Copiare e trasformare i dati in Microsoft Fabric Lakehouse usando Azure Data Factory o Azure Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Microsoft Fabric Lakehouse è una piattaforma di architettura dei dati per l'archiviazione, la gestione e l'analisi di dati strutturati e non strutturati in un'unica posizione. Per ottenere un accesso semplice ai dati in tutti i motori di calcolo in Microsoft Fabric, passare a Lakehouse e Tabelle Delta per altre informazioni. Per impostazione predefinita, i dati vengono scritti nella tabella Lakehouse in V-Order ed è possibile passare a Ottimizzazione tabella Delta Lake e V-Order per altre informazioni.
Questo articolo illustra come usare attività Copy per copiare dati da e in Microsoft Fabric Lakehouse e usare Flusso di dati per trasformare i dati in Microsoft Fabric Lakehouse. Per altre informazioni, vedere l'articolo introduttivo per Azure Data Factory o Azure Synapse Analytics.
Funzionalità supportate
Questo connettore Microsoft Fabric Lakehouse è supportato per le funzionalità seguenti:
| Funzionalità supportate | IR |
|---|---|
| Attività di copia (origine/sink) | (1) (2) |
| Flusso di dati di mapping (origine/sink) | (1) |
| Attività Lookup | (1) (2) |
| Attività GetMetadata | (1) (2) |
| Attività Delete | (1) (2) |
(1) Runtime di integrazione di Azure (2) Runtime di integrazione self-hosted
Operazioni preliminari
Per eseguire l'attività di copia con una pipeline, è possibile usare uno degli strumenti o SDK seguenti:
- Strumento Copia dati
- Il portale di Azure
- .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- Modello di Azure Resource Manager
Creare un servizio collegato Microsoft Fabric Lakehouse usando l'interfaccia utente
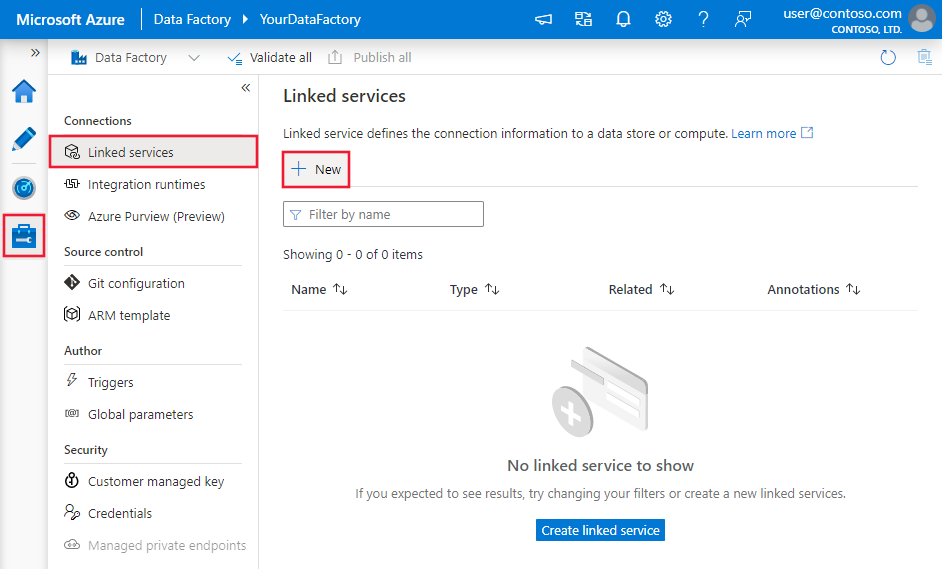
Usare la procedura seguente per creare un servizio collegato Microsoft Fabric Lakehouse nell'interfaccia utente di portale di Azure.
Passare alla scheda Gestisci nell'area di lavoro di Azure Data Factory o Synapse e selezionare Servizi collegati, quindi selezionare Nuovo:
Cercare Microsoft Fabric Lakehouse e selezionare il connettore.
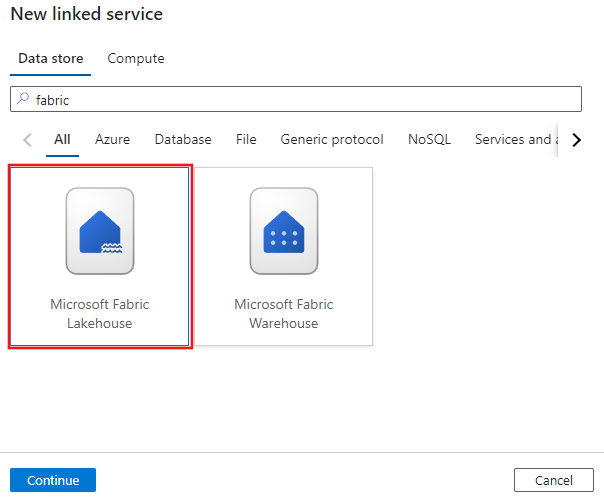
Configurare i dettagli del servizio, testare la connessione e creare il nuovo servizio collegato.
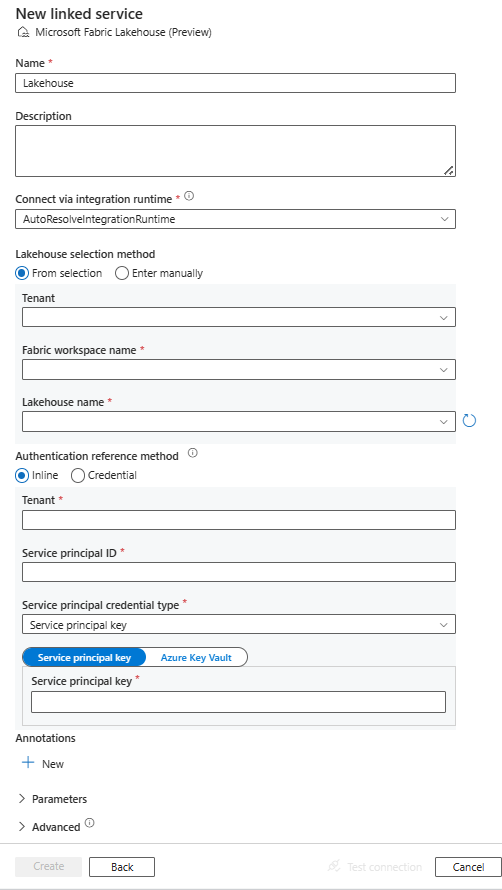
Dettagli di configurazione di Connessione or
Le sezioni seguenti forniscono informazioni dettagliate sulle proprietà usate per definire entità di Data Factory specifiche di Microsoft Fabric Lakehouse.
Proprietà del servizio collegato
Il connettore Microsoft Fabric Lakehouse supporta i tipi di autenticazione seguenti. Per informazioni dettagliate, vedere le sezioni corrispondenti:
Autenticazione dell'entità servizio
Per usare l'autenticazione basata sull'entità servizio, eseguire queste operazioni.
Registrare un'applicazione con Microsoft Identity Platform e aggiungere un segreto client. Successivamente, prendere nota di questi valori, che si usa per definire il servizio collegato:
- ID applicazione (client), ovvero l'ID entità servizio nel servizio collegato.
- Valore del segreto client, ovvero la chiave dell'entità servizio nel servizio collegato.
- ID tenant
Concedere all'entità servizio almeno il ruolo Collaboratore nell'area di lavoro di Microsoft Fabric. Seguire questa procedura:
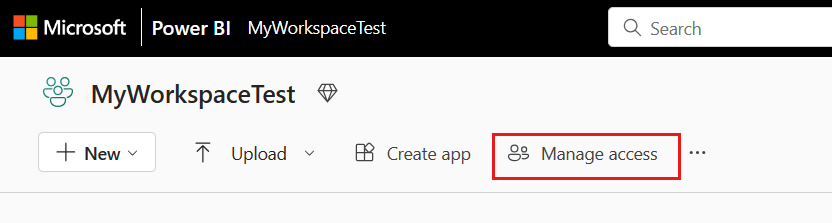
Passare all'area di lavoro di Microsoft Fabric, selezionare Gestisci accesso nella barra superiore. Selezionare quindi Aggiungi persone o gruppi.
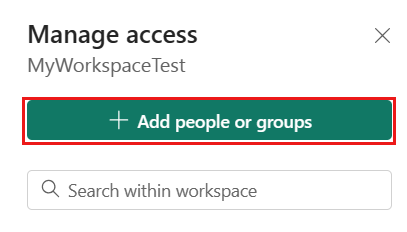
Nel riquadro Aggiungi persone immettere il nome dell'entità servizio e selezionare l'entità servizio dall'elenco a discesa.
Specificare il ruolo Collaboratore o superiore (Amministrazione, Membro) e quindi selezionare Aggiungi.
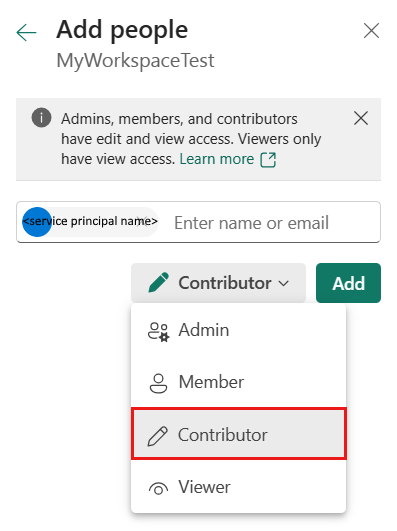
L'entità servizio viene visualizzata nel riquadro Gestisci accesso .
Queste sono le proprietà supportate dal servizio collegato:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type deve essere impostata su Lakehouse. | Sì |
| workspaceId | ID dell'area di lavoro di Microsoft Fabric. | Sì |
| artifactId | ID oggetto Microsoft Fabric Lakehouse. | Sì |
| tenant | Specificare le informazioni sul tenant (nome di dominio o ID tenant) in cui si trova l'applicazione. Recuperarlo passando il cursore del mouse sull'angolo superiore destro del portale di Azure. | Sì |
| servicePrincipalId | Specificare l'ID client dell'applicazione. | Sì |
| servicePrincipalCredentialType | Tipo di credenziale da usare per l'autenticazione dell'entità servizio. I valori consentiti sono ServicePrincipalKey e ServicePrincipalCert. | Sì |
| servicePrincipalCredential | Credenziali dell'entità servizio. Quando si usa ServicePrincipalKey come tipo di credenziale, specificare il valore del segreto client dell'applicazione. Contrassegnare questo campo come SecureString per archiviarlo in modo sicuro o fare riferimento a un segreto archiviato in Azure Key Vault. Quando si usa ServicePrincipalCert come credenziale, fare riferimento a un certificato in Azure Key Vault e assicurarsi che il tipo di contenuto del certificato sia PKCS #12. |
Sì |
| connectVia | Runtime di integrazione da usare per la connessione all'archivio dati. È possibile usare Azure Integration Runtime o un runtime di integrazione self-hosted, se l'archivio dati si trova in una rete privata. Se non specificato, viene usato il runtime di integrazione di Azure predefinito. | No |
Esempio: uso dell'autenticazione della chiave dell'entità servizio
È anche possibile archiviare la chiave dell'entità servizio in Azure Key Vault.
{
"name": "MicrosoftFabricLakehouseLinkedService",
"properties": {
"type": "Lakehouse",
"typeProperties": {
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Lakehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Proprietà del set di dati
Il connettore Microsoft Fabric Lakehouse supporta due tipi di set di dati, ovvero set di dati di Microsoft Fabric Lakehouse Files e set di dati di Microsoft Fabric Lakehouse Table. Per informazioni dettagliate, vedere le sezioni corrispondenti.
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione dei set di dati, vedere Set di dati.
Set di dati di Microsoft Fabric Lakehouse Files
Il connettore Microsoft Fabric Lakehouse supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
Nelle impostazioni del set di dati Microsoft Fabric Lakehouse Files basato sul formato sono supportate location le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà location type in nel set di dati deve essere impostata su LakehouseLocation. |
Sì |
| folderPath | Il percorso di una cartella. Se si intende usare un carattere jolly per filtrare le cartelle, ignorare questa impostazione e specificarla nelle impostazioni dell'origine dell'attività. | No |
| fileName | Nome del file nel percorso cartella specificato. Se si intende usare un carattere jolly per filtrare i file, ignorare questa impostazione e specificarla nelle impostazioni dell'origine dell'attività. | No |
Esempio:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "LakehouseLocation",
"fileName": "<file name>",
"folderPath": "<folder name>"
},
"columnDelimiter": ",",
"compressionCodec": "gzip",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ]
}
}
Set di dati tabella di Microsoft Fabric Lakehouse
Per il set di dati Tabella di Microsoft Fabric Lakehouse sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del set di dati deve essere impostata su LakehouseTable. | Sì |
| table | Nome della tabella. | Sì |
Esempio:
{
"name": "LakehouseTableDataset",
"properties": {
"type": "LakehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"table": "<table_name>"
},
"schema": [< physical schema, optional, retrievable during authoring >]
}
}
Proprietà dell'attività di copia
Le proprietà dell'attività di copia per il set di dati di Microsoft Fabric Lakehouse Files e il set di dati microsoft Fabric Lakehouse Table sono diversi. Per informazioni dettagliate, vedere le sezioni corrispondenti.
- Microsoft Fabric LakeHouse Files in attività Copy
- Tabella di Microsoft Fabric Lakehouse in attività Copy
Per un elenco completo delle sezioni e delle proprietà disponibili per la definizione delle attività, vedere Configurazioni dell'attività di copia e Pipeline e attività.
Microsoft Fabric LakeHouse Files in attività Copy
Per usare il tipo di set di dati di Microsoft Fabric Lakehouse Files come origine o sink in attività Copy, vedere le sezioni seguenti per le configurazioni dettagliate.
Microsoft Fabric Lakehouse Files come tipo di origine
Il connettore Microsoft Fabric Lakehouse supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
Sono disponibili diverse opzioni per copiare dati da Microsoft Fabric Lakehouse usando il set di dati Microsoft Fabric Lakehouse Files:
- Copia dal percorso specificato nel set di dati.
- Filtro con caratteri jolly per il percorso della cartella o il nome del file, vedere
wildcardFolderPathewildcardFileName. - Copia dei file definiti in un file di testo specificato come set di file, vedere
fileListPath.
Le proprietà seguenti si trovano storeSettings nelle impostazioni nell'origine di copia basata sul formato quando si usa il set di dati Microsoft Fabric Lakehouse Files:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type in storeSettings deve essere impostata su LakehouseRead Impostazioni. |
Sì |
| Individuare i file da copiare: | ||
| OPZIONE 1: percorso statico |
Copiare dal percorso di cartella/file specificato nel set di dati. Se si vogliono copiare tutti i file da una cartella, specificare anche wildcardFileName come *. |
|
| OPZIONE 2: carattere jolly - wildcardFolderPath |
Percorso della cartella con caratteri jolly per filtrare le cartelle di origine. I caratteri jolly consentiti sono: * (corrisponde a zero o più caratteri) e ? (corrisponde a zero caratteri o a un carattere singolo). Usare ^ come carattere di escape se il nome effettivo della cartella include caratteri jolly o questo carattere di escape. Vedere altri esempi in Esempi di filtro file e cartelle. |
No |
| OPZIONE 2: carattere jolly - wildcardFileName |
Nome file con caratteri jolly nel percorso folderPath/wildcardFolderPath specificato per filtrare i file di origine. I caratteri jolly consentiti sono: * (corrispondenza di zero o più caratteri) e ? (corrispondenza di zero caratteri o di un carattere singolo). Usare ^ per il carattere escape se il nome effettivo del file include caratteri jolly o escape. Vedere altri esempi in Esempi di filtro file e cartelle. |
Sì |
| OPZIONE 3: un elenco di file - fileListPath |
Indica di copiare un determinato set di file. Puntare a un file di testo che include un elenco di file da copiare, un file per riga, ovvero il percorso relativo al percorso configurato nel set di dati. Quando si usa questa opzione, non specificare il nome file nel set di dati. Per altri esempi, vedere Esempi di elenco di file. |
No |
| Impostazioni aggiuntive: | ||
| recursive | Indica se i dati vengono letti in modo ricorsivo dalle cartelle secondarie o solo dalla cartella specificata. Quando la proprietà recursive è impostata su true e il sink è un archivio basato su file, una cartella o una sottocartella vuota non viene copiata o creata nel sink. I valori consentiti sono true (predefinito) e false. Questa proprietà non è applicabile quando si configura fileListPath. |
No |
| deleteFilesAfterCompletion | Indica se i file binari verranno eliminati dall'archivio di origine dopo il corretto spostamento nell'archivio di destinazione. L'eliminazione del file è per file, quindi quando l'attività di copia non riesce, vengono visualizzati alcuni file già copiati nella destinazione ed eliminati dall'origine, mentre altri rimangono nell'archivio di origine. Questa proprietà è valida solo nello scenario di copia dei file binari. Valore predefinito: false. |
No |
| modifiedDatetimeStart | Filtro dei file in base all'attributo: Ultima modifica. I file verranno selezionati se l'ora dell'ultima modifica è maggiore o uguale a modifiedDatetimeStart e minore di modifiedDatetimeEnd. L'ora viene applicata con il fuso orario UTC e il formato "2018-12-01T05:00:00Z". Le proprietà possono essere NULL, a indicare che al set di dati non viene applicato alcun filtro di attributo di file. Quando modifiedDatetimeStart ha un valore datetime ma modifiedDatetimeEnd è NULL, vengono selezionati i file il cui ultimo attributo modificato è maggiore o uguale al valore datetime. Quando modifiedDatetimeEnd ha un valore datetime ma modifiedDatetimeStart è NULL vengono selezionati i file il cui ultimo attributo modificato è minore del valore datetime.Questa proprietà non è applicabile quando si configura fileListPath. |
No |
| modifiedDatetimeEnd | Come sopra. | No |
| enablePartitionDiscovery | Per i file partizionati, specificare se analizzare le partizioni dal percorso del file e aggiungerle come altre colonne di origine. I valori consentiti sono false (impostazione predefinita) e true. |
No |
| partitionRootPath | Quando l'individuazione delle partizioni è abilitata, specificare il percorso radice assoluto per leggere le cartelle partizionate come colonne di dati. Se non è specificato, per impostazione predefinita, - Quando si usa il percorso del file nel set di dati o nell'elenco di file nell'origine, il percorso radice della partizione è il percorso configurato nel set di dati. - Quando si usa il filtro delle cartelle con caratteri jolly, il percorso radice della partizione è il sottopercorso prima del primo carattere jolly. Si supponga, ad esempio, di configurare il percorso nel set di dati come "root/folder/year=2020/month=08/day=27": - Se si specifica il percorso radice della partizione come "root/folder/year=2020", l'attività di copia genera altre due colonne month e day con il valore "08" e "27" rispettivamente, oltre alle colonne all'interno dei file.- Se il percorso radice della partizione non è specificato, non viene generata alcuna colonna aggiuntiva. |
No |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
Esempio:
"activities": [
{
"name": "CopyFromLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "LakehouseReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Files come tipo di sink
Il connettore Microsoft Fabric Lakehouse supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
Le proprietà seguenti si trovano nelle storeSettings impostazioni nel sink di copia basato sul formato quando si usa il set di dati Microsoft Fabric Lakehouse Files:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type in storeSettings deve essere impostata su LakehouseWrite Impostazioni. |
Sì |
| copyBehavior | Definisce il comportamento di copia quando l'origine è costituita da file di un archivio dati basato su file. I valori consentiti sono i seguenti: - PreserveHierarchy (predefinito): mantiene la gerarchia dei file nella cartella di destinazione. Il percorso relativo del file di origine nella cartella di origine è identico al percorso relativo del file di destinazione nella cartella di destinazione. - FlattenHierarchy: tutti i file della cartella di origine si trovano nel primo livello della cartella di destinazione. I nomi dei file di destinazione vengono generati automaticamente. - MergeFiles: unisce tutti i file della cartella di origine in un solo file. Se si specifica il nome di file, il nome del file unito sarà il nome specificato. In caso contrario, verrà usato un nome di file generato automaticamente. |
No |
| blockSizeInMB | Specificare le dimensioni del blocco in MB usate per scrivere dati in Microsoft Fabric Lakehouse. Altre informazioni sui BLOB in blocchi. Il valore consentito è compreso tra 4 MB e 100 MB. Per impostazione predefinita, Azure Data Factory determina automaticamente le dimensioni del blocco in base al tipo e ai dati dell'archivio di origine. Per la copia nonbinary in Microsoft Fabric Lakehouse, le dimensioni predefinite del blocco sono pari a 100 MB in modo da adattarsi al massimo a dati di circa 4,75 TB. Potrebbe non essere ottimale quando i dati non sono di grandi dimensioni, soprattutto quando si usa il runtime di integrazione self-hosted con una rete scarsa che causa un timeout dell'operazione o un problema di prestazioni. È possibile specificare in modo esplicito una dimensione del blocco, assicurandosi che blockSizeInMB*50000 sia sufficientemente grande da archiviare i dati. In caso contrario, l'esecuzione dell'attività di copia non riesce. |
No |
| maxConcurrentConnections | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | No |
| metadata | Impostare metadati personalizzati quando si esegue la copia nel sink. Ogni oggetto sotto la metadata matrice rappresenta una colonna aggiuntiva. name Definisce il nome della chiave di metadati e indica value il valore dei dati di tale chiave. Se si usa la funzionalità di conservazione degli attributi, i metadati specificati verranno uniti/sovrascritti con i metadati del file di origine.I valori dei dati consentiti sono: - $$LASTMODIFIED: una variabile riservata indica di archiviare l'ora dell'ultima modifica dei file di origine. Si applica all'origine basata su file solo con formato binario.-Espressione - Valore statico |
No |
Esempio:
"activities": [
{
"name": "CopyToLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "LakehouseWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
}
]
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
}
}
}
]
Esempi di filtro file e cartelle
Questa sezione descrive il comportamento risultante del percorso cartella e del nome del file con i filtri con caratteri jolly.
| folderPath | fileName | recursive | Struttura delle cartelle di origine e risultato del filtro (i file in grassetto sono stati recuperati) |
|---|---|---|---|
Folder* |
(vuoto, usare il valore predefinito) | false | CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
Folder* |
(vuoto, usare il valore predefinito) | true | CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
Folder* |
*.csv |
false | CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
Folder* |
*.csv |
true | CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv AltraCartellaB File6.csv |
Esempi di elenco di file
Questa sezione descrive il comportamento risultante dall'uso del percorso di elenco file nell'origine dell'attività di copia.
Si supponga di disporre della struttura di cartelle di origine seguente e di voler copiare i file in grassetto:
| Esempio di struttura di origine | Contenuto in FileListToCopy.txt | Configurazione di Azure Data Factory |
|---|---|---|
| filesystem CartellaA File1.csv File2.json Sottocartella1 File3.csv File4.json File5.csv Metadati UFX FileListToCopy.txt |
File1.csv Sottocartella1/File3.csv Sottocartella1/File5.csv |
Nel set di dati: - Percorso cartella: FolderANell'origine dell'attività Copy: - Percorso elenco file: Metadata/FileListToCopy.txt Il percorso dell'elenco di file fa riferimento a un file di testo nello stesso archivio dati che include un elenco di file da copiare, un file per riga con il percorso relativo del percorso configurato nel set di dati. |
Alcuni esempi dei valori recursive e copyBehavior
Questa sezione descrive il comportamento derivante dall'operazione di copia per diverse combinazioni di valori ricorsivi e copyBehavior.
| recursive | copyBehavior | Struttura della cartella di origine | Destinazione risultante |
|---|---|---|---|
| true | preserveHierarchy | Cartella1 File1 File2 Sottocartella1 File3 File4 File5 |
La Cartella1 di destinazione viene creata con la stessa struttura dell'origine: Cartella1 File1 File2 Sottocartella1 File3 File4 File5 |
| true | flattenHierarchy | Cartella1 File1 File2 Sottocartella1 File3 File4 File5 |
La cartella 1 di destinazione viene creata con la struttura seguente: Cartella1 Nome generato automaticamente per File1 Nome generato automaticamente per File2 Nome generato automaticamente per File3 Nome generato automaticamente per File4 Nome generato automaticamente per File5 |
| true | mergeFiles | Cartella1 File1 File2 Sottocartella1 File3 File4 File5 |
La cartella 1 di destinazione viene creata con la struttura seguente: Cartella1 Il contenuto di File1 + File2 + File3 + File4 + File 5 viene unito in un file con nome generato automaticamente. |
| false | preserveHierarchy | Cartella1 File1 File2 Sottocartella1 File3 File4 File5 |
La cartella 1 di destinazione viene creata con la struttura seguente: Cartella1 File1 File2 La sottocartella1 con File3, File4 e File5 non viene considerata. |
| false | flattenHierarchy | Cartella1 File1 File2 Sottocartella1 File3 File4 File5 |
La cartella 1 di destinazione viene creata con la struttura seguente: Cartella1 Nome generato automaticamente per File1 Nome generato automaticamente per File2 La sottocartella1 con File3, File4 e File5 non viene considerata. |
| false | mergeFiles | Cartella1 File1 File2 Sottocartella1 File3 File4 File5 |
La cartella 1 di destinazione viene creata con la struttura seguente: Cartella1 Il contenuto di File1 + File2 viene unito in un file con un nome di file generato automaticamente. Nome generato automaticamente per File1 La sottocartella1 con File3, File4 e File5 non viene considerata. |
Tabella di Microsoft Fabric Lakehouse in attività Copy
Per usare il set di dati di Tabelle di Microsoft Fabric Lakehouse come set di dati di origine o sink in attività Copy, vedere le sezioni seguenti per le configurazioni dettagliate.
Microsoft Fabric Lakehouse Table come tipo di origine
Per copiare dati da Microsoft Fabric Lakehouse usando il set di dati Microsoft Fabric Lakehouse Table, impostare la proprietà type nell'origine attività Copy su LakehouseTableSource. Nella sezione attività Copy source sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su LakehouseTableSource. | Sì |
| timestampAsOf | Timestamp per eseguire una query su uno snapshot precedente. | No |
| versionAsOf | Versione per eseguire una query su uno snapshot precedente. | No |
Esempio:
"activities":[
{
"name": "CopyFromLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "LakehouseTableSource",
"timestampAsOf": "2023-09-23T00:00:00.000Z",
"versionAsOf": 2
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Table come tipo di sink
Per copiare dati in Microsoft Fabric Lakehouse usando il set di dati Microsoft Fabric Lakehouse Table, impostare la proprietà type nel sink dell'attività di copia su LakehouseTableSink. Nella sezione sink di attività Copy sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type dell'origine dell'attività di copia deve essere impostata su LakehouseTableSink. | Sì |
Nota
I dati sono scritti nella tabella Lakehouse nell'ordine V per impostazione predefinita. Per altre informazioni, vedere Ottimizzazione tabella Delta Lake e V-Order.
Esempio:
"activities":[
{
"name": "CopyToLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption ": "Append"
}
}
}
]
Proprietà del flusso di dati per mapping
Quando si trasformano i dati nel flusso di dati di mapping, è possibile leggere e scrivere in file o tabelle in Microsoft Fabric Lakehouse. Per informazioni dettagliate, vedere le sezioni corrispondenti.
- File di Microsoft Fabric Lakehouse nel flusso di dati di mapping
- Tabella di Microsoft Fabric Lakehouse nel flusso di dati di mapping
Per altre informazioni, vedere la trasformazione origine e la trasformazione sink nei flussi di dati per mapping.
File di Microsoft Fabric Lakehouse nel flusso di dati di mapping
Per usare il set di dati di Microsoft Fabric Lakehouse Files come set di dati di origine o sink nel flusso di dati di mapping, vedere le sezioni seguenti per le configurazioni dettagliate.
Microsoft Fabric Lakehouse Files come tipo di origine o sink
Il connettore Microsoft Fabric Lakehouse supporta i formati di file seguenti. Per impostazioni basate sui formati, fare riferimento ai singoli articoli.
Per usare il connettore basato su file fabric Lakehouse nel tipo di set di dati inline, è necessario scegliere il tipo di set di dati Inline corretto per i dati. È possibile usare DelimitedText, Avro, JSON, ORC o Parquet a seconda del formato di dati.
Tabella di Microsoft Fabric Lakehouse nel flusso di dati di mapping
Per usare il set di dati di Tabelle di Microsoft Fabric Lakehouse come set di dati di origine o sink nel flusso di dati di mapping, vedere le sezioni seguenti per le configurazioni dettagliate.
Microsoft Fabric Lakehouse Table come tipo di origine
Non esistono proprietà configurabili nelle opzioni di origine.
Nota
Il supporto CDC per l'origine tabella Lakehouse non è attualmente disponibile.
Microsoft Fabric Lakehouse Table come tipo di sink
Nella sezione Sink Mapping Flusso di dati s sono supportate le proprietà seguenti:
| Nome | Descrizione | Richiesto | Valori consentiti | Proprietà script flusso di dati |
|---|---|---|---|---|
| Metodo di aggiornamento | Quando si seleziona "Consenti inserimento" da solo o quando si scrive in una nuova tabella differenziale, la destinazione riceve tutte le righe in ingresso indipendentemente dal set di criteri riga. Se i dati contengono righe di altri criteri di riga, è necessario escluderli usando una trasformazione filtro precedente. Quando vengono selezionati tutti i metodi Update, viene eseguita un'operazione Merge, in cui le righe vengono inserite/eliminate/aggiornate in base ai criteri di riga impostati utilizzando una trasformazione Alter Row precedente. |
yes | true oppure false |
Inseribile deletable aggiornabile Aggiornabile |
| Scrittura ottimizzata | Ottenere una velocità effettiva più elevata per l'operazione di scrittura tramite l'ottimizzazione dello shuffle interno negli executor Spark. Di conseguenza, è possibile notare un minor numero di partizioni e file con dimensioni maggiori | no | true oppure false |
optimizedWrite: true |
| Compatta automatica | Al termine di un'operazione di scrittura, Spark eseguirà automaticamente il OPTIMIZE comando per riorganizzare i dati, ottenendo così più partizioni, se necessario, per una migliore lettura delle prestazioni in futuro |
no | true oppure false |
autoCompact: true |
| Merge Schema | L'opzione Merge Schema consente l'evoluzione dello schema, ovvero tutte le colonne presenti nel flusso in ingresso corrente, ma non nella tabella Delta di destinazione vengono aggiunte automaticamente al relativo schema. Questa opzione è supportata in tutti i metodi di aggiornamento. | no | true oppure false |
mergeSchema: true |
Esempio: sink di tabella di Microsoft Fabric Lakehouse
sink(allowSchemaDrift: true,
validateSchema: false,
input(
CustomerID as string,
NameStyle as string,
Title as string,
FirstName as string,
MiddleName as string,
LastName as string,
Suffix as string,
CompanyName as string,
SalesPerson as string,
EmailAddress as string,
Phone as string,
PasswordHash as string,
PasswordSalt as string,
rowguid as string,
ModifiedDate as string
),
deletable:false,
insertable:true,
updateable:false,
upsertable:false,
optimizedWrite: true,
mergeSchema: true,
autoCompact: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CustomerTable
Per il connettore basato su tabelle di Fabric Lakehouse nel tipo di set di dati inline, è sufficiente usare Delta come tipo di set di dati. In questo modo sarà possibile leggere e scrivere dati dalle tabelle Fabric Lakehouse.
Proprietà dell'attività Lookup
Per altre informazioni sulle proprietà, vedere Attività Lookup.
Proprietà dell'attività GetMetadata
Per altre informazioni sulle proprietà, vedere Attività GetMetadata
Proprietà dell'attività Delete
Per altre informazioni sulle proprietà, vedere Attività Delete
Contenuto correlato
Per un elenco degli archivi dati supportati come origini e sink dall'attività di copia, vedere Archivi dati supportati.