Cet exemple de scénario montre comment les données peuvent être ingérées dans un environnement cloud à partir d’un entrepôt de données local, puis utilisées à l’aide d’un modèle décisionnel (BI). Cette approche peut être un objectif final ou une première étape vers une modernisation complète avec des composants basés sur le cloud.
Les étapes suivantes s’appuient sur le scénario Azure Synapse Analytics de bout en bout. Il utilise Azure Pipelines pour ingérer des données d’une base de données SQL dans les pools SQL Azure Synapse, puis transforme les données à des fins d’analyse.
Architecture

Téléchargez un fichier Visio de cette architecture.
Workflow
Source de données
- Les données sources sont situées dans une base de données SQL Server dans Azure. Pour simuler l’environnement local, les scripts de déploiement pour ce scénario approvisionnent une base de données Azure SQL. L’exemple de base de données AdventureWorks est utilisé comme schéma de données source et échantillon de données. Pour plus d’informations sur la copie de données à partir d’une base de données locale, consultez copier et transformer des données vers et depuis SQL Server.
Ingestion et stockage de données
Azure Data Lake Gen2 est utilisé comme zone intermédiaire temporaire pendant l’ingestion des données. Vous pouvez ensuite utiliser PolyBase pour copier des données dans un pool SQL dédié Azure Synapse.
Azure Synapse Analytics est un système distribué conçu pour réaliser des tâches d’analytique sur de grandes quantités de données. Il prend en charge le traitement MPP (Massive Parallel Processing), le rendant ainsi adapté à l’exécution d’analyses hautes performances. Le pool SQL Azure Synapse dédié est une cible pour l’ingestion continue à partir d’un emplacement local. Il peut être utilisé pour un traitement ultérieur, ainsi que pour utiliser les données pour Power BI via DirectQuery.
Azure Pipelines est utilisé pour orchestrer l’ingestion et la transformation des données dans votre espace de travail Azure Synapse.
Analyse et rapports
- L’approche de modélisation des données de ce scénario est présentée en combinant le modèle d’entreprise et le modèle sémantique BI. Le modèle d’entreprise est stocké dans un pool SQL dédié Azure Synapse, et le modèle sémantique BI est stocké dans les fonctionnalités Power BI Premium. Power BI accède aux données via DirectQuery.
Components
Ce scénario utilise les composants suivants :
Architecture simplifiée
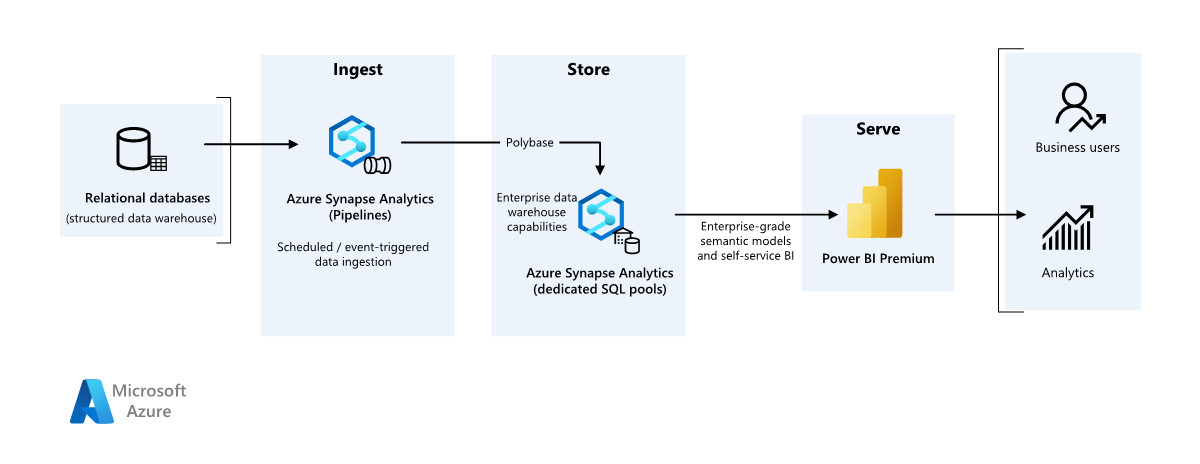
Détails du scénario
Une organisation dispose d’un entrepôt de données local volumineux stocké dans une base de données SQL. L'organisation souhaite utiliser Azure Synapse pour effectuer des analyses, puis utiliser ces informations à l'aide de Power BI.
Authentification
Microsoft Entra authentifie les utilisateurs qui se connectent aux tableaux de bord et applications Power BI. L’authentification unique est utilisée pour se connecter à la source de données dans un pool provisionné Azure Synapse. L’autorisation se produit sur la source.
Chargement incrémentiel
Lorsque vous exécutez un processus automatisé d'extraction-transformation-chargement (ETL) ou d'extraction-chargement-transformation (ELT), il est plus efficace de charger uniquement les données qui ont changé depuis l'exécution précédente. Il s’agit d’un chargement incrémentiel, par opposition à un chargement complet, qui porte sur toutes les données. Pour effectuer un chargement incrémentiel, vous avez besoin d’une méthode d’identification des données modifiées. L’approche la plus courante consiste à utiliser une valeur limite supérieure, qui se traduit par le suivi de la valeur la plus récente d’une colonne de la table source, soit une colonne DateHeure, soit une colonne d’entier unique.
À compter de SQL Server 2016, vous pouvez utiliser des tables temporelles, qui sont des tables avec version système qui conservent un historique complet des modifications de données. Le moteur de base de données enregistre automatiquement l’historique de chaque modification dans une table d’historique distincte. Vous pouvez interroger les données d’historique en ajoutant une clause FOR SYSTEM_TIME à une requête. En interne, le moteur de base de données interroge la table d’historique, mais cette opération est transparente pour l’application.
Notes
Pour les versions antérieures de SQL Server, vous pouvez utiliser la fonction Capture des changements de données (CDC). Cette approche est moins pratique que les tables temporelles, car vous devez interroger une table de modifications distincte, et les modifications font l’objet d’un suivi par numéro séquentiel dans le journal plutôt que par horodatage.
Les tables temporelles sont utiles pour les données de dimension, qui peuvent changer au fil du temps. Les tables de faits représentent généralement une transaction immuable, comme une vente. De ce fait, il n’est pas utile de conserver l’historique des versions du système. Au lieu de cela, les transactions incluent généralement une colonne qui représente la date de transaction, qui peut être utilisée en tant que la valeur de filigrane. Par exemple, dans l’entrepôt de données d'AdventureWorks, les tables SalesLT.* ont un champ LastModified.
Voici le flux général du pipeline ELT :
Pour chaque table de la base de données source, effectuez le suivi de l’heure de coupure lors de l’exécution du dernier travail ELT. Stockez ces informations dans l’entrepôt de données. Lors de la configuration initiale, toutes les heures sont définies sur
1-1-1900.Lors de l’étape d’exportation des données, l’heure de coupure est transmise sous la forme d’un paramètre à un ensemble de procédures stockées dans la base de données source. Ces procédures stockées demandent au système tous les enregistrements ayant été modifiés ou créés après l’heure de coupure. Pour toutes les tables de l’exemple, vous pouvez utiliser la colonne
ModifiedDate.Lorsque la migration des données est terminée, mettez à jour la table qui stocke les heures de coupure.
Pipeline de données
Ce scénario utilise l’exemple de base de données AdventureWorks comme source de données. Le modèle de chargement incrémentiel des données est implémenté pour nous assurer que nous chargeons uniquement les données qui ont été modifiées ou ajoutées après l’exécution la plus récente du pipeline.
Outil de copie pilotée par les métadonnées
L’outil de copie pilotée par les métadonnées intégré dans Azure Pipelines charge de manière incrémentielle toutes les tables contenues dans notre base de données relationnelle. En parcourant l’expérience basée sur l’assistant, vous pouvez connecter l’outil Copier des données à la base de données source et configurer le chargement incrémentiel ou complet pour chaque table. L’outil Copier des données crée ensuite les pipelines et les scripts SQL pour générer la table de contrôle requise pour stocker les données pour le processus de chargement incrémentiel, par exemple la valeur/colonne de limite élevée pour chaque table. Une fois ces scripts exécutés, le pipeline est prêt à charger toutes les tables de l’entrepôt de données source dans le pool dédié Synapse.
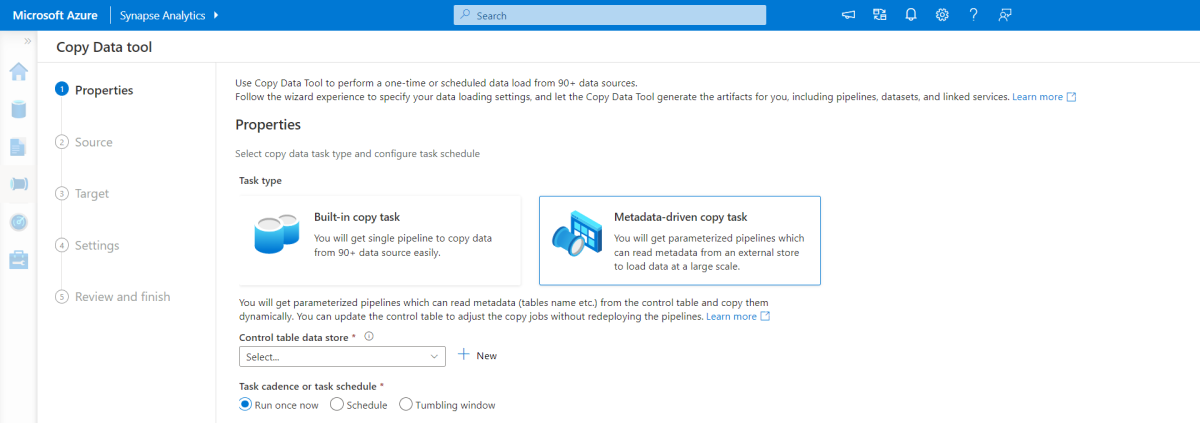
L’outil crée trois pipelines pour itérer sur toutes les tables de la base de données, avant de charger les données.
Pipelines générés par cet outil :
- Comptez le nombre d’objets, tels que les tables, à copier dans l’exécution du pipeline.
- Itérez sur chaque objet à charger/copier, puis :
- Vérifiez si une charge delta est requise ; sinon, terminez une charge complète normale.
- Récupérez la valeur de limite élevée de la table de contrôle.
- Copiez les données des tables sources dans le compte intermédiaire dans ADLS Gen2.
- Chargez des données dans le pool SQL dédié via la méthode de copie sélectionnée, par exemple, Polybase, commande Copier.
- Mettez à jour la valeur de limite élevée dans la table de contrôle.
Charger des données dans un pool SQL Azure Synapse
L’activité de copie copie les données de la base de données SQL dans le pool SQL Azure Synapse. Dans cet exemple, étant donné que notre base de données SQL se trouve dans Azure, nous utilisons le runtime d’intégration Azure pour lire les données de la base de données SQL et écrire les données dans l’environnement intermédiaire spécifié.
L’instruction de copie est ensuite utilisée pour charger des données à partir de l’environnement intermédiaire dans le pool dédié Synapse.
utiliser Azure Pipelines
Les pipelines dans Azure Synapse sont utilisés pour définir l’ensemble ordonné d’activités pour terminer le modèle de charge incrémentielle. Les déclencheurs sont utilisés pour démarrer le pipeline, qui peut être déclenché manuellement ou à un moment spécifié.
Transformer les données
Étant donné que l’exemple de base de données dans notre architecture de référence n’est pas volumineux, nous avons créé des tables répliquées sans partitions. Pour les charges de travail de production, l’utilisation de tables distribuées a des chances d’améliorer les performances de requête. Consultez Guide de conception de tables distribuées dans Azure Synapse. Les exemples de scripts exécutent les requêtes avec une classe de ressources statique.
Dans un environnement de production, envisagez de créer des tables intermédiaires avec une distribution par tourniquet. Ensuite, transformez et déplacez les données dans des tables de production avec des index columnstore en cluster, qui offrent les meilleures performances globales en matière de requêtes. Les index columnstore sont optimisés pour les requêtes qui analysent de nombreux enregistrements. Les index columnstore ne sont pas aussi efficaces pour les recherches singleton (rechercher une seule ligne). Si vous avez besoin d’effectuer fréquemment des recherches singleton, vous pouvez ajouter un index non cluster à une table. Les recherches singleton peuvent s’exécuter bien plus rapidement avec un index non cluster. Toutefois, elles sont généralement moins fréquentes dans des scénarios d’entrepôt de données que des charges de travail OLTP. Pour plus d'informations, consultez Indexage de tables dans Azure Synapse.
Notes
Les tables columnstore cluster ne prennent pas en charge les types de données varchar(max), nvarchar(max) ou varbinary(max). Dans ces cas, préférez utiliser un segment de mémoire ou un index cluster. Vous pouvez placer ces colonnes dans une table distincte.
Utiliser Power BI Premium pour accéder, modéliser et visualiser des données
Power BI Premium prend en charge plusieurs options de connexion aux sources de données sur Azure, notamment un pool provisionné Azure Synapse :
- Importation : les données sont importées dans le modèle Power BI.
- DirectQuery : les données sont extraites directement du stockage relationnel.
- Modèle composite : combinez l’importation pour certaines tables et DirectQuery pour d’autres.
Ce scénario est fourni avec le tableau de bord DirectQuery, car la quantité de données utilisées et la complexité du modèle ne sont pas élevées. Nous pouvons donc offrir une bonne expérience utilisateur. DirectQuery délègue la requête au puissant moteur de calcul et utilise des fonctionnalités de sécurité étendues sur la source. De plus, DirectQuery veille à ce que les résultats soient toujours cohérents avec les données sources les plus récentes.
Le mode d’importation fournit le temps de réponse de requête le plus rapide et doit être pris en compte lorsque le modèle s’intègre entièrement à la mémoire de Power BI. La latence des données entre les actualisations peut être tolérée et il peut y avoir des transformations complexes entre le système source et le modèle final. Dans ce cas, les utilisateurs finaux souhaitent accéder pleinement aux données les plus récentes sans retard dans l’actualisation de Power BI et toutes les données historiques, qui sont plus volumineuses qu’un jeu de données Power BI, entre 25 et 400 Go, en fonction de la taille de la capacité. Étant donné que le modèle de données dans le pool SQL dédié se trouve déjà dans un schéma en étoile et n’a besoin d’aucune transformation, DirectQuery est un choix approprié.
Power BI Premium Gen2 vous donne la possibilité de gérer des modèles volumineux, des rapports paginés, des pipelines de déploiement et un point de terminaison Analysis Services intégré. Vous pouvez également avoir une capacité dédiée avec une proposition de valeur unique.
Lorsque le modèle BI augmente ou que la complexité du tableau de bord augmente, vous pouvez basculer vers des modèles composites et commencer à importer des parties de tables de recherche, via des tables hybrides et certaines données pré-agrégées. L’activation de la mise en cache des requêtes dans Power BI pour les jeux de données importés est une option, ainsi que l’utilisation de tables doubles pour la propriété en mode de stockage.
Dans le modèle composite, les jeux de données agissent comme une couche pass-through virtuelle. Lorsque l’utilisateur interagit avec des visualisations, Power BI génère des requêtes SQL vers des pools SQL Synapse à double stockage : en mémoire ou en requête directe, selon l’efficacité de celle-ci. Le moteur décide quand passer d’une requête en mémoire directe à une requête directe et envoie la logique au pool SQL Synapse. Selon le contexte des tables de requête, ils peuvent agir comme des modèles composites mis en cache (importés) ou non mis en cache. Choisissez la table à mettre en cache en mémoire, combinez les données d’une ou plusieurs sources DirectQuery et/ou combinez des données à partir d’une combinaison de sources DirectQuery et de données importées.
Recommandations : Lors de l’utilisation de DirectQuery sur un pool provisionné Azure Synapse Analytics :
- Utilisez la mise en cache des ensembles de résultats d'Azure Synapse pour mettre en cache les résultats des requêtes dans la base de données de l'utilisateur pour une utilisation répétitive, améliorer les performances des requêtes jusqu'à quelques millisecondes et réduire l'utilisation des ressources de calcul. Les requêtes utilisant des jeux de résultats mis en cache n’utilisent aucun emplacement d’accès concurrentiel dans Azure Synapse Analytics et ne sont donc pas comptabilisées par rapport aux limites de concurrence existantes.
- Utilisez les vues matérialisées d’Azure Synapse pour pré-calculer, stocker et maintenir les données comme une table. Les requêtes qui utilisent la totalité ou un sous-ensemble des données des vues matérialisées peuvent obtenir des performances plus rapides, et elles n'ont pas besoin de faire une référence directe à la vue matérialisée définie pour l'utiliser.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
Les violations de données, les infections liées à des programmes malveillants et les injections de code malveillant, que l’on retrouve souvent à la une des actualités, font partie d’une longue liste de problèmes de sécurité pour les entreprises qui cherchent à tirer parti du cloud. Les clients en entreprise ont besoin d’un fournisseur de cloud ou d’une solution de service qui puisse répondre à leurs préoccupations, car ils ne peuvent pas se permettre de commettre des erreurs.
Ce scénario répond aux problèmes de sécurité les plus exigeants à l’aide d’une combinaison de contrôles de sécurité en couches : réseau, identité, confidentialité et autorisation. La majeure partie des données est stockée dans un pool approvisionné Azure Synapse, avec Power BI à l’aide de DirectQuery via l’authentification unique. Vous pouvez utiliser Microsoft Entra ID pour l’authentification. Il existe également des contrôles de sécurité étendus pour l’autorisation des données des pools approvisionnés.
Voici quelques-unes des questions de sécurité courantes :
- Comment vérifier qui peut voir les données et quelles sont les données visibles ?
- Les organisations doivent protéger leurs données conformément aux recommandations émises à l’échelle régionale, locale et de l’entreprise pour atténuer les risques de violation de données. Azure Synapse offre plusieurs fonctionnalités de protection des données pour assurer la conformité.
- Quelles sont les options permettant de vérifier l’identité d’un utilisateur ?
- Azure Synapse prend en charge un large éventail de fonctionnalités qui permet de contrôler qui peut accéder aux données par contrôle d'accès et authentification.
- Quelle technologie de sécurité réseau puis-je utiliser pour protéger l’intégrité, la confidentialité et l’accès de mes réseaux et des mes données ?
- Pour sécuriser Azure Synapse, il existe toute une gamme d’options de sécurité réseau à prendre en compte.
- Quels sont les outils qui détectent les menaces et me notifient leur existence ?
- Azure Synapse fournit plusieurs fonctionnalités de détection des menaces comme : un service d’audit SQL, de détection des menaces SQL et d’évaluation des vulnérabilités pour assurer l’audit, la protection et le monitoring des bases de données.
- Que puis-je faire pour protéger les données dans mon compte de stockage ?
- Les comptes de stockage Azure sont parfaits pour les charges de travail qui nécessitent des temps de réponse rapides et cohérents, ou qui ont un nombre élevé d’opérations d’entrée-sortie (IOP) par seconde. Les comptes de stockage contiennent tous vos objets de données du Stockage Azure et disposent de nombreuses options pour la sécurité des comptes de stockage.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Cette section fournit des informations sur la tarification des différents services impliqués dans cette solution et mentionne les décisions prises pour ce scénario avec un exemple de jeu de données.
Azure Synapse
Une architecture serverless Azure Synapse Analytics vous permet de mettre à l’échelle vos niveaux de calcul et de stockage de façon indépendante. Les ressources de calcul sont facturées selon l’utilisation et vous pouvez mettre ces ressources à l’échelle ou en pause à la demande. Les ressources de stockage sont facturées au téraoctet. Vos coûts augmentent donc en fonction du volume de données ingéré.
Azure Pipelines
Vous trouverez les détails de tarification des pipelines dans Azure Synapse sous l’onglet Intégration des données dans la page de tarification d’Azure Synapse. Il existe trois composants principaux qui influencent le prix d’un pipeline :
- Activités du pipeline de données et heures du runtime d’intégration
- Taille et exécution du cluster de flux de données
- Frais d’opération
Le prix varie en fonction des composants ou des activités, de la fréquence et du nombre d’unités d’exécution d’intégration.
Pour l'ensemble de données de l'exemple, le runtime d'intégration standard hébergé par Azure, c’est-à-dire l’activité de copie de données pour le cœur du pipeline, est déclenché selon un calendrier quotidien pour toutes les entités (tables) de la base de données source. Le scénario ne contient aucun flux de données. Il n’y a aucun coût opérationnel, car il y a moins de 1 million d’opérations avec des pipelines par mois.
Pool dédié et stockage Azure Synapse
Vous trouverez les détails de tarification des pools dédiés Azure Synapse sous l’onglet Entrepôt de données dans la page de tarification d’Azure Synapse. Dans le modèle de consommation dédiée, les clients sont facturés par unités DWU approvisionnées, par heure de disponibilité. Le coût du stockage des données est un autre facteur contributif : taille de vos données au repos + instantanés + géo-redondance, le cas échéant.
Pour l’exemple de jeu de données, vous pouvez provisionner 500DWU, ce qui garantit une bonne expérience de charge analytique. Vous pouvez maintenir le calcul opérationnel pendant les heures de création de rapports. En cas de production, la capacité de l’entrepôt de données réservé est une option intéressante pour la gestion des coûts. Différentes techniques doivent être utilisées pour optimiser les métriques de coût/performances, qui sont décrites dans les sections précédentes.
Stockage d'objets blob
Envisagez d'utiliser la fonctionnalité de capacité réservée du Stockage Azure pour réduire les coûts de stockage. Avec ce modèle, vous bénéficiez d'une remise si vous réservez une capacité de stockage fixe pendant un ou trois ans. Pour plus d'informations, consultez Optimiser les coûts de stockage d'objets blob avec une capacité réservée.
Il n’existe aucun stockage persistant dans ce scénario.
Power BI Premium
Les détails des prix de Power BI Premium se trouvent sur la page des prix de Power BI.
Ce scénario utilise les espaces de travail Power BI Premium avec une série d'améliorations de performance intégrées pour répondre aux besoins analytiques exigeants.
Excellence opérationnelle
L’excellence opérationnelle couvre les processus d’exploitation qui déploient une application et maintiennent son fonctionnement en production. Pour plus d’informations, consultez Vue d’ensemble du pilier Excellence opérationnelle.
Recommandations de DevOps
Créez des groupes de ressources distincts pour les environnements de production, de développement et de test. Des groupes de ressources distincts simplifient la gestion des déploiements, la suppression des déploiements de tests et l’attribution des droits d’accès.
Placez chaque charge de travail dans un modèle de déploiement distinct et stockez les ressources dans des systèmes de contrôle de code source. Vous pouvez déployer les modèles ensemble ou individuellement dans le cadre d'un processus d'intégration continue (CI) et de livraison continue (CD), ce qui facilite le processus d'automatisation. Cette architecture comprend quatre charges de travail principales :
- Serveur d'entrepôt de données et ressources connexes
- Pipelines Azure Synapse
- Ressources Power BI : tableaux de bord, applications, jeux de données
- Scénario simulé de site local vers le cloud
Essayez d’avoir un modèle de déploiement distinct pour chacune des charges de travail.
Envisagez la préproduction de vos charges de travail dans la mesure du possible. Déployez à différentes étapes et effectuez des vérifications de la validation à chaque étape avant de passer à l'étape suivante. Vous pourrez ainsi envoyer (push) les mises à jour de vos environnements de production de manière contrôlée et limiter les problèmes de déploiement imprévus. Utilisez les stratégies Déploiement Blue-Green et Mises en production Canary pour mettre à jour les environnements de production.
Bénéficiez d'une bonne stratégie de restauration pour gérer les déploiements qui ont échoué. Par exemple, vous pouvez automatiquement relancer un déploiement antérieur réussi à partir de votre historique de déploiement. Voir l'indicateur
--rollback-on-errordans Azure CLI.Azure Monitor est l'option recommandée pour analyser les performances de votre entrepôt de données et de l'ensemble de la plateforme Azure Analytics pour une expérience de supervision intégrée. Azure Synapse Analytics fournit une expérience de supervision sur le portail Azure pour présenter des insights à la charge de travail de votre entrepôt de données. Le portail Azure est l'outil recommandé pour superviser votre entrepôt de données car il offre des périodes de conservation configurables, des alertes, des suggestions, ainsi que des graphiques et des tableaux de bord personnalisables pour les métriques et les journaux d'activité.
Démarrage rapide
- Portail : Preuve de concept d'Azure Synapse
- Azure CLI : Créer un espace de travail Azure Synapse avec Azure CLI
- Terraform : Entrepôt de données moderne avec Terraform et Microsoft Azure
Efficacité des performances
L’efficacité des performances est la capacité de votre charge de travail à s’adapter à la demande des utilisateurs de façon efficace. Pour plus d’informations, consultez Vue d’ensemble du pilier d’efficacité des performances.
Cette section fournit des détails sur les décisions de dimensionnement pour prendre en charge ce jeu de données.
Pool provisionné Azure Synapse
Il existe une gamme de configurations d’entrepôt de données à choisir.
| Data Warehouse Units | # de nœuds de calcul | # de distributions par nœud |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Pour découvrir les avantages d’une montée en puissance en termes de niveau de performance, en particulier dans le cas des valeurs DWU les plus élevées, vous devez utiliser un jeu de données d’au moins 1 To. Pour déterminer le nombre d’unités DWU idéal pour votre pool SQL dédié, essayez d’effectuer un sale-up et un scale-down. Exécutez quelques requêtes avec différentes valeurs DWU après avoir chargé vos données. La mise à l’échelle étant rapide, vous pouvez essayer plusieurs niveaux de performances en une heure ou moins.
Trouver le meilleur nombre d’unités d’entrepôt de données
Pour un pool SQL dédié en développement, commencez par sélectionner un nombre plus réduit d’unités DWU. DW400c ou DW200c est un bon point de départ. Analysez les performances de votre application, en observant notamment le nombre d’unités DWU sélectionné. Déterminez la mesure dans laquelle vous devez augmenter ou diminuer le nombre d’unités DWU à l’aide d’une mise à l’échelle linéaire. Continuez à effectuer des ajustements jusqu’à ce que vous atteigniez le niveau de performances requis par vos activités.
Mise à l’échelle du pool SQL Synapse
- Mettre à l’échelle le calcul pour le pool SQL Synapse à l’aide du portail Azure
- Mettre à l’échelle le calcul pour le pool SQL dédié avec Azure PowerShell
- Mettre à l’échelle les ressources de calcul d’un pool SQL dédié dans Azure Synapse Analytics à l’aide de T-SQL
- Suspendre, surveiller et automatiser
Azure Pipelines
Pour connaître les fonctionnalités d’évolutivité et d’optimisation des performances des pipelines dans Azure Synapse et l’activité de copie utilisée, reportez-vous au guide de performances et d’évolutivité de l’activité de copie.
Power BI Premium
Cet article utilise Power BI Premium Gen2 pour illustrer les fonctionnalités BI. Les références SKU de capacité pour Power BI Premium vont de P1 (huit cœurs virtuels) à P5 (128 cœurs v) actuellement. La meilleure façon de sélectionner la capacité nécessaire consiste à subir une évaluation du chargement de capacité, à installer l’application de métriques Gen 2 pour la surveillance continue et à utiliser la mise à l’échelle automatique avec Power BI Premium.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteurs principaux :
- Galina Polyakova | Architecte de solution cloud senior
- Noah Costar | Architecte de solution cloud
- George Stevens | Architecte de solution cloud
Autres contributeurs :
- Jim McLeod | Architecte de solution cloud
- Miguel Myers | Responsable du programme principal
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Qu’est-ce que Power BI Premium ?
- Qu’est-ce que Microsoft Entra ID ?
- Accès au stockage Azure Data Lake Storage Gen2 et au Stockage Blob avec Azure Databricks
- Présentation d’Azure Synapse Analytics
- Pipelines et activités dans Azure Data Factory et Azure Synapse Analytics
- Qu'est-ce que SQL Azure ?