends data to an event hub is an event publisher (synonymously used with event producer). Event publishers can publish events using HTTPS or AMQP 1.0 or the Kafka protocol. Event publishers use Microsoft Entra ID based authorization with OAuth2-issued JWT tokens or an Event Hub-specific Shared Access Signature (SAS) token to gain publishing access.
You can publish an event via AMQP 1.0, the Kafka protocol, or HTTPS. The Event Hubs service provides REST API and .NET, Java, Python, JavaScript, and Go client libraries for publishing events to an event hub. For other runtimes and platforms, you can use any AMQP 1.0 client, such as Apache Qpid.
The choice to use AMQP or HTTPS is specific to the usage scenario. AMQP requires the establishment of a persistent bidirectional socket in addition to transport level security (TLS) or SSL/TLS. AMQP has higher network costs when initializing the session, however HTTPS requires extra TLS overhead for every request. AMQP has higher performance for frequent publishers and can achieve much lower latencies when used with asynchronous publishing code.
You can publish events individually or batched. A single publication has a limit of 1 MB, regardless of whether it's a single event or a batch. Publishing events larger than this threshold is rejected.
Event Hubs throughput is scaled by using partitions and throughput-unit allocations. It's a best practice for publishers to remain unaware of the specific partitioning model chosen for an event hub and to only specify a partition key that is used to consistently assign related events to the same partition.
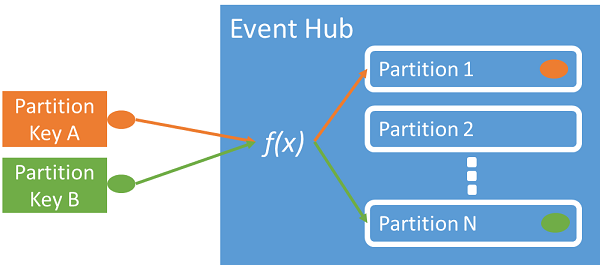
Event Hubs ensures that all events sharing a partition key value are stored together and delivered in order of arrival. If partition keys are used with publisher policies, then the identity of the publisher and the value of the partition key must match. Otherwise, an error occurs.
Event retention
Published events are removed from an event hub based on a configurable, timed-based retention policy. Here are a few important points:
- The default value and shortest possible retention period is 1 hour. Currently, you can set the retention period in hours only in the Azure portal. Resource Manager template, PowerShell, and CLI allow this property to be set only in days.
- For Event Hubs Standard, the maximum retention period is 7 days.
- For Event Hubs Premium and Dedicated, the maximum retention period is 90 days.
- If you change the retention period, it applies to all events including events that are already in the event hub.
Event Hubs retains events for a configured retention time that applies across all partitions. Events are automatically removed when the retention period has been reached. If you specified a retention period of one day (24 hours), the event becomes unavailable exactly 24 hours after it has been accepted. You can't explicitly delete events.
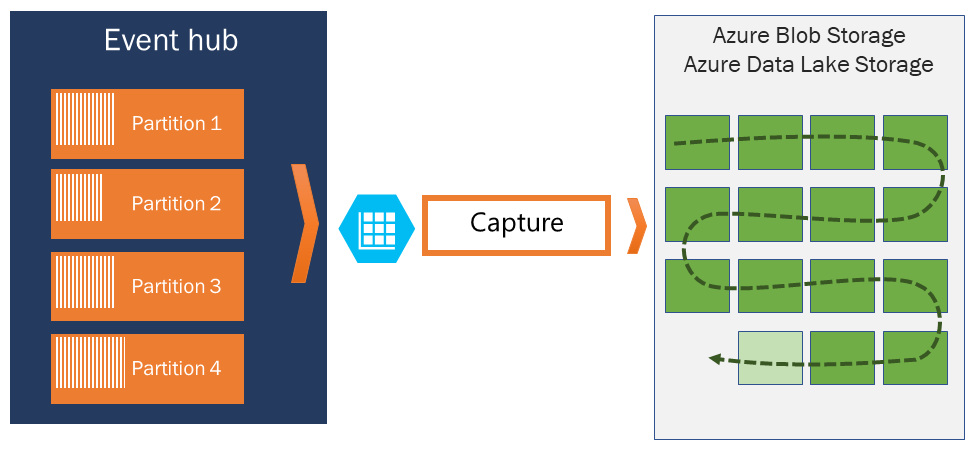
If you need to archive events beyond the allowed retention period, you can have them automatically stored in Azure Storage or Azure Data Lake by turning on the Event Hubs Capture feature. If you need to search or analyze such deep archives, you can easily import them into Azure Synapse or other similar stores and analytics platforms.
The reason for Event Hubs' limit on data retention based on time is to prevent large volumes of historic customer data getting trapped in a deep store that is only indexed by a timestamp and only allows for sequential access. The architectural philosophy here's that historic data needs richer indexing and more direct access than the real-time eventing interface that Event Hubs or Kafka provide. Event stream engines aren't well suited to play the role of data lakes or long-term archives for event sourcing.
Note
Event Hubs is a real-time event stream engine and is not designed to be used instead of a database and/or as a permanent store for infinitely held event streams.
The deeper the history of an event stream gets, the more you will need auxiliary indexes to find a particular historical slice of a given stream. Inspection of event payloads and indexing aren't within the feature scope of Event Hubs (or Apache Kafka). Databases and specialized analytics stores and engines such as Azure Data Lake Store, Azure Data Lake Analytics and Azure Synapse are therefore far better suited for storing historic events.
Event Hubs Capture integrates directly with Azure Blob Storage and Azure Data Lake Storage and, through that integration, also enables flowing events directly into Azure Synapse.
Publisher policy
Event Hubs enables granular control over event publishers through publisher policies. Publisher policies are run-time features designed to facilitate large numbers of independent event publishers. With publisher policies, each publisher uses its own unique identifier when publishing events to an event hub, using the following mechanism:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
You don't have to create publisher names ahead of time, but they must match the SAS token used when publishing an event, in order to ensure independent publisher identities. When you use publisher policies, the PartitionKey value needs to be set to the publisher name. To work properly, these values must match.
Capture
Event Hubs Capture enables you to automatically capture the streaming data in Event Hubs and save it to your choice of either a Blob storage account, or an Azure Data Lake Storage account. You can enable capture from the Azure portal, and specify a minimum size and time window to perform the capture. Using Event Hubs Capture, you specify your own Azure Blob Storage account and container, or Azure Data Lake Storage account, one of which is used to store the captured data. Captured data is written in the Apache Avro format.
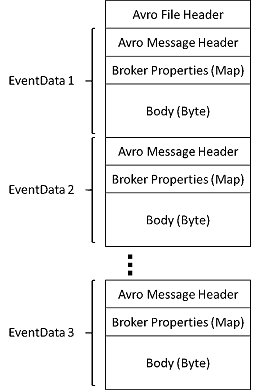
The files produced by Event Hubs Capture have the following Avro schema:
Note
When you use no code editor in the Azure portal, you can capture streaming data in Event Hubs in an Azure Data Lake Storage Gen2 account in the Parquet format. For more information, see How to: capture data from Event Hubs in Parquet format and Tutorial: capture Event Hubs data in Parquet format and analyze with Azure Synapse Analytics.
SAS tokens
Event Hubs uses Shared Access Signatures, which are available at the namespace and event hub level. A SAS token is generated from a SAS key and is an SHA hash of a URL, encoded in a specific format. Event Hubs can regenerate the hash by using the name of the key (policy) and the token and thus authenticate the sender. Normally, SAS tokens for event publishers are created with only send privileges on a specific event hub. This SAS token URL mechanism is the basis for publisher identification introduced in the publisher policy. For more information about working with SAS, see Shared Access Signature Authentication with Service Bus.
Event consumers
Any entity that reads event data from an event hub is an event consumer. All Event Hubs consumers connect via the AMQP 1.0 session and events are delivered through the session as they become available. The client doesn't need to poll for data availability.
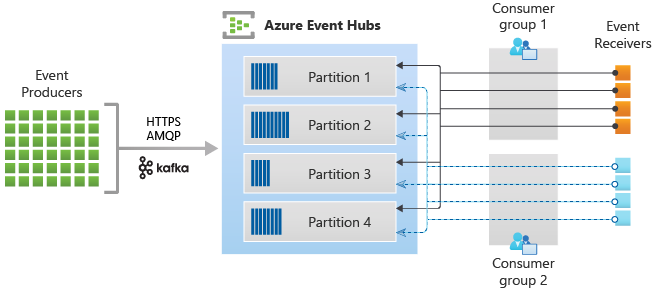
Consumer groups
The publish/subscribe mechanism of Event Hubs is enabled through consumer groups. A consumer group is a logical grouping of consumers that read data from an event hub or Kafka topic. It enables multiple consuming applications to read the same streaming data in an event hub independently at their own pace with their offsets. It allows you to parallelize the consumption of messages and distribute the workload among multiple consumers while maintaining the order of messages within each partition.
We recommend that there's only one active receiver on a partition within a consumer group. However, in certain scenarios, you can use up to five consumers or receivers per partition where all receivers get all the events of the partition. If you have multiple readers on the same partition, then you process duplicate events. You need to handle it in your code, which isn't trivial. However, it's a valid approach in some scenarios.
In a stream processing architecture, each downstream application equates to a consumer group. If you want to write event data to long-term storage, then that storage writer application is a consumer group. Complex event processing can then be performed by another, separate consumer group. You can only access partitions through a consumer group. There's always a default consumer group in an event hub, and you can create up to the maximum number of consumer groups for the corresponding pricing tier.
Some clients offered by the Azure SDKs are intelligent consumer agents that automatically manage the details of ensuring that each partition has a single reader and that all partitions for an event hub are being read from. It allows your code to focus on processing the events being read from the event hub so it can ignore many of the details of the partitions. For more information, see Connect to a partition.
The following examples show the consumer group URI convention:
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
The following figure shows the Event Hubs stream processing architecture:
Stream offsets
An offset is the position of an event within a partition. You can think of an offset as a client-side cursor. The offset is a byte numbering of the event. This offset enables an event consumer (reader) to specify a point in the event stream from which they want to begin reading events. You can specify the offset as a timestamp or as an offset value. Consumers are responsible for storing their own offset values outside of the Event Hubs service. Within a partition, each event includes an offset.
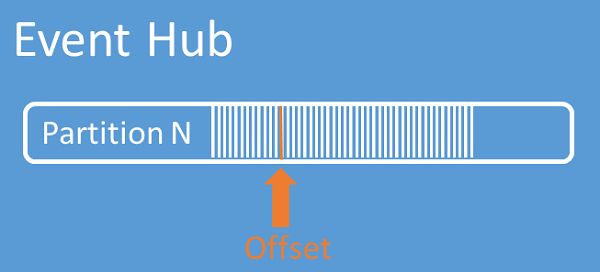
Checkpointing
Checkpointing is a process by which readers mark or commit their position within a partition event sequence. Checkpointing is the responsibility of the consumer and occurs on a per-partition basis within a consumer group. This responsibility means that for each consumer group, each partition reader must keep track of its current position in the event stream, and can inform the service when it considers the data stream complete.
If a reader disconnects from a partition, when it reconnects it begins reading at the checkpoint that was previously submitted by the last reader of that partition in that consumer group. When the reader connects, it passes the offset to the event hub to specify the location at which to start reading. In this way, you can use checkpointing to both mark events as "complete" by downstream applications, and to provide resiliency if a failover between readers running on different machines occurs. It's possible to return to older data by specifying a lower offset from this checkpointing process. Through this mechanism, checkpointing enables both failover resiliency and event stream replay.
Important
Offsets are provided by the Event Hubs service. It's the responsibility of the consumer to checkpoint as events are processed.
Follow these recommendations when using Azure Blob Storage as a checkpoint store:
- Use a separate container for each consumer group. You can use the same storage account, but use one container per each group.
- Don't use the container for anything else, and don't use the storage account for anything else.
- Storage account should be in the same region as the deployed application is located in. If the application is on-premises, try to choose the closest region possible.
On the Storage account page in the Azure portal, in the Blob service section, ensure that the following settings are disabled.
- Hierarchical namespace
- Blob soft delete
- Versioning
Log compaction
Azure Event Hubs supports compacting event log to retain the latest events of a given event key. With compacted event hubs/Kafka topic, you can use key-based retention rather than using the coarser-grained time-based retention.
For more information on log compaction, see Log compaction.
Common consumer tasks
All Event Hubs consumers connect via an AMQP 1.0 session, a state-aware bidirectional communication channel. Each partition has an AMQP 1.0 session that facilitates the transport of events segregated by partition.
Connect to a partition
When connecting to partitions, it's common practice to use a leasing mechanism to coordinate reader connections to specific partitions. This way, it's possible for every partition in a consumer group to have only one active reader. Checkpointing, leasing, and managing readers are simplified by using the clients within the Event Hubs SDKs, which act as intelligent consumer agents. They are:
- The EventProcessorClient for .NET
- The EventProcessorClient for Java
- The EventHubConsumerClient for Python
- The EventHubConsumerClient for JavaScript/TypeScript
Read events
After an AMQP 1.0 session and link is opened for a specific partition, events are delivered to the AMQP 1.0 client by the Event Hubs service. This delivery mechanism enables higher throughput and lower latency than pull-based mechanisms such as HTTP GET. As events are sent to the client, each event data instance contains important metadata such as the offset and sequence number that are used to facilitate checkpointing on the event sequence.
Event data:
- Offset
- Sequence number
- Body
- User properties
- System properties
It's your responsibility to manage the offset.
Application groups
An application group is a collection of client applications that connect to an Event Hubs namespace sharing a unique identifying condition such as the security context - shared access policy or Microsoft Entra application ID.
Azure Event Hubs enables you to define resource access policies such as throttling policies for a given application group and controls event streaming (publishing or consuming) between client applications and Event Hubs.
For more information, see Resource governance for client applications with application groups.
Apache Kafka support
The protocol support for Apache Kafka clients (versions >=1.0) provides endpoints that enable existing Kafka applications to use Event Hubs. Most existing Kafka applications can simply be reconfigured to point to an s namespace instead of a Kafka cluster bootstrap server.
From the perspective of cost, operational effort, and reliability, Azure Event Hubs is a great alternative to deploying and operating your own Kafka and Zookeeper clusters and to Kafka-as-a-Service offerings not native to Azure.
In addition to getting the same core functionality as of the Apache Kafka broker, you also get access to Azure Event Hubs features like automatic batching and archiving via Event Hubs Capture, automatic scaling and balancing, disaster recovery, cost-neutral availability zone support, flexible and secure network integration, and multi-protocol support including the firewall-friendly AMQP-over-WebSockets protocol.
Next steps
For more information about Event Hubs, visit the following links:
- Get started with Event Hubs
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for