Usare Azure Data Factory per eseguire la migrazione dei dati da un archivio dati Amazon S3 ad Archiviazione di Azure
SI APPLICA A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Azure Data Factory offre un meccanismo efficiente, affidabile ed economico per eseguire la migrazione dei dati su larga scala da Amazon S3 ad Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2. In questo articolo vengono fornite le seguenti informazioni per i data engineer e gli sviluppatori:
- Prestazione
- Resilienza della copia
- Sicurezza di rete
- Architettura di alto livello della soluzione
- Procedure consigliate dell'implementazione
Prestazioni
ADF offre un'architettura serverless che consente il parallelismo a diversi livelli, che consente agli sviluppatori di creare pipeline per usare completamente la larghezza di banda di rete e le operazioni di I/O al secondo di archiviazione e la larghezza di banda per ottimizzare la velocità effettiva di spostamento dei dati per l'ambiente.
I clienti hanno completato la migrazione di petabyte di dati costituiti da centinaia di milioni di file da Amazon S3 ad Archiviazione BLOB di Azure, con una velocità effettiva prolungata di 2 GBps e superiore.
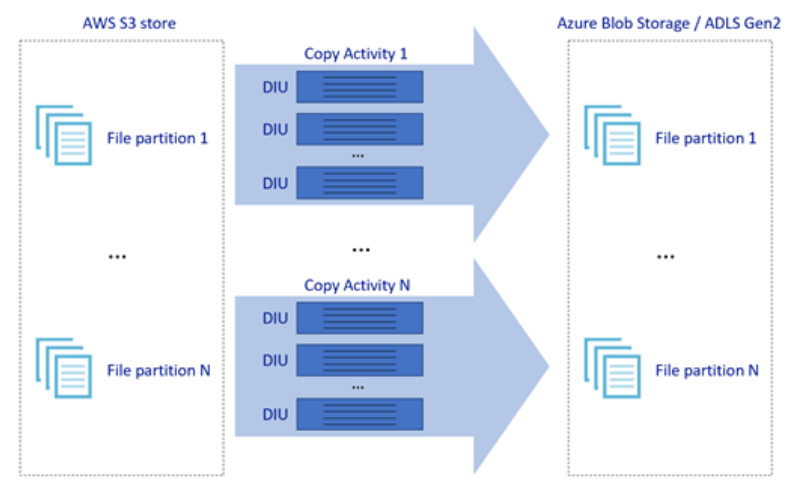
L'immagine precedente illustra come è possibile ottenere velocità di spostamento di dati eccezionali mediante diversi livelli di parallelismo:
- Una singola attività di copia può sfruttare i vantaggi delle risorse di calcolo scalabili: quando si usa Azure Integration Runtime, è possibile specificare fino a 256 UNITÀ di distribuzione per ogni attività di copia in modo serverless. Quando si usa il runtime di integrazione self-hosted, è possibile aumentare manualmente il numero di istanze del computer o aumentare il numero di istanze in più computer (fino a quattro nodi) e una singola attività di copia partizionerà il set di file in tutti i nodi.
- Una singola attività di copia legge da e scrive nell'archivio dati usando più thread.
- Il flusso di controllo ADF può avviare più attività di copia in parallelo, ad esempio usando il ciclo For Each.
Resilienza
All'interno di una singola esecuzione dell'attività di copia, ADF include un meccanismo di ripetizione dei tentativi incorporato che consente di gestire un determinato livello di errori temporanei negli archivi dati o nella rete sottostante.
Quando si esegue la copia binaria da S3 a BLOB e da S3 ad ADLS Gen2, ADF esegue automaticamente il checkpoint. Se l'esecuzione di un'attività di copia ha avuto esito negativo o ha raggiunto il timeout, al tentativo successivo la copia riprende dall'ultimo punto di errore anziché ripartire dall'inizio.
Sicurezza di rete
Per impostazione predefinita, ADF trasferisce i dati da Amazon S3 ad Archiviazione BLOB di Azure o Azure Data Lake Storage Gen2 usando la connessione crittografata su protocollo HTTPS. Il protocollo HTTPS offre la crittografia dei dati in transito e impedisce l'intercettazione e gli attacchi man-in-the-middle.
In alternativa, se non si vuole trasferire i dati tramite Internet pubblico, è possibile ottenere una maggiore sicurezza trasferendo i dati tramite un collegamento di peering privato tra AWS Direct Connessione e Azure ExpressRoute. Fare riferimento all'architettura della soluzione nella sezione successiva su come ottenere questo risultato.
Architettura della soluzione
Migrazione di dati su Internet pubblico:
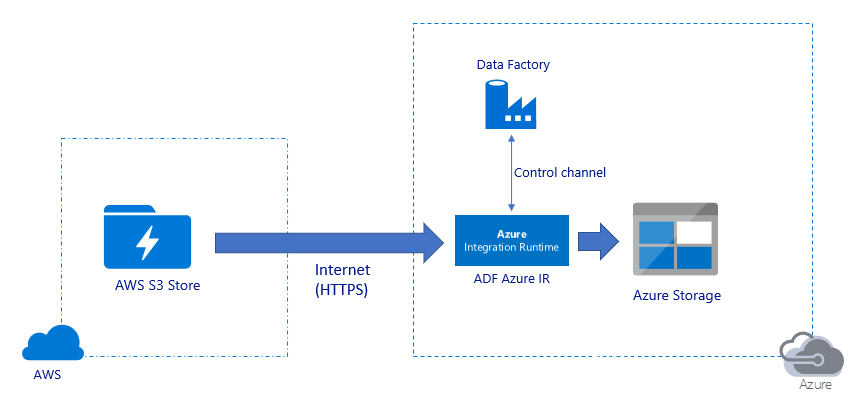
- In questa architettura i dati vengono trasferiti in modo sicuro tramite HTTPS su rete Internet pubblica.
- Sia l'origine Amazon S3 che il Archiviazione BLOB di Azure di destinazione o Azure Data Lake Archiviazione Gen2 sono configurati per consentire il traffico da tutti gli indirizzi IP di rete. Fare riferimento alla seconda architettura a cui si fa riferimento più avanti in questa pagina per informazioni su come limitare l'accesso alla rete a un intervallo IP specifico.
- È possibile aumentare facilmente la quantità di potenza in modalità serverless per usare completamente la larghezza di banda di rete e di archiviazione, in modo da ottenere la velocità effettiva migliore per l'ambiente.
- Con questa architettura è possibile ottenere sia la migrazione dello snapshot iniziale sia la migrazione dei dati Delta.
Eseguire la migrazione di dati mediante un collegamento privato:
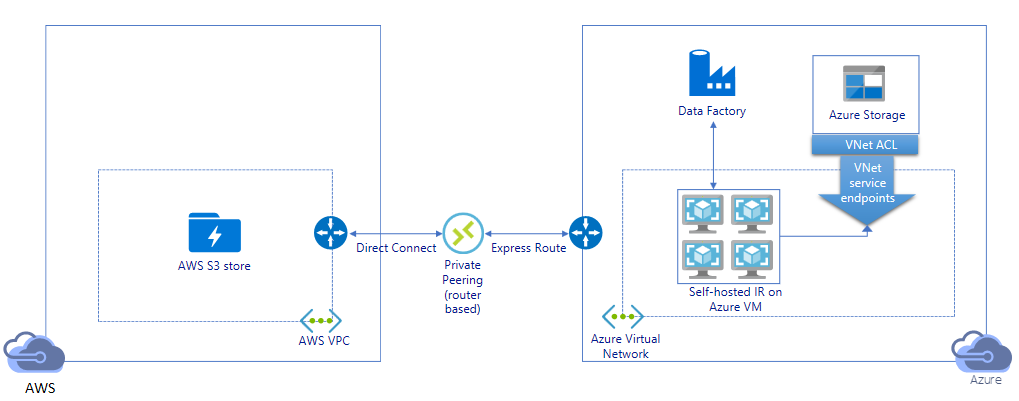
- In questa architettura, la migrazione dei dati viene eseguita mediante un collegamento peering privato tra AWS Direct Connect e Azure Express Route in modo che i dati non attraversino mai la rete Internet pubblica. Richiede l'uso di VPC AWS e della rete virtuale di Azure.
- Per ottenere questa architettura è necessario installare il runtime di integrazione self-hosted di ADF su una macchina virtuale Windows nella rete virtuale di Azure. È possibile aumentare manualmente le macchine virtuali del runtime di integrazione self-hosted o aumentare il numero di istanze in più macchine virtuali (fino a quattro nodi) per usare completamente le operazioni di I/O al secondo di rete e archiviazione/larghezza di banda.
- Con questa architettura è possibile ottenere sia la migrazione dei dati dello snapshot iniziale sia la migrazione dei dati differenziali.
Procedure consigliate dell'implementazione
Gestione dell'autenticazione e delle credenziali
- Per eseguire l'autenticazione per l'account Amazon S3, è necessario usare la chiave di accesso per l'account IAM.
- Per la connessione ad Archiviazione BLOB di Azure sono supportati più tipi di autenticazione. L'uso delle identità gestite per le risorse di Azure è altamente consigliato: basato su un'identificazione automatica di Azure Data Factory gestita in Microsoft Entra ID, consente di configurare le pipeline senza fornire credenziali nella definizione del servizio collegato. In alternativa, è possibile eseguire l'autenticazione in Archiviazione BLOB di Azure usando l'entità servizio, la firma di accesso condiviso o la chiave dell'account di archiviazione.
- Anche per la connessione ad Azure Data Lake Storage Gen2 sono supportati più tipi di autenticazione. È consigliabile usare identità gestite per le risorse di Azure, anche se è possibile usare entità servizio o chiave dell'account di archiviazione.
- Quando non si usano identità gestite per le risorse di Azure, è consigliabile archiviare le credenziali in Azure Key Vault per semplificare la gestione centralizzata e la rotazione delle chiavi senza modificare i servizi collegati di Azure Data Factory. Questa è anche una delle procedure consigliate per CI/CD.
Migrazione iniziale dei dati dello snapshot
La partizione dei dati è consigliata soprattutto quando si esegue la migrazione di più di 100 TB di dati. Per partizionare i dati, usare l'impostazione "prefisso" per filtrare le cartelle e i file in Amazon S3 in base al nome e quindi ogni processo di copia di Azure Data Factory può copiare una partizione alla volta. È possibile eseguire più processi di copia ADF simultaneamente per una migliore velocità effettiva.
Se uno dei processi di copia ha esito negativo a causa di un problema temporaneo di rete o archivio dati, è possibile rieseguire il processo di copia non riuscito per ricaricare nuovamente la partizione specifica da AWS S3. Tutti gli altri processi di copia che caricano altre partizioni non saranno interessati.
Migrazione dei dati Delta
Il modo più efficiente per identificare i file nuovi o modificati da AWS S3 consiste nell'usare una convenzione di denominazione partizionata in tempo, quando i dati in AWS S3 sono stati partizionati con informazioni sulla sezione temporale nel nome del file o della cartella (ad esempio, /aaaa/mm/dd/file.csv), la pipeline può identificare facilmente quali file/cartelle copiare in modo incrementale.
In alternativa, se i dati in AWS S3 non sono partizionati in tempo, Azure Data Factory può identificare i file nuovi o modificati in base a LastModifiedDate. La modalità di funzionamento è che ADF analizzerà tutti i file di AWS S3 e copierà solo il file nuovo e aggiornato il cui ultimo timestamp modificato è maggiore di un determinato valore. Se si dispone di un numero elevato di file in S3, l'analisi iniziale dei file potrebbe richiedere molto tempo indipendentemente dal numero di file che corrispondono alla condizione di filtro. In questo caso si consiglia di partizionare prima i dati, usando la stessa impostazione "prefisso" per la migrazione iniziale degli snapshot, in modo che l'analisi dei file possa verificarsi in parallelo.
Per gli scenari che richiedono il runtime di integrazione self-hosted in una macchina virtuale di Azure
Indipendentemente dal fatto che si stia eseguendo la migrazione dei dati tramite collegamento privato o si voglia consentire un intervallo IP specifico nel firewall Amazon S3, è necessario installare il runtime di integrazione self-hosted nella macchina virtuale Windows di Azure.
- La configurazione consigliata con cui iniziare per ogni macchina virtuale di Azure è Standard_D32s_v3 con 32 vCPU e 128 GB di memoria. È possibile monitorare l'uso della CPU e della memoria della VM IR durante la migrazione dei dati per vedere se è necessario aumentare le prestazioni della macchina virtuale per ottenere prestazioni migliori o ridurre le prestazioni della VM per ridurre i costi.
- È anche possibile aumentare il numero di istanze associando fino a quattro nodi vm a un singolo runtime di integrazione self-hosted. Un singolo processo di copia in esecuzione in un runtime di integrazione self-hosted partizionerà automaticamente il set di file e userà tutti i nodi della macchina virtuale per copiare i file in parallelo. Per la disponibilità elevata, è consigliabile iniziare con due nodi della macchina virtuale per evitare un singolo punto di errore durante la migrazione dei dati.
Limitazione della frequenza
Come procedura consigliata eseguire un PoC di prestazioni con un set di dati di esempio rappresentativo, in modo da poter determinare la dimensione appropriata della partizione.
Iniziare con una singola partizione e una singola attività di copia con l'impostazione DIU predefinita. Aumentare gradualmente l'impostazione DIU fino a raggiungere il limite di larghezza di banda della rete o il limite di operazioni di I/O al secondo/larghezza di banda degli archivi dati oppure fino a raggiungere il numero massimo di 256 DIU consentito per una singola attività di copia.
Successivamente, aumentare gradualmente il numero di attività di copia simultanee fino a raggiungere i limiti dell'ambiente.
Quando si verificano errori di limitazione delle richieste segnalati dall'attività di copia ADF, ridurre l'impostazione della concorrenza o DIU in ADF oppure provare ad aumentare i limiti di larghezza di banda/IOPS della rete e degli archivi dati.
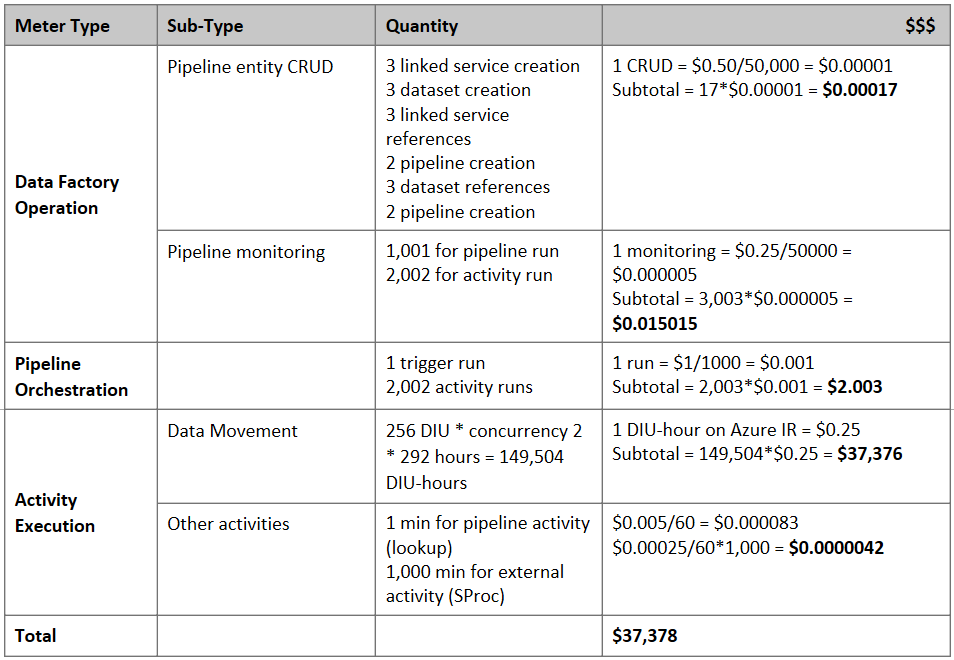
Stima del prezzo
Nota
Si tratta di un esempio di prezzo ipotetico. I prezzi effettivi variano in base alla velocità effettiva dell'ambiente.
Si consideri la pipeline seguente costruita per la migrazione dei dati da S3 ad Archiviazione BLOB di Azure:
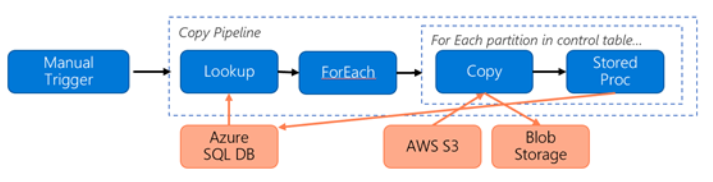
Si supponga quanto segue:
- Volume di dati totale pari a 2 PB
- Migrazione dei dati tramite HTTPS usando la prima architettura della soluzione
- 2 PB è diviso in 1 KB partizioni e ogni copia sposta una partizione
- Ogni copia è configurata con DIU = 256 e ottiene una velocità effettiva di 1 GBps
- La concorrenza ForEach è impostata su 2 e la velocità effettiva aggregata è di 2 GBps
- In totale, sono necessarie 292 ore per completare la migrazione
Ecco il prezzo stimato in base ai presupposti precedenti:
Altri riferimenti
- Copiare dati da Amazon Simple Storage Service usando Azure Data Factory
- Connettore di Archiviazione BLOB di Azure
- Connettore di Azure Data Lake Storage Gen2
- Guida alle prestazioni delle attività di copia e all'ottimizzazione
- Creare e configurare un runtime di integrazione self-hosted
- Disponibilità elevata e scalabilità del runtime di integrazione self-hosted
- Considerazioni relative alla sicurezza per lo spostamento dei dati
- Archiviare le credenziali in Azure Key Vault
- Copiare file in modo incrementale in base al nome del file partizionato in base all'ora
- Copiare i file nuovi e modificati in base a LastModifiedDate
- Pagina dei prezzi di ADF
Modello
Ecco il modello da cui iniziare per eseguire la migrazione di petabyte di dati costituiti da centinaia di milioni di file da Amazon S3 ad Azure Data Lake Archiviazione Gen2.