Cette architecture de référence présente une architecture de microservices déployée sur Azure Service Fabric. Elle illustre une configuration en cluster de base qui peut être le point de départ de la plupart des déploiements.
 Une implémentation de référence de cette architecture est disponible sur GitHub.
Une implémentation de référence de cette architecture est disponible sur GitHub.
Architecture
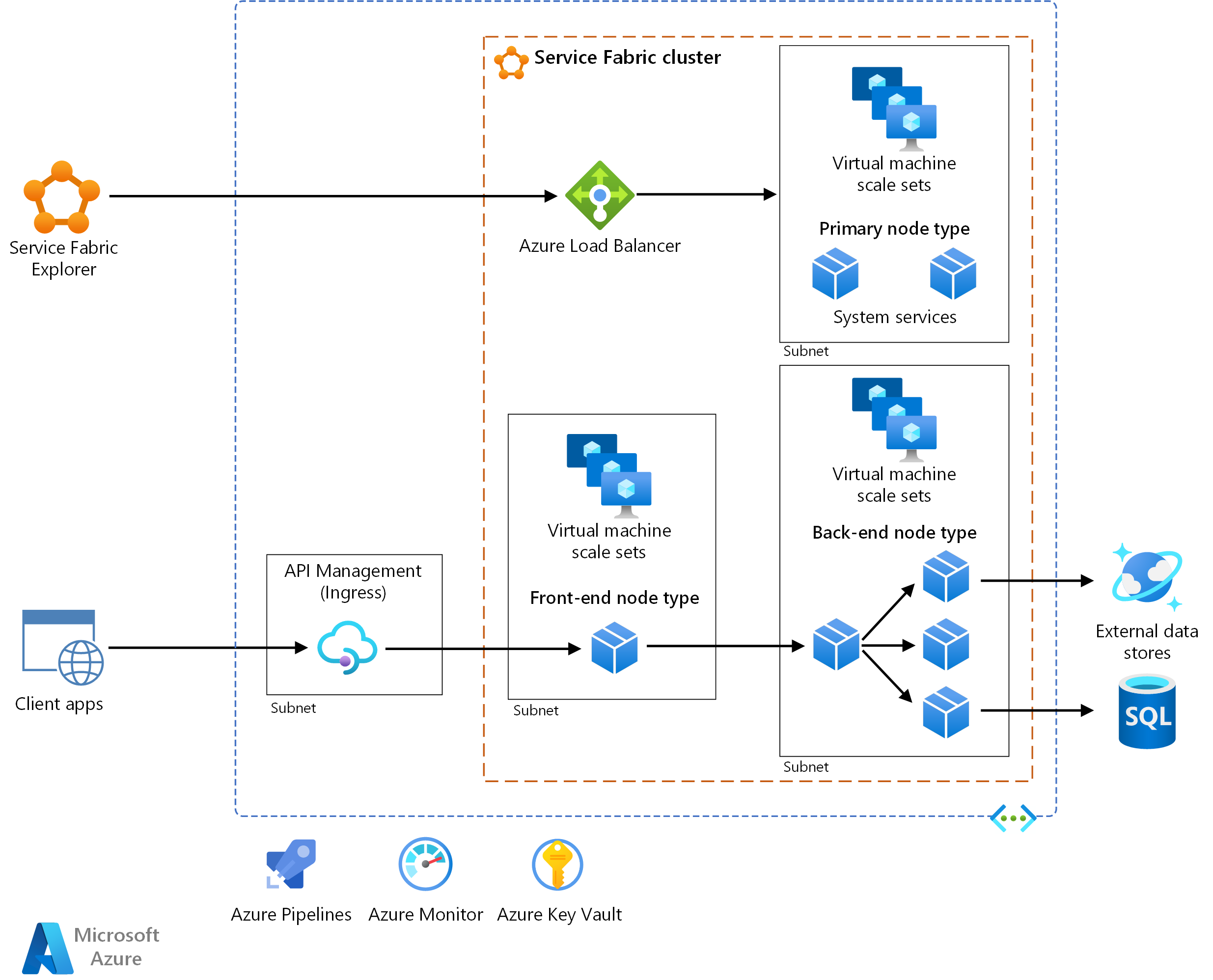
Téléchargez un fichier Visio de cette architecture.
Notes
Cet article se concentre sur le modèle de programmation Reliable Services pour Service Fabric. L’utilisation de Service Fabric pour déployer et gérer des conteneurs dépasse le cadre de cet article.
Workflow
L’architecture est constituée des composants suivants. Pour les autres termes, voir Présentation de la terminologie Service Fabric.
Cluster Service Fabric. Un cluster est un ensemble connecté au réseau de machines virtuelles dans lequel vous déployez et gérez vos microservices.
Groupes de machines virtuelles identiques. Les groupes de machines virtuelles identiques vous permettent de créer et de gérer un groupe de machines virtuelles identiques, disposant d’une charge équilibrée et d’une mise à l’échelle automatique. Ces ressources de calcul fournissent également les domaines d’erreur et de mise à niveau.
Nœuds. Les nœuds sont les machines virtuelles qui appartiennent au cluster Service Fabric.
Types de nœuds. Un type de nœud représente un groupe de machines virtuelles identiques qui déploie une collection de nœuds. Un cluster Service Fabric doit comprendre au moins un type de nœud.
Dans un cluster qui a plusieurs types de nœuds, l’un d’eux doit être déclaré comme type de nœud principal. Les services système Service Fabric s’exécutent sur le type de nœud principal de votre cluster. Ces services fournissent les fonctionnalités de plateforme de Service Fabric. Le type de nœud principal agit également en tant que seed nodes, qui sont les nœuds qui maintiennent la disponibilité du cluster sous-jacent.
Configurez des types de nœuds supplémentaires pour exécuter vos services.
Services. Un service exécute une fonction autonome qui peut démarrer et s’exécuter indépendamment d’autres services. Les instances de services sont déployées sur les nœuds du cluster. Il existe deux types de services dans Service Fabric :
- Service sans état. Un service sans état ne conserve pas l’état dans le service. Si la persistance d’état est requise, l’état est écrit et extrait à partir d’un magasin externe, tel que Azure Cosmos DB.
- Service avec état. L’état du service est conservé dans le service lui-même. La plupart des services avec état implémentent cela par le biais de Collections fiables dans Service Fabric.
Service Fabric Explorer. Service Fabric Explorer est un outil open source dédié à l’inspection et à la gestion des clusters Azure Service Fabric.
Azure Pipelines. Azure Pipelines fait partie d'Azure DevOps Services, et effectue des builds, des tests et des déploiements automatisés. Vous pouvez également utiliser des solutions tierces d’intégration continue et de livraison continue (CI/CD), telles que Jenkins.
Azure Monitor. Azure Monitor recueille et stocke les métriques et journaux d’activité, notamment les métriques de plateforme pour les services Azure dans les données de télémétrie d’application et de solution. Utilisez ces données pour superviser l’application, définir des alertes et des tableaux de bord et effectuer une analyse de la cause racine des échecs. Azure Monitor s’intègre à Service Fabric pour collecter des métriques à partir des contrôleurs, nœuds et conteneurs ainsi que des journaux d’activité de conteneurs et des journaux d’activité des nœuds principaux.
Azure Key Vault. Utilisez Key Vault pour stocker les secrets d’application que les microservices utilisient, tels que les chaînes de connexion.
Azure API Management : Dans cette architecture, APIM agit comme une passerelle d’API qui accepte les requêtes des clients et les achemine vers vos services.
Considérations
Ces considérations mettent en œuvre les piliers d’Azure Well-Architected Framework, qui est un ensemble de principes directeurs pour améliorer la qualité d’une charge de travail.
Remarques relatives à la conception
Cette architecture de référence est axée sur les architectures de microservices. Un microservice est une petite unité de code avec version indépendante. Il est détectable par le biais de mécanismes de détection de service et peut communiquer avec d’autres services par le biais d’API. Chaque service est autonome et doit implémenter une fonctionnalité unique. Pour plus d’informations sur la façon de décomposer votre domaine d’application en microservices, consultez Utilisation de l’analyse de domaine pour modeler des microservices.
Service Fabric fournit une infrastructure pour créer, déployer et mettre à niveau efficacement les microservices. Il fournit également des options pour la mise à l’échelle automatique, la gestion de l’état, la surveillance de l’intégrité et le redémarrage des services en cas de défaillance.
Service Fabric suit un modèle d’application dans lequel une application est une collection de microservices. L’application est décrite dans un fichier manifeste d’application . Ce fichier définit les types de services que contient l’application, ainsi que des pointeurs vers les packages de service indépendants.
Le package d’application contient également généralement des paramètres qui servent de remplacements pour certains paramètres que les services utilisent. Chaque package de service possède un fichier manifeste qui décrit les fichiers et dossiers physiques nécessaires à l’exécution de ce service, y compris les fichiers binaires, les fichiers de configuration et les données en lecture seule. Les services et les applications sont gérés indépendamment et peuvent être mis à niveau.
Le manifeste d’application peut éventuellement décrire des services qui sont automatiquement approvisionnés lorsqu’une instance de l’application est créée. Il s’agit des services par défaut. Dans ce cas, le manifeste d’application décrit également comment ces services doivent être créés. Ces informations incluent le nom du service, le nombre d’instances, la stratégie de sécurité ou d’isolation et les contraintes de placement du service.
Notes
Évitez d’utiliser les services par défaut si vous souhaitez contrôler la durée de vie de vos services. Les services par défaut sont créés lors de la création de l’application et ils s’exécutent tant que l’application est en cours d’exécution.
Pour plus d’informations, lisez Vous voulez en savoir plus sur Service Fabric ?.
Modèle d’empaquetage d’application à service
Un principe des microservices est que chaque service peut être déployé indépendamment. Dans Service Fabric, si vous regroupez l’ensemble de vos services dans un package d’application unique et que l’un des services ne peut pas être mis à niveau, la mise à niveau complète de l’application est restaurée. Cette restauration empêche la mise à niveau d’un autre service.
Pour cette raison, dans une architecture de microservices, nous vous recommandons d’utiliser plusieurs packages d’applications. Placez un ou plusieurs types de service étroitement liés dans un seul type d’application. Par exemple, placez les types de service dans le même type d’application si votre équipe est responsable d’un ensemble de services qui ont l’un des attributs suivants :
- Ils s’exécutent pendant la même durée et doivent être mis à jour en même temps.
- Ils ont le même cycle de vie.
- Ils partagent des ressources telles que les dépendances ou la configuration.
Modèle de programmation Service Fabric
Lorsque vous ajoutez un microservice à une application Service Fabric, déterminez s’il possède un état ou des données qui doivent être rendues hautement disponibles et fiables. Dans ce cas, peut-il stocker des données en externe ou les données contenues dans le cadre du service ? Choisissez un service sans état si vous n’avez pas besoin de stocker des données ou si vous souhaitez les stocker dans un espace de stockage externe. Envisagez de choisir un service avec état si l’une des instructions suivantes s’applique :
- Vous souhaitez conserver l’état ou les données dans le cadre du service. Par exemple, vous avez besoin que ces données résident dans la mémoire proche du code.
- Vous ne pouvez pas tolérer une dépendance à un magasin externe.
Si vous disposez d’un code existant que vous souhaitez exécuter sur Service Fabric, vous pouvez l’exécuter en tant qu’exécutable invité : un exécutable arbitraire qui s’exécute en tant que service. Vous pouvez également créer un package de l’exécutable dans un conteneur qui dispose de toutes les dépendances nécessaires pour le déploiement.
Service Fabric modélise les conteneurs et les exécutables invités en tant que services sans état. Pour obtenir des conseils sur le choix d’un modèle, consultez Présentation du modèle de programmation Service Fabric.
Vous êtes responsable de la maintenance de l’environnement dans lequel s’exécute un exécutable invité. Supposons, par exemple, qu’un exécutable invité nécessite Python. Si l’exécutable n’est pas autonome, vous devez vous assurer que la version requise de Python est préinstallée dans l’environnement. Service Fabric ne gère pas l’environnement. Azure offre plusieurs mécanismes pour configurer l’environnement, y compris les images et les extensions de machines virtuelles personnalisées.
Pour accéder à un exécutable invité via un proxy inverse, vérifiez que vous avez ajouté l’attribut UriScheme à l’élément Endpoint dans le manifeste de service de l’exécutable invité.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Si le service a des itinéraires supplémentaires, spécifiez les itinéraires dans la valeur PathSuffix. La valeur ne doit pas être préfixée ou suffixée avec une barre oblique (/). Une autre méthode consiste à ajouter l’itinéraire dans le nom du service.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Pour plus d'informations, consultez les pages suivantes :
Passerelle API
Une passerelle API (entrée) se trouve entre les clients externes et les microservices. Elle fait office de proxy inverse, acheminant les demandes des clients vers les microservices. Elle peut également effectuer des tâches transversales telles que l'authentification, l'arrêt SSL et la limitation du débit.
Nous recommandons Gestion des API pour la plupart des scénarios, mais Traefik est une solution open source populaire. Les deux options de technologie sont intégrées à Service Fabric.
Gestion des API. Expose une adresse IP publique et achemine le trafic vers vos services. Il s’exécute dans un sous-réseau dédié dans le même réseau virtuel que le cluster Service Fabric.
Gestion des API peut accéder aux services d’un type de nœud qui est exposé via un équilibreur de charge avec une adresse IP privée. Cette fonctionnalité est uniquement disponible dans les niveaux Premium et Développeur de Gestion des API. Utilisez le niveau Premium pour les charges de travail de production. Les informations de tarification sont disponibles sur la page Tarification de Gestion des API.
Pour plus d’informations, voir Service Fabric dans Vue d’ensemble d’Azure Gestion des API.
Traefik. Prend en charge des fonctionnalités telles que le routage, le suivi, les journaux et les métriques. Traefik s’exécute en tant que service sans état dans le cluster Service Fabric. Le contrôle de version de service peut être pris en charge via le routage.
Pour plus d’informations sur la configuration de Traefik pour l’entrée de service et sur le proxy inverse au sein du cluster, voir Fournisseur Azure Service Fabric sur le site web Traefik. Pour plus d’informations sur l’utilisation de Traefik avec Service Fabric, voir le billet de blog Routage intelligent sur Service Fabric avec Traefik.
Traefik, contrairement à Azure Gestion des API, ne dispose pas de fonctionnalités permettant de résoudre la partition d’un service avec état (avec plus d’une partition) vers laquelle une requête est routée. Pour plus d’informations, consultez Ajouter un correspondant pour les services de partitionnement.
Les autres options de Gestion des API incluent Azure Application Gateway et Azure Front Door. Vous pouvez utiliser ces services conjointement avec Gestion des API pour effectuer des tâches telles que le routage, la terminaison SSL et le pare-feu.
Communication entre les services
Pour faciliter la communication de service à service, tenez compte des recommandations suivantes :
Protocole de communication. Dans une architecture de microservices, les services doivent communiquer entre eux avec un couplage minimal au moment de l’exécution. Pour la communication sans langage spécifié, HTTP fournit un choix normalisé avec des outils et des serveurs HTTP disponibles dans plusieurs langues. Service Fabric prend en charge tous ces outils et serveurs.
Pour la plupart des charges de travail, nous vous recommandons d’utiliser HTTP au lieu de la communication à distance du service intégrée à Service Fabric.
Détection des services. Pour communiquer avec d’autres services au sein d’un cluster, un service client doit résoudre l’emplacement actuel du service cible. Dans Service Fabric, les services peuvent se déplacer entre les nœuds et entraîner une modification dynamique des points de terminaison de service.
Pour éviter les connexions à des points de terminaison obsolètes, vous pouvez utiliser le service d’affectation de noms dans Service Fabric pour récupérer les informations de point de terminaison mises à jour. Toutefois, Service Fabric fournit également un service de proxy inverse intégré qui extrait le service d’attribution de noms. Nous vous recommandons cette option pour la découverte de services comme base de référence pour la plupart des scénarios, car elle est plus facile à utiliser et génère du code plus simple.
D’autres options pour la communication entre les services incluent :
- Traefik pour le routage avancé.
- DNS pour les scénarios de compatibilité où un service s’attend à utiliser DNS.
- La classe ServicePartitionClient<TCommunicationClient> qui met en cache les points de terminaison de service. Elle peut offrir de meilleures performances, car les appels passent directement entre les services sans intermédiaires ou protocoles personnalisés.
Extensibilité
Service Fabric prend en charge la mise à l’échelle de ces entités de cluster :
- Mise à l’échelle du nombre de nœuds pour chaque type de nœud
- Mise à l’échelle des services
Cette section se concentre sur la mise à l’échelle automatique. Vous pouvez choisir de mettre à l’échelle manuellement dans les cas appropriés. Par exemple, une intervention manuelle peut être nécessaire pour définir le nombre d’instances.
Configuration initiale du cluster pour l’évolutivité
Lorsque vous créez un cluster Service Fabric, approvisionnez les types de nœuds en fonction de vos besoins en matière de sécurité et d’évolutivité. Chaque type de nœud est mappé à un groupe de machines virtuelles identiques et peut être mis à l’échelle indépendamment.
- Créez un type de nœud pour chaque groupe de services qui ont des exigences de mise à l’échelle ou de ressources différentes. Commencez par approvisionner un type de nœud (qui devient le type de nœud principal) pour les services système Service Fabric. Créez des types de nœuds distincts pour exécuter vos services publics ou frontaux. Créez d’autres types de nœuds en fonction des besoins de votre back-end et des services privés ou isolés. Spécifiez les contraintes de sélection élective afin que les services soient déployés uniquement sur les types de nœuds prévus.
- Spécifiez le niveau de durabilité pour chaque type de nœud. Le niveau de durabilité représente la capacité de Service Fabric à influencer les mises à jour et les opérations de maintenance dans les groupes de machines virtuelles identiques. Pour les charges de travail de production, choisissez un niveau de durabilité Silver ou plus élevé. Pour plus d’informations, consultez Caractéristiques de durabilité du cluster.
- Si vous utilisez le niveau de durabilité bronze, certaines opérations nécessitent des étapes manuelles. Les types de nœuds avec le niveau de durabilité Bronze nécessitent des étapes supplémentaires pendant le scale-in. Pour plus d’informations sur les opérations de mise à l’échelle, consultez ce guide.
Mise à l’échelle des nœuds
Service Fabric prend en charge la mise à l'échelle automatique pour le scale-in et le scale-out. Vous pouvez configurer chaque type de nœud pour la mise à l’échelle automatique indépendamment.
Chaque cluster peut compter un maximum de 100 nœuds. Commencez avec un ensemble de nœuds plus petit et ajoutez des nœuds supplémentaires en fonction de votre charge. Si vous avez besoin de plus de 100 nœuds dans un type de nœud, vous devrez ajouter des types de nœuds supplémentaires. Pour plus de détails, voir Considérations en matière de planification de la capacité du cluster Service Fabric. Un groupe de machines virtuelles identiques n’est pas mis à l’échelle instantanément. Tenez compte de ce facteur lorsque vous configurez des règles de mise à l’échelle automatique.
Pour prendre en charge la mise à l’échelle automatique, configurez le type de nœud pour avoir le niveau de durabilité Silver ou Gold. Cette configuration permet de s’assurer que la mise à l’échelle est retardée jusqu’à ce que Service Fabric termine le déplacement des services. Il s'assure également que les jeux d'échelles des machines virtuelles informent Service Fabric que les machines virtuelles sont supprimées, et pas seulement temporairement hors service.
Pour plus d’informations sur la mise à l’échelle au niveau du nœud/cluster, consultez Mise à l’échelle des clusters Azure Service Fabric.
Mise à l’échelle des services
Les services avec et sans état appliquent des approches différentes de mise à l’échelle.
Pour un service sans état (mise à l’échelle automatique) :
- Utilisez le déclencheur de charge moyenne de la partition. Ce déclencheur détermine le moment où le service est en scale-in ou en scale-out, en fonction d’une valeur de seuil de charge spécifiée dans la stratégie de mise à l’échelle. Vous pouvez également définir la fréquence à laquelle le déclencheur est vérifié. Voir Déclencheur de charge moyenne de partitions avec mise à l’échelle basée sur les instances. Cette approche vous permet de mettre à l’échelle le nombre de nœuds disponibles.
- Définissez
InstanceCountsur -1 dans le manifeste de service, qui indique à Service Fabric d’exécuter une instance du service sur chaque nœud. Cette approche permet au service de s’adapter de manière dynamique à mesure que le cluster est mis à l’échelle. À mesure que le nombre de nœuds dans le cluster change, Service Fabric crée et supprime automatiquement des instances de service à faire correspondre.
Notes
Dans certains cas, vous souhaiterez peut-être mettre à l’échelle manuellement votre service. Par exemple, si vous avez un service qui lit à partir de Azure Event Hubs, vous souhaiterez peut-être qu’une instance dédiée soit lue à partir de chaque partition Event Hub. De cette façon, vous pouvez éviter l’accès simultané à la partition.
Pour un service avec état, la mise à l’échelle est contrôlée par le nombre de partitions, la taille de chaque partition et le nombre de partitions ou réplicas en cours d’exécution sur un ordinateur :
Si vous créez des services partitionnés, assurez-vous que chaque nœud obtient les réplicas adéquats pour une distribution égale de la charge de travail sans provoquer de conflits de ressources. Si vous ajoutez plus de nœuds, Service Fabric distribue les charges de travail sur les nouveaux ordinateurs par défaut. Par exemple, s’il y a 5 nœuds et 10 partitions, Service Fabric placera deux réplicas principaux sur chaque nœud par défaut. Si vous effectuer un scale-out sur les nœuds, vous pouvez obtenir de meilleures performances, car le travail est réparti uniformément entre les ressources supplémentaires.
Pour plus d’informations sur les scénarios qui tirent parti de cette stratégie, consultez Mise à l’échelle dans Service Fabric.
L’ajout ou la suppression de partitions n’est pas bien pris en charge. Une autre option qui est couramment utilisée pour mettre à l’échelle consiste à créer ou supprimer dynamiquement des services ou des instances d’application entières. Un exemple de ce modèle est décrit dans Mise à l’échelle en créant ou en supprimant de nouveaux services nommés.
Pour plus d'informations, consultez les pages suivantes :
- Augmenter ou diminuer la taille des instances d’un cluster Service Fabric à l’aide de règles de mise à l’échelle automatique ou manuellement
- Mettre à l’échelle un cluster Service Fabric par programmation
- Effectuer un scale-out d’un cluster Service Fabric en ajoutant un groupe de machines virtuelles identiques
Utilisation des mesures pour équilibrer la charge
Selon la façon dont vous concevez la partition, vous pouvez avoir des nœuds avec des réplicas qui obtiennent plus de trafic que d’autres. Afin d’éviter cela, partitionnez l’état pour garantir une répartition équitable entre toutes les partitions. Utilisez le schéma de partitionnement par plage avec le bon algorithme de hachage. Voir Prise en main du partitionnement.
Service Fabric utilise des métriques pour savoir comment placer et équilibrer les services au sein d’un cluster. Vous pouvez spécifier une charge par défaut pour chaque mesure associée à un service lors de la création de ce service. Service Fabric prend ensuite cette charge en compte lors du placement du service, ou chaque fois que le service doit se déplacer (par exemple, pendant les mises à niveau) pour équilibrer les nœuds du cluster.
La charge par défaut spécifiée initialement pour un service ne change pas pendant la durée de vie du service. Pour capturer les mesures changeantes pour un service, nous vous recommandons de surveiller votre service et de signaler la charge dynamiquement. Cette approche permet à Service Fabric d’ajuster l’allocation en fonction de la charge signalée à un moment donné. Utilisez la méthode IServicePartition.ReportLoad pour signaler des métriques personnalisées. Pour plus d'informations, consultez Charge dynamique.
Disponibilité
Placer vos services dans un type de nœud autre que le type de nœud principal. Les services système de Service Fabric sont toujours déployés sur le type de nœud principal. Si vos services sont déployés sur le type de nœud principal, ils peuvent être en concurrence avec (et interférer avec) les services système pour les ressources. Si un type de nœud est supposé héberger des services avec état, assurez-vous qu’il existe au moins cinq instances de nœud et que vous sélectionnez le niveau de durabilité Silver ou Gold.
Envisagez de limiter les ressources de vos services. Voir Mécanisme de la gouvernance des ressources.
Voici des considérations courantes :
- Ne mélangez pas les services régis par les ressources et les services qui ne sont pas régis par les ressources sur le même type de nœud. Les services non régis peuvent consommer un trop grand nombre de ressources et affecter les services régis. Spécifiez lescontraintes de sélection élective pour vous assurer que ces types de services ne s’exécutent pas sur le même ensemble de nœuds. (Il s’agit d’un exemple de modèle de cloisonnement.)
- Spécifiez les cœurs de processeur et la mémoire à réserver pour une instance de service. Pour plus d’informations sur l’utilisation et les limitations des stratégies de gouvernance des ressources, voirGouvernance des ressources.
Pour éviter un point de défaillance unique (SPOF), assurez-vous que le nombre d’instances cibles ou de réplicas de chaque service est supérieur à un. Le nombre le plus élevé que vous pouvez utiliser comme instance de service ou nombre de réplicas est égal au nombre de nœuds qui restreignent le service.
Assurez-vous que chaque service avec état a au moins deux réplicas secondaires actifs. Nous recommandons cinq réplicas pour les charges de travail de production.
Pour plus d’informations, voir Disponibilité des services Service Fabric.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
Voici quelques points clés pour la sécurisation de votre application sur Service Fabric.
Réseau virtuel
Envisagez de définir des limites de sous-réseau pour chaque groupe de machines virtuelles identiques afin de contrôler le déroulement de la communication. Chaque type de nœud possède son propre groupe de machines virtuelles identiques dans un sous-réseau au sein du réseau virtuel du cluster Service Fabric. Vous pouvez ajouter des groupes de sécurité réseau (NSG) aux sous-réseaux pour autoriser ou rejeter le trafic réseau. Par exemple, avec les types de nœuds frontaux et back-end, vous pouvez ajouter un NSG au sous-réseau back-end pour n'accepter le trafic entrant que du sous-réseau frontal.
Lorsque vous appelez les services Azure externes à partir du cluster, utilisez les Points de terminaison de service de réseau virtuel si le service Azure les prend en charge. L’utilisation d’un point de terminaison de service sécurise le service uniquement sur le réseau virtuel du cluster.
Par exemple, si vous utilisez Azure Cosmos DB pour stocker des données, configurez le compte Azure Cosmos DB avec un point de terminaison de service pour autoriser l’accès uniquement à partir d’un sous-réseau spécifique. Voir Accéder aux ressources Azure Cosmos DB à partir de réseaux virtuels.
Points terminaux et communication entre les services
Ne créez pas de cluster Service Fabric non sécurisé. Les utilisateurs anonymes peuvent se connecter au cluster si les points de terminaison de gestion sont exposés sur l’Internet public. Les clusters non sécurisés ne sont pas gérés pour les charges de travail de production. Consultez Scénarios de sécurité d’un cluster Service Fabric.
Pour aider à sécuriser vos communications interservice :
- Vous pouvez activer les points de terminaison HTTPS dans vos services web ASP.NET Core ou Java.
- Établissez une connexion sécurisée entre le proxy inverse et les services. Pour plus d’informations, consultez Se connecter à un service sécurisé.
Si vous utilisez une passerelle API, vous pouvez déléguer l’authentification à la passerelle. Vérifiez que les services individuels ne sont pas accessibles directement (sans la passerelle API), sauf si une mesure de sécurité supplémentaire a été mise en place pour authentifier les messages.
N’exposez pas publiquement le proxy inverse de Service Fabric. Ainsi, tous les services qui exposent des points de terminaison HTTP sont adressables depuis l'extérieur du cluster. Cela introduit des failles de sécurité et expose potentiellement des informations supplémentaires en dehors du cluster inutilement. Si vous souhaitez accéder publiquement à un service, utilisez une passerelle API. La section Passerelle d’API plus loin dans cet article mentionne certaines options.
Le Bureau à distance est utile pour le diagnostic et la résolution des problèmes, mais veillez à le fermer. Le laisser ouvert provoque un trou de sécurité.
Secrets et certificats
Stocker des secrets tels que des chaînes de connexion à des magasins de données dans un coffre de clés. Le coffre de clés doit se trouver dans la même région que le groupe de machines virtuelles identiques qu’il protège. Pour utiliser un coffre de clés :
Authentifier l’accès du service au coffre de clés.
Activer l’identité managée sur le groupe de machines virtuelles identiques qui héberge le service.
Stocker vos secrets dans le coffre de clés.
Ajouter des secrets dans un format qui peut être traduit en une paire clé-valeur. Par exemple, utilisez
CosmosDB--AuthKey. Lorsque la configuration est générée, le trait d’union double (--) est converti en deux-points (:).Accédez à ces secrets dans votre service.
Ajoutez l’URI du coffre de clés dans votre fichier appSettings.json . Dans votre service, ajoutez le fournisseur de configuration qui lit à partir du coffre de clés, crée la configuration et accède à la clé secrète à partir de la configuration générée.
Voici un exemple dans lequel le service de workflow stocke un secret dans le coffre de clés au format CosmosDB--Database.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Pour accéder au secret, spécifiez le nom du secret dans la configuration du built.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
N’utilisez pas de certificats clients pour accéder à Service Fabric Explorer. Utilisez plutôt Microsoft Entra ID. Consultez Services Azure prenant en charge l’authentification Microsoft Entra.
N’utilisez pas un certificat auto-signé dans un environnement de production.
Protection des données au repos
Si vous avez attaché des disques de données aux groupes de machines virtuelles identiques du cluster Service Fabric et que vos services enregistrent des données sur ces disques, vous devez chiffrer les disques. Pour plus d’informations, consultez Chiffrer des disques de données joints et de systèmes d’exploitation dans un groupe de machines virtuelles identiques avec Azure PowerShell (préversion).
Pour plus d'informations sur Service Fabric, consultez :
- Vue d’ensemble de la sécurité Azure Service Fabric
- Bonnes pratiques pour la sécurité Azure Service Fabric
- Liste de contrôle pour la sécurité Azure Service Fabric
Résilience
Pour récupérer après des défaillances et maintenir un état entièrement fonctionnel, l’application doit implémenter certains modèles de résilience. Voici quelques modèles courants :
- Nouvelle tentative: pour gérer les erreurs que vous prévoyez d’être temporaires, telles que les ressources temporairement indisponibles.
- Disjoncteur : Pour résoudre les erreurs qui peuvent prendre plus de temps pour résoudre le problème.
- Cloisonnement : pour isoler les ressources de chaque service.
Cette implémentation de référence utilise Polly, une option Open source, pour implémenter tous ces modèles.
Surveillance
Avant d’explorer les options de surveillance, nous vous recommandons de lire cet article abordant les diagnostics des scénarios courants avec Service Fabric. Vous pouvez analyser les données dans les ensembles suivants :
- Métriques d'application et journaux d'activité
- Données sur l'intégrité et les événements Service Fabric
- Métriques et journaux d’infrastructure
- Métriques et journaux pour les services dépendants
Voici les deux principales options pour l’analyse de ces données :
- Application Insights
- Log Analytics
Vous pouvez utiliser Azure Monitor pour configurer des tableaux de bord pour l’analyse et pour envoyer des alertes aux opérateurs. Des outils de surveillance tiers sont également intégrés à Service Fabric, tels que Dynatrace. Pour plus détails, consultez Solutions de partenaires pour la surveillance d’Azure Service Fabric.
Métriques d'application et journaux d'activité
La télémétrie d’application fournit des données qui peuvent vous aider à surveiller l’intégrité de votre service et à identifier les problèmes. Pour ajouter des traces et des événements dans votre service :
- Utiliser Microsoft.Extensions.Logging si vous développez votre service avec ASP.NET Core. Pour d’autres infrastructures, utilisez une bibliothèque de journalisation de votre choix, telle que Serilog.
- Ajoutez votre propre instrumentation à l’aide de la classe TelemetryClient dans le kit de développement logiciel (SDK) et afficher les données dans Application Insights. Voir Ajouter une instrumentation personnalisée à votre application.
- Journaliser les événements de suivi des événements pour Windows (ETW) à l’aide d’EventSource. Cette option est disponible par défaut dans toute solution Visual Studio Service Fabric.
Application Insights fournit un grand nombre de données de télémétrie intégrées : requêtes, traces, événements, exceptions, métriques, dépendances. Si votre service expose des points de terminaison HTTP, activez Application Insights en appelant la méthode d’extension UseApplicationInsights pour Microsoft.AspNetCore.Hosting.IWebHostBuilder. Pour plus d’informations sur l’instrumentation de votre service pour Application Insights, consultez les articles suivants :
- Tutoriel : surveiller et diagnostiquer une application ASP.NET Core dans Service Fabric
- Application Insights pour ASP.NET Core
- Kit SDK .NET d’Application Insights
- Application Insights SDK pour Service Fabric
Pour afficher les traces et les journaux des événements, utilisez Application Insights comme un des récepteurs pour la journalisation structurée. Configurez Application Insights avec votre clé d’instrumentation en appelant la méthode d’extension AddApplicationInsights. Dans cet exemple, la clé d’instrumentation est stockée en tant que secret dans le coffre de clés.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Si votre service n’expose pas de points de terminaison HTTP, vous devez écrire une extension personnalisée qui envoie des traces à Application Insights. Pour obtenir un exemple, consultez le service de flux de travail dans l’implémentation de référence.
Les services ASP.NET Core utilisent l’interface ILogger pour la journalisation des applications. Pour rendre ces journaux des applications disponibles dans Azure Monitor, envoyez les événements ILogger à Application Insights. Application Insights peut ajouter des propriétés de corrélation aux événements ILogger, ce qui est utile pour visualiser le traçage distribué.
Pour plus d'informations, consultez les pages suivantes :
Données sur l'intégrité et les événements Service Fabric
La télémétrie Service Fabric comprend des mesures de l'intégrité et des événements concernant le fonctionnement et les performances d'un cluster Service Fabric et de ses entités : ses nœuds, applications, services, partitions et réplicas. Les données d’intégrité et d’événement peuvent provenir des :
EventStore. Ce service système avec état collecte les événements liés au cluster et à ses entités. Service Fabric utilise EventStore pour écrire les événements Service Fabric afin de fournir des informations sur votre cluster pour les mises à jour d’état, la résolution des problèmes et la surveillance. EventStore peut également corréler des événements à partir d’entités différentes à un moment donné pour identifier les problèmes dans le cluster. Le service expose ces événements par le biais d’une API REST.
Pour plus d’informations sur la façon d’interroger les API EventStore, consultez Interroger les API EventStore API pour les événement de cluster. Vous pouvez afficher les événements d’EventStore dans Log Analytics en configurant votre cluster avec l’extension Diagnostics Azure pour Windows (WAD).
HealthStore. Ce service avec état fournit un instantané de l’intégrité actuelle du cluster. Il agrège toutes les données d’intégrité signalées par les entités dans une hiérarchie. Les données sont visualisées dans Service Fabric Explorer. HealthStore surveille également les mises à niveau des applications. Vous pouvez utiliser des requêtes d’intégrité dans PowerShell, une application .NET ou des API REST. Voir Présentation du contrôle d'intégrité de Service Fabric.
Rapports d’intégrité personnalisés. Considérez l’implémentation de services de surveillance qui peuvent régulièrement signaler des données d’intégrité personnalisées, telles que les états défectueux des services en cours d’exécution. Vous pouvez lire les rapports d’intégrité dans Service Fabric Explorer.
Métriques et journaux d’infrastructure
Les métriques de l’infrastructure vous aident à comprendre l’allocation des ressources dans le cluster. Voici les principales options pour la collecte de ces informations :
- WAD. Collecter les journaux et les métriques au niveau du nœud sur Windows. Vous pouvez utiliser le WAD en configurant l'extension IaaSDiagnostics VM sur tout ensemble d'échelles de machines virtuelles mappé à un type de nœud pour collecter les événements de diagnostic. Ces événements peuvent inclure des journaux d’événements Windows, des compteurs de performances, des événements système et opérationnel ETW/manifeste, ainsi que des journaux personnalisés.
- Agent Log Analytics. Configurez l’extension de machine virtuelle MicrosoftMonitoringAgent pour envoyer les journaux des événements Windows, les compteurs de performances et les journaux personnalisés à Log Analytics.
Il y a un certain chevauchement dans les types de mesures collectées par les mécanismes précédents, comme les compteurs de performance. En cas de chevauchement, nous vous recommandons d’utiliser l’agent Log Analytics. Étant donné que l’agent Log Analytics n’utilise pas le stockage Azure, la latence est faible. En outre, les compteurs de performance dans IaaSDiagnostics ne peuvent pas être alimentés facilement dans Log Analytics.
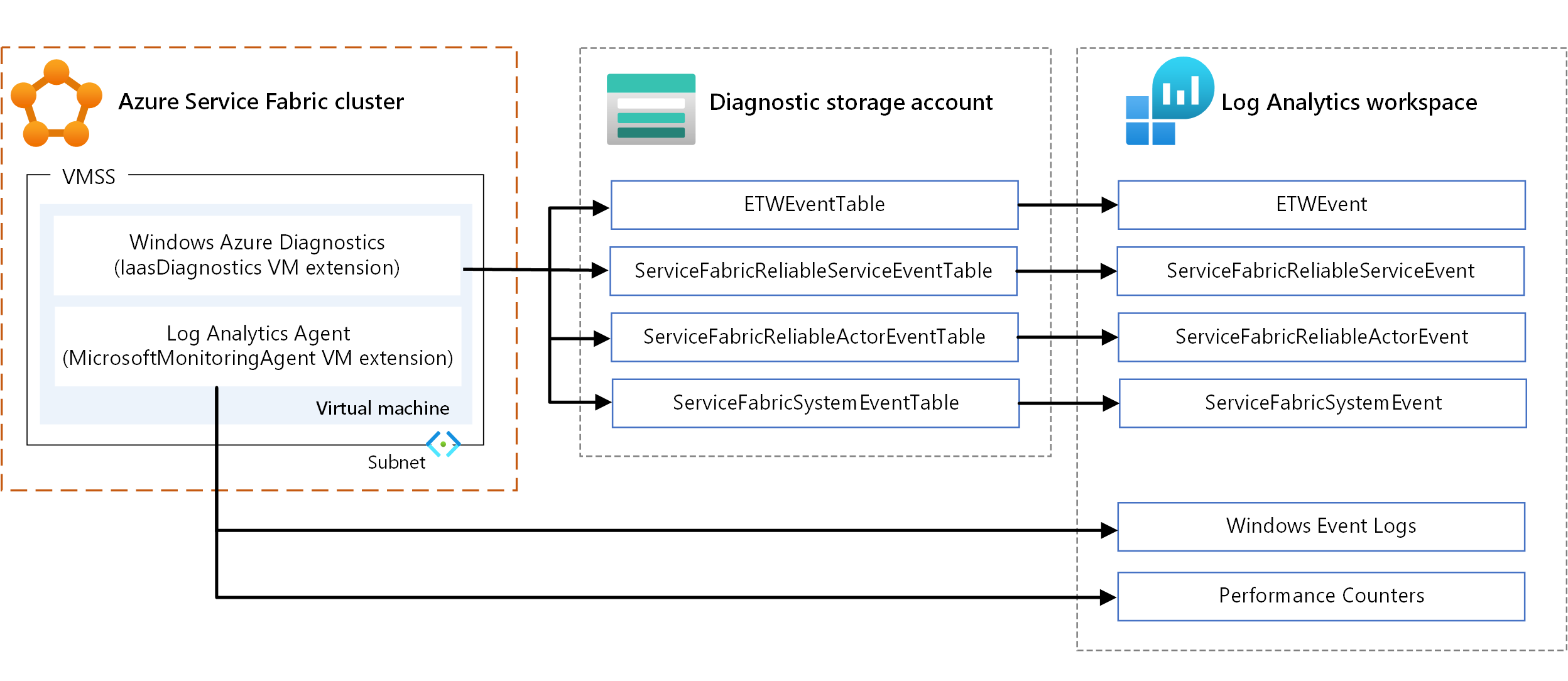
Pour des informations sur les extensions de machine virtuelle, consultez Extensions et fonctionnalités des machines virtuelles Azure.
Pour afficher les données, configurez Log Analytics pour afficher les données collectées par le biais de WAD. Pour plus d’informations sur la configuration de Log Analytics pour lire des événements à partir d’un compte de stockage, consultez Configurer Log Analytics pour un cluster.
Vous pouvez également consulter les journaux des performances et les données de télémétrie relatives à un cluster de Service Fabric, les charges de travail, le trafic réseau, les mises à jour en cours, etc. Voir Analyse des performances avec Log Analytics.
Service Map dans Log Analytics fournit des informations sur la topologie du cluster (autrement dit, les processus en cours d’exécution dans chaque nœud). Envoyez les données du compte de stockage à Application Insights. L’obtention de données dans Application Insights peut prendre un certain temps. Si vous souhaitez afficher les données en temps réel,vous pouvez configurer Event Hubs en utilisant des récepteurs et des canaux. Pour plus d’informations, voir Agrégation et collecte d’événements à l’aide de WAD.
Mesures des services dépendants
- La cartographie d’application dans Application Insights fournit la topologie de l’application à l’aide des appels de dépendance HTTP effectués entre les services, avec le kit de développement logiciel (SDK) Application Insights installé.
- Service Map dans Log Analytics fournit des informations sur le trafic entrant et sortant à partir de et vers les services externes. Service Map s’intègre à d’autres solutions telles que les mises à jour ou la sécurité.
- Les surveillances personnalisées peuvent signaler des conditions d’erreur sur des services externes. Par exemple, le service peut fournir un rapport d’intégrité d’erreur s’il ne peut pas accéder à un service externe ou à un stockage de données (Azure Cosmos DB).
Traçage distribué
Dans une architecture de microservices, plusieurs services participent souvent à la réalisation d’une tâche. La télémétrie de chacun de ces services est corrélée par des champs de contexte (comme l’ID de l’opération et l’ID de la demande) dans une trace distribuée.
En utilisant la cartographie d’application dans Application Insights, vous pouvez créer la vue d’opérations logiques distribuées et visualiser l’ensemble du graphique de service de votre application. Vous pouvez également utiliser les diagnostics de transaction dans Application Insights pour mettre en corrélation la télémétrie côté serveur. Pour plus d’informations, voir Diagnostics de transaction entre composants unifiés.
Il est également important de mettre en corrélation des tâches distribuées de façon asynchrone à l’aide d’une file d’attente. Pour plus d’informations sur l’envoi de données de télémétrie de corrélation dans un message de file d’attente, consultez Instrumentation de file d’attente.
Pour plus d'informations, consultez les pages suivantes :
- Exécution d’une requête sur plusieurs ressources
- Corrélation de télémétrie dans Application Insights
Alertes et tableaux de bord
Application Insights et Log Analytics prennent en charge un langage de requête étendu (langage de requête Kusto) qui vous permet de récupérer et d’analyser les données de journal. Utilisez les requêtes pour créer des jeux de données et les visualiser dans les tableaux de bord de diagnostic.
Utilisez les alertes Azure Monitor pour notifier les administrateurs système lorsque certaines conditions se produisent dans des ressources spécifiques. La notification peut être un e-mail, une fonction Azure ou un webhook, par exemple. Pour plus d’informations, consultez Alertes dans Azure Monitor.
Les règles d’alerte de recherche de journal vous permettent de définir et d’exécuter une requête Kusto sur un espace de travail Log Analytics à intervalles réguliers. Une alerte est créée si le résultat de la requête correspond à une condition donnée.
Optimisation des coûts
Utiliser la calculatrice de prix Azure pour estimer les coûts. D'autres considérations sont décrites dansPillier d’optimisation des coûts de Microsoft Azure Well-Architected Framework.
Voici quelques points à prendre en compte pour certains des services utilisés dans cette architecture.
Azure Service Fabric
Vous êtes facturé pour les instances de calcul, le stockage, les ressources réseau et les adresses IP que vous choisissez lors de la création d’un cluster Service Fabric. Des frais de déploiement sont facturés pour Service Fabric.
Groupes identiques de machines virtuelles
Dans cette architecture, les microservices sont déployés dans des nœuds qui sont des groupes de machines virtuelles identiques. Vous n'êtes facturé que pour les machines virtuelles Azure que vous déployez comme partie du cluster et pour les ressources d'infrastructure sous-jacentes consommées, comme le stockage et la mise en réseau. Il n'y a pas de frais supplémentaires pour le service des Virtual Machine Scale Sets elles-mêmes.
Gestion des API Azure
Azure Gestion des API est utilisé en tant que passerelle pour acheminer les demandes des clients vers vos services dans le cluster.
Il existe différentes options de tarification. L’option Consommation est facturée sur la base d’un paiement à l’utilisation et comprend un composant de passerelle. En fonction de votre charge de travail, choisissez une des options décrites dans Tarification du service Gestion des API.
Application Insights
Vous pouvez utiliser Application Insights pour la collecte des données de télémétrie pour tous les services et pour afficher les traces et les journaux des événements de manière structurée. Les tarifs d’Application Insights suivent un modèle de paiement à l’utilisation qui est basé sur le volume de données ingérées et les options de conservation des données. Pour plus d’informations, voirGérer l’utilisation et la tarification d’Application Insights.
Azure Monitor
Concernant Azure Monitor Log Analytics, vous êtes facturé pour l'ingestion et la conservation des données. Pour plus d’informations, consultez Tarification Azure Monitor.
Azure Key Vault
Vous utilisez Azure Key Vault pour stocker la clé d’instrumentation pour Application Insights en tant que secret. Azure propose Key Vault en deux niveaux de service. Si vous n’avez pas besoin de clés protégées par HSM, choisissez le niveau Standard. Pour plus d’informations sur les fonctionnalités de chaque niveau, consultez Tarification Key Vault.
Azure DevOps Services
Cette architecture de référence utilise Azure Pipelines pour le déploiement. Le service Azure Pipelines autorise une tâche gratuite hébergée par Microsoft, avec 1 800 minutes par mois pour l'intégration et la livraison continues (CI/CD), et d'un travail auto-hébergé avec un nombre de minutes mensuelles illimité. Les travaux supplémentaires ont des frais. Pour plus d'informations, consultez Tarification d'Azure DevOps Services.
Pour plus d’informations sur les DevOps dans une architecture de microservices, consultez CI/CD pour les microservices.
Pour découvrir comment déployer une application de conteneur avec CI/CD sur un cluster Service Fabric, voir ce tutoriel.
Déployer ce scénario
Pour déployer l'implémentation de référence de cette architecture, suivez la procédure décrite dans le référentiel GitHub.
Étapes suivantes
- Formation : Introduction à Azure Service Fabric
- Vue d’ensemble d’Azure Service Fabric
- Documentation Gestion des API
- Qu’est-ce qu’Azure Pipelines ?