Sztuczna inteligencja i Edukacja maszynowe w usłudze Databricks
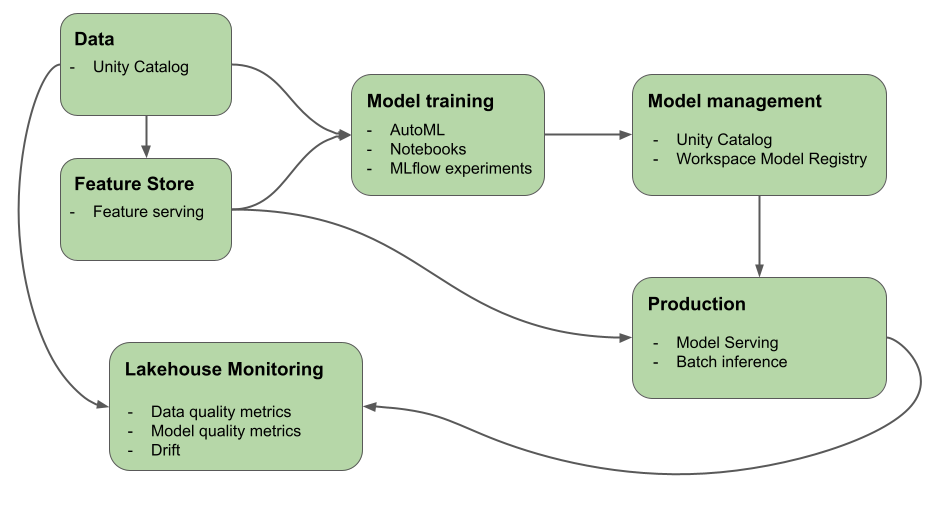
W tym artykule opisano narzędzia zapewniane przez usługę Azure Databricks ułatwiające tworzenie i monitorowanie przepływów pracy sztucznej inteligencji i uczenia maszynowego. Na diagramie pokazano, jak te składniki współpracują ze sobą, aby ułatwić wdrożenie procesu tworzenia i wdrażania modelu.
Dlaczego warto używać usługi Databricks do uczenia maszynowego i uczenia głębokiego?
Usługa Azure Databricks umożliwia zaimplementowanie pełnego cyklu życia uczenia maszynowego na jednej platformie z kompleksową obsługą ładu w całym potoku uczenia maszynowego. Usługa Azure Databricks obejmuje następujące wbudowane narzędzia do obsługi przepływów pracy uczenia maszynowego:
- Wykaz aparatu Unity na potrzeby zapewniania ładu, odnajdywania, przechowywania wersji i kontroli dostępu do danych, funkcji, modeli i funkcji.
- Monitorowanie usługi Lakehouse na potrzeby monitorowania danych.
- Inżynieria cech i obsługa.
- Obsługa cyklu życia modelu:
- Rozwiązanie AutoML usługi Databricks na potrzeby zautomatyzowanego trenowania modelu.
- MLflow na potrzeby śledzenia programowania modeli.
- Wykaz aparatu Unity na potrzeby zarządzania modelami.
- Obsługa modelu usługi Databricks na potrzeby obsługi modelu o wysokiej dostępności i małych opóźnieniach. Obejmuje to wdrażanie maszyn LLM przy użyciu:
- Podstawowe interfejsy API modelu, które umożliwiają uzyskiwanie dostępu do najnowocześniejszego otwartego modelu i wykonywanie zapytań o nie z poziomu punktu końcowego obsługującego.
- Modele zewnętrzne, które umożliwiają dostęp do modeli hostowanych poza usługą Databricks.
- Monitorowanie usługi Lakehouse w celu śledzenia jakości i dryfu przewidywania modelu.
- Przepływy pracy usługi Databricks dla zautomatyzowanych przepływów pracy i potoków ETL gotowych do produkcji.
- Foldery Git usługi Databricks na potrzeby zarządzania kodem i integracji z usługą Git.
Uczenie głębokie w usłudze Databricks
Konfigurowanie infrastruktury dla aplikacji uczenia głębokiego może być trudne.
Środowisko Databricks Runtime for Machine Edukacja zajmuje się tym za Ciebie, z klastrami, które mają wbudowane wersje najpopularniejszych bibliotek uczenia głębokiego, takich jak TensorFlow, PyTorch i Keras, oraz biblioteki pomocnicze, takie jak Petastorm, Hyperopt i Horovod. Klastry uczenia maszynowego środowiska Databricks Runtime obejmują również wstępnie skonfigurowaną obsługę procesora GPU ze sterownikami i bibliotekami pomocniczymi. Obsługuje również biblioteki, takie jak Ray , aby zrównać przetwarzanie obliczeniowe na potrzeby skalowania przepływów pracy uczenia maszynowego i aplikacji sztucznej inteligencji.
Klastry uczenia maszynowego środowiska Databricks Runtime obejmują również wstępnie skonfigurowaną obsługę procesora GPU ze sterownikami i bibliotekami pomocniczymi. Obsługa modeli usługi Databricks umożliwia tworzenie skalowalnych punktów końcowych procesora GPU dla modeli uczenia głębokiego bez dodatkowej konfiguracji.
W przypadku aplikacji uczenia maszynowego usługa Databricks zaleca używanie klastra z uruchomionym środowiskiem Databricks Runtime dla usługi Machine Edukacja. Zobacz Tworzenie klastra przy użyciu usługi Databricks Runtime ML.
Aby rozpocząć uczenie głębokie w usłudze Databricks, zobacz:
- Najlepsze rozwiązania dotyczące uczenia głębokiego w usłudze Azure Databricks
- Uczenie głębokie w usłudze Databricks
- Rozwiązania referencyjne dotyczące uczenia głębokiego
Duże modele językowe (LLM) i generowanie sztucznej inteligencji w usłudze Databricks
Środowisko Databricks Runtime for Machine Edukacja zawiera biblioteki, takie jak Hugging Face Transformers i LangChain, które umożliwiają integrację istniejących wstępnie wytrenowanych modeli lub innych bibliotek typu open source do przepływu pracy. Integracja usługi Databricks MLflow ułatwia korzystanie z usługi śledzenia MLflow z potokami przekształcania, modelami i składnikami przetwarzania. Ponadto możesz zintegrować modele OpenAI lub rozwiązania od partnerów, takich jak John Snow Labs , w przepływach pracy usługi Azure Databricks.
Za pomocą usługi Azure Databricks możesz dostosować moduł LLM na danych dla określonego zadania. Dzięki obsłudze narzędzi typu open source, takich jak Hugging Face i DeepSpeed, możesz efektywnie podjąć podstawy LLM i wytrenować je przy użyciu własnych danych, aby poprawić jego dokładność dla określonej domeny i obciążenia. Następnie możesz skorzystać z niestandardowego rozwiązania LLM w aplikacjach generacyjnych sztucznej inteligencji.
Ponadto usługa Databricks udostępnia podstawowe interfejsy API modelu i modele zewnętrzne, które umożliwiają uzyskiwanie dostępu do najnowocześniejszego otwartego modelu i wykonywanie zapytań o nie z poziomu punktu końcowego obsługującego. Korzystając z interfejsów API modelu Foundation, deweloperzy mogą szybko i łatwo tworzyć aplikacje korzystające z wysokiej jakości modelu generowania sztucznej inteligencji bez konieczności utrzymywania własnego wdrożenia modelu.
W przypadku użytkowników sql usługa Databricks udostępnia funkcje sztucznej inteligencji, których analitycy danych SQL mogą używać do uzyskiwania dostępu do modeli LLM, w tym z platformy OpenAI, bezpośrednio w potokach danych i przepływach pracy. Zobacz Funkcje sztucznej inteligencji w usłudze Azure Databricks.
Databricks Runtime for Machine Edukacja
Środowisko Databricks Runtime for Machine Edukacja (Databricks Runtime ML) automatyzuje tworzenie klastra przy użyciu wstępnie utworzonej infrastruktury uczenia maszynowego i uczenia głębokiego, w tym najpopularniejszych bibliotek ML i DL. Aby uzyskać pełną listę bibliotek w każdej wersji środowiska Databricks Runtime ML, zobacz informacje o wersji.
Aby uzyskać dostęp do danych w wykazie aparatu Unity dla przepływów pracy uczenia maszynowego, tryb dostępu dla klastra musi być pojedynczym użytkownikiem (przypisanym). Udostępnione klastry nie są zgodne ze środowiskiem Databricks Runtime for Machine Edukacja. Ponadto środowisko Databricks Runtime ML nie jest obsługiwane w klastrach lub klastrach TableACLs z ustawioną wartością spark.databricks.pyspark.enableProcessIsolation configtrue.
Tworzenie klastra przy użyciu środowiska Databricks Runtime ML
Podczas tworzenia klastra wybierz wersję uczenia maszynowego środowiska Databricks Runtime z menu rozwijanego Wersja środowiska uruchomieniowego usługi Databricks. Dostępne są zarówno środowiska uruchomieniowe uczenia maszynowego z obsługą procesora CPU, jak i procesora GPU.

Jeśli wybierzesz klaster z menu rozwijanego w notesie, wersja środowiska Uruchomieniowego usługi Databricks pojawi się po prawej stronie nazwy klastra:
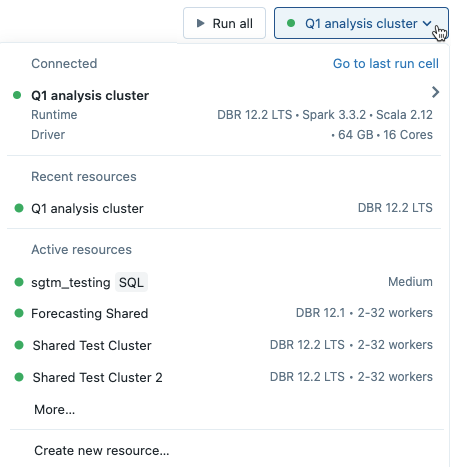
W przypadku wybrania środowiska uruchomieniowego uczenia maszynowego z obsługą procesora GPU zostanie wyświetlony monit o wybranie zgodnego typu sterownika i typu procesu roboczego. Niezgodne typy wystąpień są wyszarywane w menu rozwijanym. Typy wystąpień z obsługą procesora GPU są wyświetlane na liście w ramach etykiety przyspieszonej procesora GPU.
Uwaga
Aby uzyskać dostęp do danych w wykazie aparatu Unity dla przepływów pracy uczenia maszynowego, tryb dostępu dla klastra musi być pojedynczym użytkownikiem (przypisanym). Udostępnione klastry nie są zgodne ze środowiskiem Databricks Runtime for Machine Edukacja.
Biblioteki zawarte w środowisku Databricks Runtime ML
Środowisko Databricks Runtime ML zawiera wiele popularnych bibliotek uczenia maszynowego. Biblioteki są aktualizowane wraz z każdą wersją w celu uwzględnienia nowych funkcji i poprawek.
Usługa Databricks wyznaczyła podzbiór obsługiwanych bibliotek jako bibliotek najwyższego poziomu. W przypadku tych bibliotek usługa Databricks zapewnia szybszy cykl aktualizacji, aktualizując do najnowszych wersji pakietów przy użyciu każdej wersji środowiska uruchomieniowego (konflikty zależności). Usługa Databricks oferuje również zaawansowaną obsługę, testowanie i optymalizacje osadzone dla bibliotek najwyższego poziomu.
Aby uzyskać pełną listę najwyższej warstwy i innych udostępnionych bibliotek, zobacz informacje o wersji środowiska Databricks Runtime ML.
Następne kroki
Aby rozpocząć pracę, zobacz:
Aby uzyskać zalecany przepływ pracy metodyki MLOps w usłudze Databricks Machine Edukacja, zobacz:
Aby dowiedzieć się więcej o kluczowych funkcjach usługi Databricks Machine Edukacja, zobacz: