チュートリアル:Azure HDInsight でエンドツーエンドのデータ パイプラインを作成して売上の分析情報を導き出す
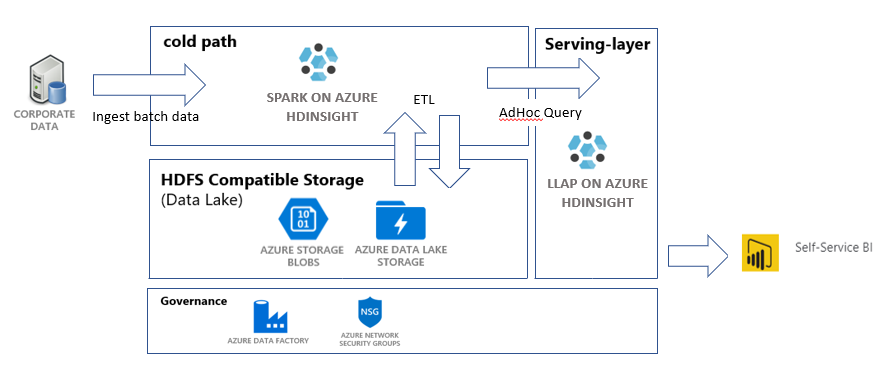
このチュートリアルでは、抽出、変換、読み込み (ETL) 操作を実行するエンドツーエンドのデータ パイプラインを作成します。 このパイプラインでは、データに対してクエリを実行して操作するために、Azure HDInsight 上で稼働している Apache Spark および Apache Hive クラスターを使用します。 また、データ ストレージ用に Data Lake Storage Gen2、視覚化用に Power BI といったテクノロジを使用します。
このデータ パイプラインでは、さまざまな店舗のデータを結合し、不要なデータがあれば削除して新しいデータを追加し、これをすべてストレージに再度読み込んで、ビジネスの分析情報を視覚化します。 ETL パイプラインの詳細については、「大規模な抽出、変換、および読み込み (ETL)」を参照してください。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
Azure CLI - バージョン 2.2.0 以上。 「Azure CLI のインストール」を参照してください。
jq。コマンド ライン JSON プロセッサです。 「https://stedolan.github.io/jq/」を参照してください。
Azure の組み込みロールである所有者のメンバー。
PowerShell を使用して Data Factory パイプラインをトリガーしている場合は、AZ モジュールが必要になります。
Power BI Desktop。このチュートリアルの最後に、ビジネスの分析情報を視覚化する目的で使用します。
リソースを作成する
スクリプトとデータを含むリポジトリを複製する
Azure サブスクリプションにログインします。 Azure Cloud Shell を使用する予定の場合は、コード ブロックの右上隅で [使ってみる] を選択します。 それ以外の場合は、次のコマンドを入力します。
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Azure の所有者ロールのメンバーであることを確認します。
user@contoso.comを、ご使用のアカウントに置き換え、次のコマンドを入力します。az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"レコードが返されない方は、メンバーではないため、このチュートリアルの手順を実行することはできません。
HDInsight sales insights ETL のリポジトリからこのチュートリアル用のデータとスクリプトをダウンロードします。 次のコマンドを入力します。
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlsalesdata scripts templatesが作成されたことを確認します。 この確認には次のコマンドを使用します。ls
パイプラインに必要な Azure リソースをデプロイする
次のコマンドを入力して、すべてのスクリプトの実行アクセス許可を追加します。
chmod +x scripts/*.shリソース グループの変数を設定します。
RESOURCE_GROUP_NAMEを既存のリソース グループまたは新しいリソース グループの名前に置き換えてから、コマンドを入力します。RESOURCE_GROUP="RESOURCE_GROUP_NAME"スクリプトを実行します。
LOCATIONを適切な値に置き換え、次のコマンドを入力します。./scripts/resources.sh $RESOURCE_GROUP LOCATION指定するリージョンがわからない場合は、az account list-locations コマンドで、サブスクリプションに対してサポートされているリージョンの一覧を取得できます。
このコマンドによって次のリソースがデプロイされます。
- Azure Blob Storage アカウント。 このアカウントは会社の売上データを保持します。
- Azure Data Lake Storage Gen2 アカウント。 このアカウントは、両方の HDInsight クラスター用のストレージ アカウントとして機能します。 HDInsight と Data Lake Storage Gen2 の詳細については、Azure HDInsight と Data Lake Storage Gen2 の統合に関するページを参照してください。
- ユーザー割り当てマネージド ID。 このアカウントにより、HDInsight クラスターは Data Lake Storage Gen2 アカウントにアクセスできるようになります。
- Apache Spark クラスター。 このクラスターは、生データのクリーンアップと変換に使用されます。
- Apache Hive Interactive Query クラスター。 このクラスターにより、売上データに対してクエリを実行し、Power BI を使用してそれを視覚化できるようになります。
- ネットワーク セキュリティ グループ (NSG) 規則でサポートされている Azure 仮想ネットワーク。 この仮想ネットワークでは、クラスターによる通信とその通信のセキュリティ保護が可能になります。
クラスターの作成には約 20 分かかることがあります。
クラスターへの SSH アクセスに使用される既定のパスワードは、Thisisapassword1 です。 このパスワードを変更する場合は、./templates/resourcesparameters_remainder.json ファイルに移動し、sparksshPassword、sparkClusterLoginPassword、llapClusterLoginPassword、llapsshPassword パラメーターのパスワードを変更してください。
デプロイを確認してリソースの情報を収集する
デプロイの状態を確認する場合は、Azure portal でそのリソース グループに移動します。 [設定] の [デプロイ] を選択し、デプロイを選択します。 ここで、正常にデプロイされたリソースとまだ進行中のリソースを確認できます。
クラスターの名前を表示するには、次のコマンドを入力します。
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEAzure Storage アカウントとアクセス キーを表示するには、次のコマンドを入力します。
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYData Lake Storage Gen2 アカウントとアクセス キーを表示するには、次のコマンドを入力します。
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Data Factory の作成
Azure Data Factory とは、Azure Pipelines の自動化に役立つツールです。 これは、これらのタスクを実現する唯一の方法ではありませんが、これらのプロセスを自動化するための優れた方法です。 Azure Data Factory の詳細については、Azure Data Factory のドキュメントを参照してください。
このデータ ファクトリには、次の 2 つのアクティビティを含む 1 つのパイプラインがあります。
- 1 つ目のアクティビティでは、Azure Blob Storage から Data Lake Storage Gen 2 ストレージ アカウントにデータをコピーして、データ インジェストを模倣します。
- 2 つ目のアクティビティでは、Spark クラスター内でこのデータを変換します。 このスクリプトでは、不要な列を削除することによって、データを変換します。 また、1 回の取引で生じた収益を計算する新しい列が追加されます。
Azure Data Factory パイプラインを設定するには、次のコマンドを実行します。 現在のディレクトリは hdinsight-sales-insights-etl のままにする必要があります。
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
このスクリプトでは、次のことが行われます。
- Data Lake Storage Gen2 ストレージ アカウントに対する
Storage Blob Data Contributorアクセス許可を持つサービス プリンシパルを作成します。 - Data Lake Storage Gen2 ファイル システム REST API に対する POST 要求を承認するための認証トークンを取得します。
sparktransform.pyおよびquery.hqlファイルに、Data Lake Storage Gen2 ストレージ アカウントの実際の名前を入力します。- Data Lake Storage Gen2 および Blob Storage アカウントのストレージ キーを取得します。
- 別のリソース デプロイを作成して、Azure Data Factory パイプラインとそれに関連付けられているリンクされたサービスやアクティビティを作成します。 これによって、リンクされたサービスがストレージ アカウントに正しくアクセスできるように、ストレージ キーがパラメーターとしてテンプレート ファイルに渡されます。
データ パイプラインを実行する
Data Factory のアクティビティをトリガーする
作成した Data Factory パイプラインの最初のアクティビティでは、データを Blob Storage から Data Lake Storage Gen2 に移動します。 2 つ目のアクティビティでは、Spark によるデータの変換を適用し、変換された .csv ファイルを新しい場所に保存します。 パイプライン全体が完了するまでに数分かかる場合があります。
Data Factory の名前を取得するには、次のコマンドを入力します。
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
パイプラインをトリガーするには、次のいずれかを実行します。
PowerShell で Data Factory パイプラインをトリガーします。
RESOURCEGROUPとDataFactoryNameを適切な値に置き換えてから、次のコマンドを実行します。# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipeline必要に応じて
Get-AzDataFactoryV2PipelineRunを再実行し、進行状況を監視します。または
データ ファクトリを開いて [作成と監視] を選択します。
IngestAndTransformパイプラインをポータルからトリガーします。 ポータルでのパイプラインのトリガーについては、「Azure Data Factory を使用して HDInsight でオンデマンドの Apache Hadoop クラスターを作成する」を参照してください。
パイプラインが実行されたことを確認するには、次のいずれかの手順を実行します。
- ポータルからデータ ファクトリの [監視] セクションに移動します。
- Azure Storage Explorer で、Data Lake Storage Gen 2 ストレージ アカウントに移動します。
filesファイルシステム、transformedフォルダーの順に移動して、その内容をチェックしてパイプラインが成功したかどうかを確認します。
HDInsight を使用してデータを変換する他の方法については、Jupyter Notebook の使用に関するこの記事を参照してください。
Power BI でデータを表示するためのテーブルを Interactive Query クラスターを作成する
SCP を使用して、
query.hqlファイルを LLAP クラスターにコピーします。 次のコマンドを入力します。LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/リマインダー:既定のパスワードは
Thisisapassword1です。SSH を使用して LLAP クラスターにアクセスします。 次のコマンドを入力します。
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net次のコマンドを使用して、スクリプトを実行します。
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlこのスクリプトにより、Power BI からアクセスできるマネージド テーブルが Interactive Query クラスター上に作成されます。
売上データから Power BI ダッシュボードを作成する
Power BI Desktop を開きます。
メニューから [データの取得]>[その他]>[Azure]>[HDInsight 対話型クエリ] の順に移動します。
[接続] を選択します。
[HDInsight 対話型クエリ] ダイアログから次の手順を実行します。
- [サーバー] ボックスに、LLAP クラスターの名前を
https://LLAPCLUSTERNAME.azurehdinsight.net形式で入力します。 - [データベース] ボックスに「
default」と入力します。 - [OK] を選択します。
- [サーバー] ボックスに、LLAP クラスターの名前を
[AzureHive] ダイアログから次の手順を実行します。
- [ユーザー名] ボックスに「
admin」と入力します。 - [パスワード] ボックスに「
Thisisapassword1」と入力します。 - [接続] を選択します。
- [ユーザー名] ボックスに「
[ナビゲーター] から
salesまたはsales_rawを選択して、データをプレビューします。 データが読み込まれたら、作成したいダッシュボードを試すことができます。 Power BI ダッシュボードの概要については、以下のリンクを参照してください。
リソースをクリーンアップする
このアプリケーションを今後使用しない場合は、課金されないようにするために、次のコマンドを使用して、すべてのリソースを削除してください。
リソース グループを削除するために、次のコマンドを入力します。
az group delete -n $RESOURCE_GROUPサービス プリンシパルを削除するために、次のコマンドを入力します。
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL