AI s toky dat
Tento článek ukazuje, jak můžete s toky dat používat umělou inteligenci (AI). Tento článek popisuje:
- Cognitive Services
- Automatizované strojové učení
- Integrace služby Azure Machine Učení
Cognitive Services v Power BI
Pomocí cognitive Services v Power BI můžete použít různé algoritmy z Azure Cognitive Services k obohacení dat v samoobslužné přípravě dat pro toky dat.
Mezi podporované služby patří analýza mínění, extrakce klíčových frází, rozpoznávání jazyka a označování obrázků. Transformace se spouštějí na služba Power BI a nevyžadují předplatné Azure Cognitive Services. Tato funkce vyžaduje Power BI Premium.
Povolení funkcí AI
Kognitivní služby jsou podporované pro uzly kapacity Premium EM2, A2 nebo P1 a další uzly s více prostředky. Kognitivní služby jsou k dispozici také s licencí Premium na uživatele (PPU). Ke spouštění kognitivních služeb se používá samostatná úloha AI v kapacitě. Než v Power BI použijete kognitivní služby, musí být úloha AI povolená v nastavení kapacity na portálu Správa. Úlohu AI můžete zapnout v části úlohy a definovat maximální velikost paměti, kterou má tato úloha využívat. Doporučený limit paměti je 20 %. Překročení tohoto limitu způsobí zpomalení dotazu.
Začínáme se službami Cognitive Services v Power BI
Transformace služeb Cognitive Services jsou součástí samoobslužné přípravy dat pro toky dat. Pokud chcete data rozšířit pomocí Cognitive Services, začněte úpravou toku dat.
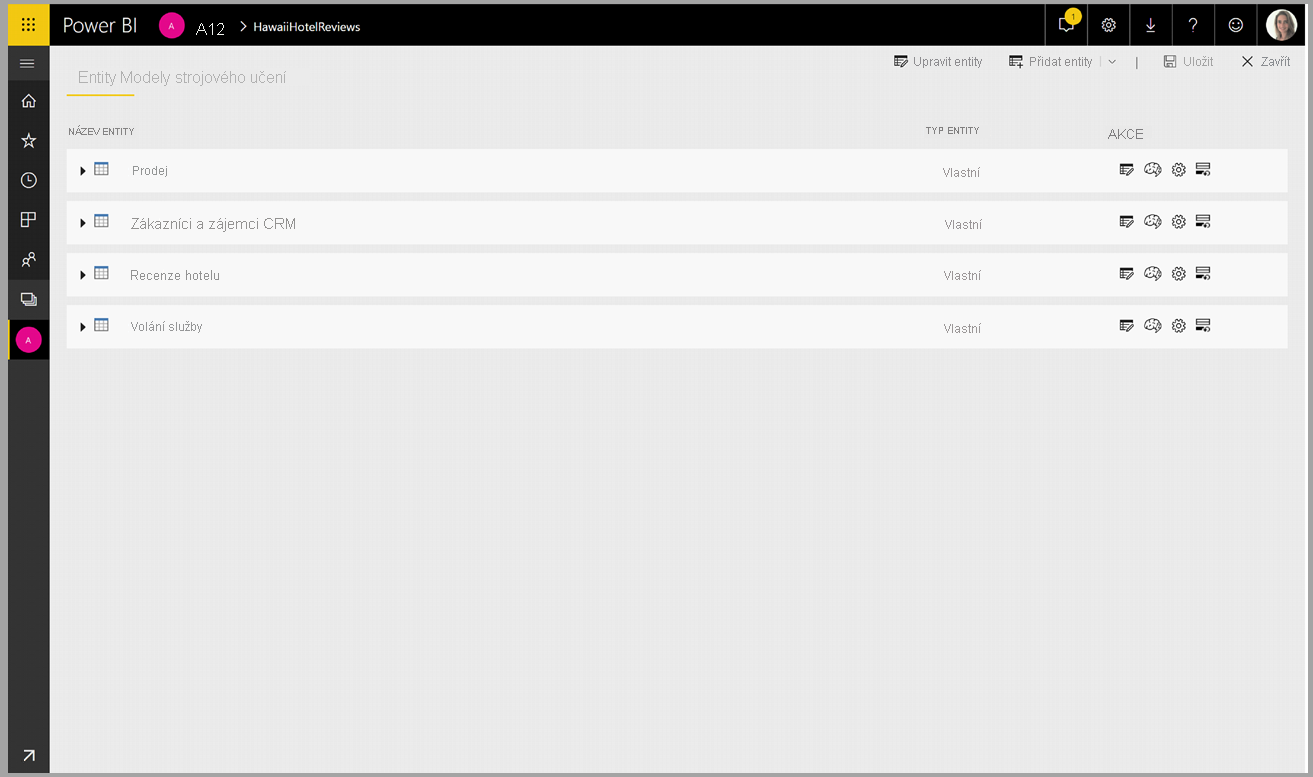
Na horním pásu karet Editor Power Query vyberte tlačítko Přehledy AI.
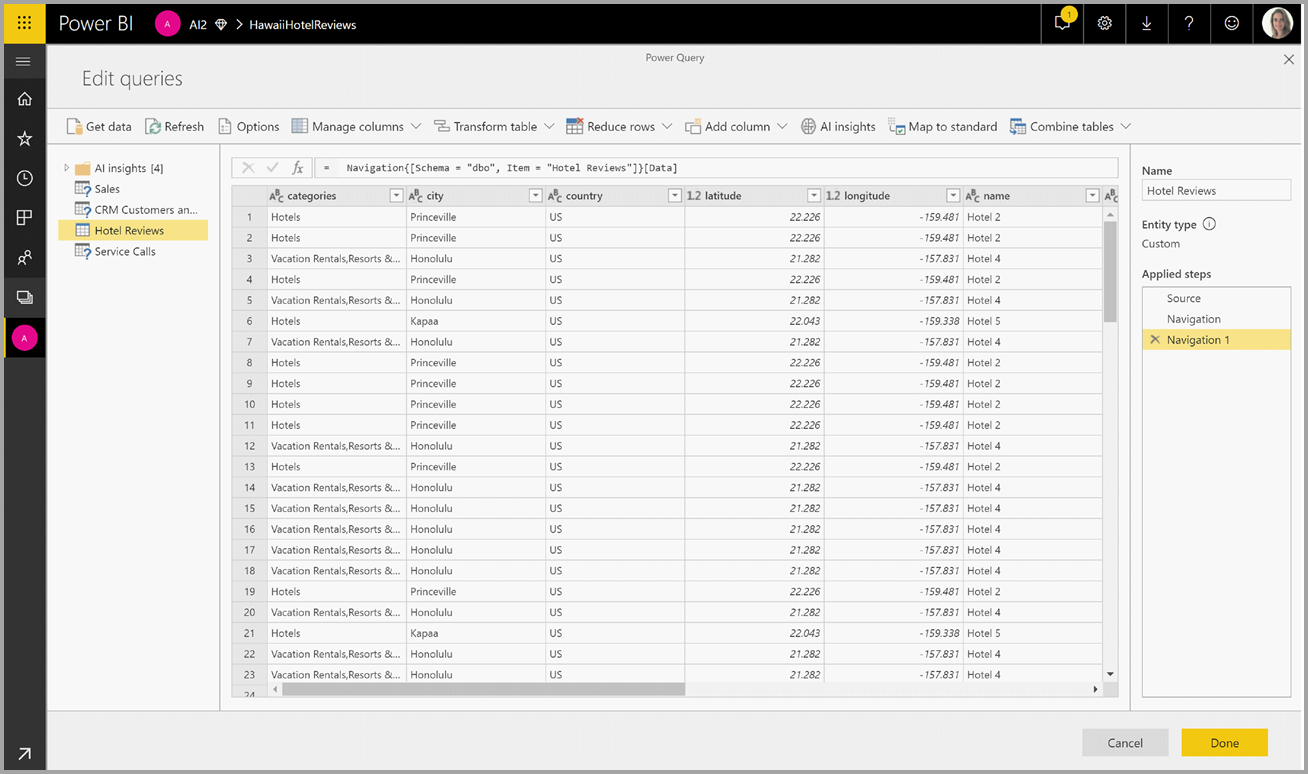
V automaticky otevíraných otevíraných oknech vyberte funkci, kterou chcete použít, a data, která chcete transformovat. V tomto příkladu se skóre mínění sloupce, který obsahuje text revize.
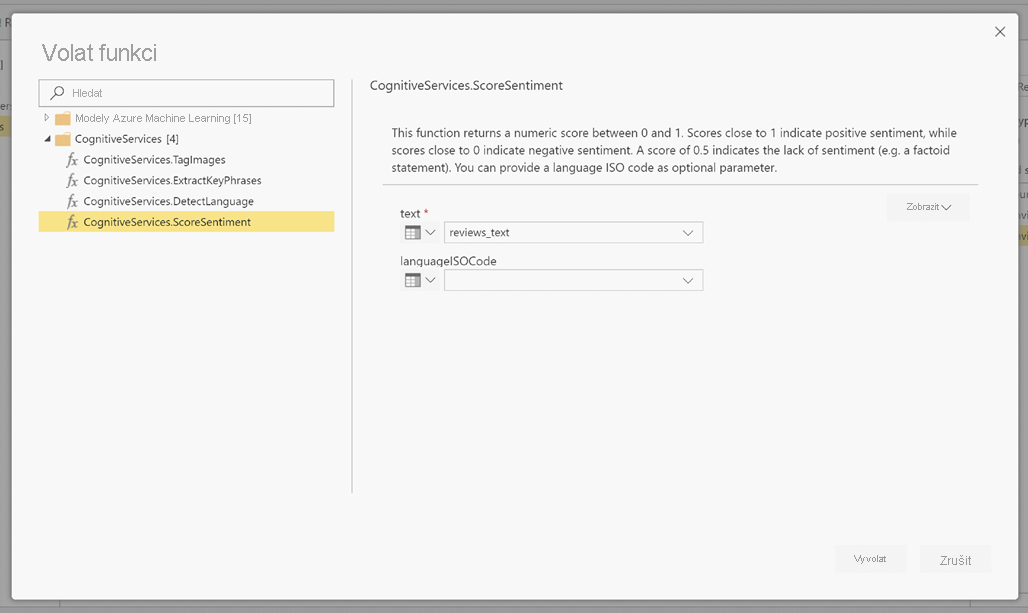
LanguageISOCode je volitelný vstup pro zadání jazyka textu. Tento sloupec očekává kód ISO. Jako vstup pro LanguageISOCode můžete použít sloupec nebo můžete použít statický sloupec. V tomto příkladu je jazyk určen jako angličtina (en) pro celý sloupec. Pokud tento sloupec necháte prázdný, Power BI před použitím funkce automaticky rozpozná jazyk. Pak vyberte Vyvolat.
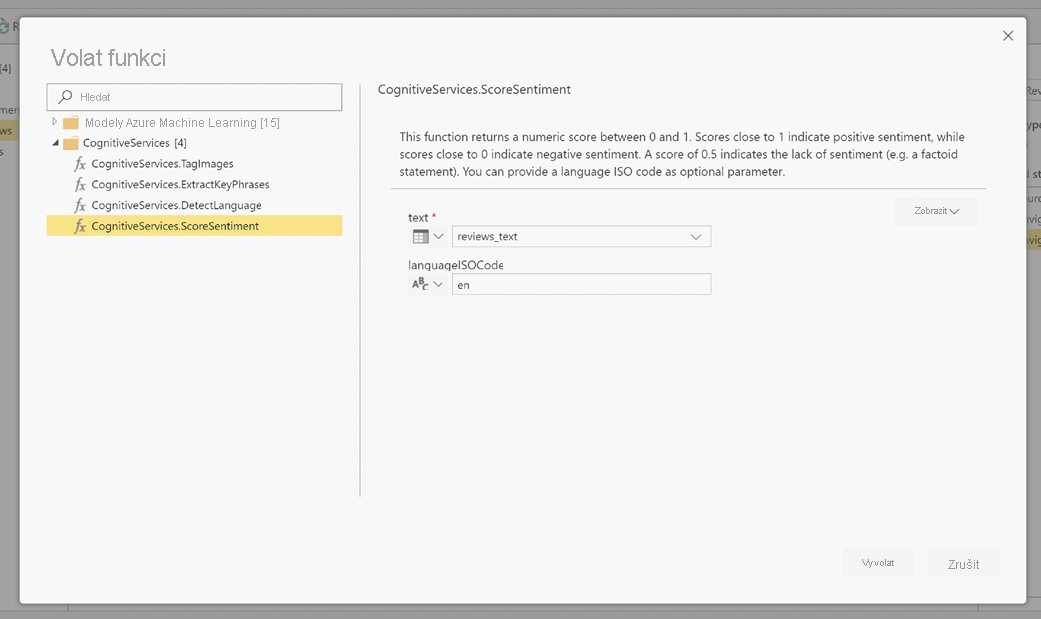
Po vyvolání funkce se výsledek přidá jako nový sloupec do tabulky. Transformace se také přidá jako použitý krok v dotazu.
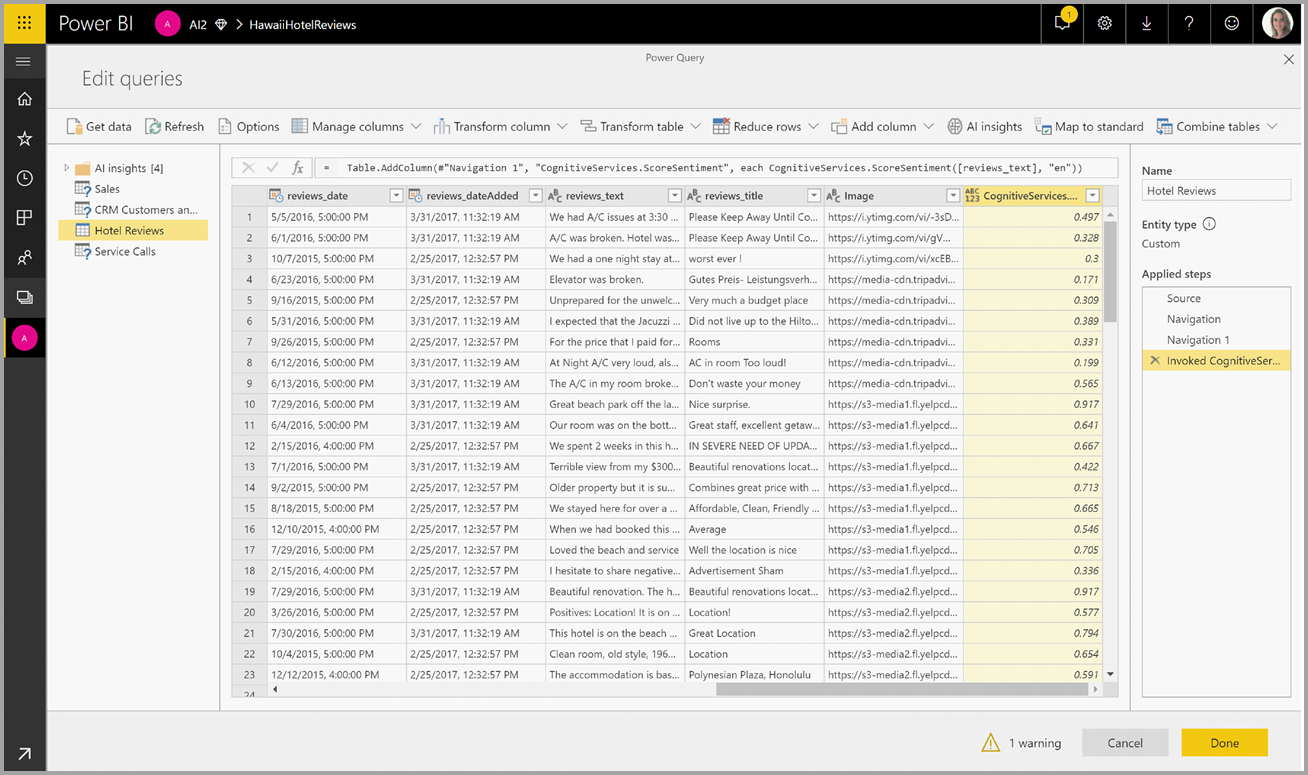
Pokud funkce vrátí více výstupních sloupců, vyvolání funkce přidá nový sloupec s řádkem více výstupních sloupců.
Pomocí možnosti rozbalení můžete do dat přidat jednu nebo obě hodnoty jako sloupce.
Dostupné funkce
Tato část popisuje dostupné funkce ve službách Cognitive Services v Power BI.
Rozpoznávání jazyka
Funkce rozpoznávání jazyka vyhodnocuje textové zadání a pro každý sloupec vrátí název jazyka a identifikátor ISO. Tato funkce je užitečná pro sloupce dat, které shromažďují libovolný text, kde jazyk není znám. Funkce očekává jako vstup data v textovém formátu.
Analýza textu rozpozná až 120 jazyků. Další informace najdete v tématu Co je rozpoznávání jazyka ve službě Azure Cognitive Service pro jazyk.
Extrakce klíčových frází
Funkce Extrakce klíčových frází vyhodnocuje nestrukturovaný text a pro každý textový sloupec vrátí seznam klíčových frází. Funkce vyžaduje jako vstup textový sloupec a přijímá volitelný vstup pro LanguageISOCode. Další informace najdete v tématu Začínáme.
Extrakce klíčových frází funguje nejlépe, když jí dáte větší bloky textu, na které chcete pracovat, a to opakem než analýza mínění. Analýza mínění funguje lépe na menších blocích textu. Zvažte podle toho možnost restrukturalizace vstupů, abyste z obou operací získali co nejlepší výsledky.
Skóre mínění
Funkce Skóre mínění vyhodnotí textové zadání a vrátí skóre mínění pro každý dokument v rozsahu od 0 (záporné) do 1 (kladné). Tato funkce je užitečná pro detekci pozitivního a negativního mínění v sociálních médiích, recenzích zákazníků a diskuzních fórech.
Analýza textu vygeneruje pomocí algoritmu pro klasifikaci strojového učení skóre mínění v rozsahu 0 až 1. Skóre blížící se 1 značí pozitivní mínění. Skóre blížící se 0 značí negativní mínění. Model je předem natrénovaný rozsáhlým textem textu s přidruženími mínění. V současné době není možné poskytovat vlastní trénovací data. Při analýze textu model používá různé postupy, například zpracování textu, analýzu částí řeči, rozmístění slov a asociace slov. Další informace o algoritmu najdete v tématu Machine Učení a Analýza textu.
Analýza mínění se provádí na celém vstupním sloupci, na rozdíl od extrahování mínění pro konkrétní tabulku v textu. V praxi je potřeba zlepšit přesnost vyhodnocování, když dokumenty obsahují jednu nebo dvě věty, a ne velký blok textu. Během fáze posouzení objektivity model určuje, zda je vstupní sloupec jako celek objektivní nebo obsahuje mínění. Vstupní sloupec, který je většinou objektivní, nepostupuje k frázi detekce mínění, což vede k skóre 0,50 bez dalšího zpracování. U vstupních sloupců, které pokračují v kanálu, vygeneruje další fáze skóre větší nebo menší než 0,50 v závislosti na stupni mínění zjištěné ve vstupním sloupci.
Pro analýzu mínění se momentálně podporuje angličtina, němčina, španělština a francouzština. Další jazyky jsou ve verzi Preview. Další informace najdete v tématu Co je rozpoznávání jazyka ve službě Azure Cognitive Service pro jazyk.
Označení obrázků
Funkce Tag Images vrátí značky založené na více než 2 000 rozpoznatelných objektech, živých bytostech, scenériích a akcích. Pokud jsou značky nejednoznačné nebo nejsou společné, výstup poskytuje "rady" k objasnění významu značky v kontextu známého nastavení. Značky nejsou uspořádané jako taxonomie a neexistují žádné hierarchie dědičnosti. Shromážděné značky obsahu tvoří základ „popisu“ obrázku, který se zobrazí v čitelném jazyce formátovaném do celých vět.
Po nahrání obrázku nebo zadání adresy URL obrázku Počítačové zpracování obrazu algoritmy výstupní značky na základě objektů, živých bytostí a akcí identifikovaných na obrázku. Označování se neomezuje na hlavní předmět, například postavu v popředí, ale zahrnuje také prostředí (interiér nebo exteriér), nábytek, nástroje, rostliny, zvířata, příslušenství, pomůcky atd.
Tato funkce vyžaduje jako vstup adresu URL obrázku nebo sloupec abase-64. V tuto chvíli označování obrázků podporuje angličtinu, španělštinu, japonštinu, portugalštinu a zjednodušenou čínštinu. Další informace naleznete v tématu ComputerVision Interface.
Automatizované strojové učení v Power BI
Automatizované strojové učení (AutoML) pro toky dat umožňuje obchodním analytikům trénovat, ověřovat a volat modely strojového učení (ML) přímo v Power BI. Zahrnuje jednoduché prostředí pro vytvoření nového modelu ML, kde analytici můžou pomocí svých toků dat určit vstupní data pro trénování modelu. Služba automaticky extrahuje nejrelevantní funkce, vybere příslušný algoritmus a naladí a ověří model ML. Po vytrénování modelu Power BI automaticky vygeneruje sestavu výkonu, která obsahuje výsledky ověření. Model je pak možné vyvolat u všech nových nebo aktualizovaných dat v rámci toku dat.
Automatizované strojové učení je dostupné jenom pro toky dat hostované v kapacitách Power BI Premium a Embedded.
Práce s AutoML
Strojové učení a AI vidí nevídaný nárůst popularity z odvětví a vědeckých výzkumných oborů. Firmy také hledají způsoby integrace těchto nových technologií do svých operací.
Toky dat nabízejí samoobslužnou přípravu dat pro velké objemy dat. AutoML je integrované do toků dat a umožňuje využít úsilí přípravy dat pro vytváření modelů strojového učení přímo v Power BI.
AutoML v Power BI umožňuje datovým analytikům používat toky dat k vytváření modelů strojového učení se zjednodušeným prostředím pomocí jen dovedností Power BI. Power BI automatizuje většinu datových věd za vytvářením modelů ML. Má mantinely, které zajišťují, že vytvořený model má dobrou kvalitu a poskytuje přehled o procesu použitém k vytvoření modelu ML.
AutoML podporuje vytváření binárních prediktivních, klasifikačních a regresních modelů pro toky dat. Tyto funkce jsou typy technik strojového učení pod dohledem, což znamená, že se učí ze známých výsledků minulých pozorování, aby předpověděly výsledky jiných pozorování. Vstupní sémantický model pro trénování modelu AutoML je sada řádků, které jsou označené známými výsledky.
AutoML v Power BI integruje automatizované strojové učení ze služby Azure Machine Učení k vytvoření modelů ML. K používání AutoML v Power BI ale nepotřebujete předplatné Azure. Služba Power BI zcela spravuje proces trénování a hostování modelů ML.
Jakmile se model ML vytrénuje, AutoML automaticky vygeneruje sestavu Power BI, která vysvětluje pravděpodobný výkon modelu ML. AutoML zdůrazňuje vysvětlitelnost zvýrazněním klíčových vlivových faktorů mezi vašimi vstupy, které ovlivňují předpovědi vrácené vaším modelem. Sestava také obsahuje klíčové metriky modelu.
Další stránky vygenerované sestavy zobrazují statistický souhrn modelu a podrobnosti o trénování. Statistický souhrn je zajímavý pro uživatele, kteří chtějí vidět standardní míry datových věd o výkonu modelu. Podrobnosti trénování shrnují všechny iterace, které byly spuštěny za účelem vytvoření modelu, s přidruženými parametry modelování. Popisuje také, jak se jednotlivé vstupy použily k vytvoření modelu ML.
Pak můžete model ML použít na data pro bodování. Po aktualizaci toku dat se vaše data aktualizují pomocí předpovědí z modelu ML. Power BI také obsahuje individualizované vysvětlení pro každou konkrétní predikci, kterou model ML vytváří.
Vytvoření modelu strojového učení
Tato část popisuje, jak vytvořit model AutoML.
Příprava dat pro vytvoření modelu ML
Pokud chcete vytvořit model strojového učení v Power BI, musíte nejprve vytvořit tok dat pro data obsahující historické informace o výsledcích, které se používají k trénování modelu ML. Měli byste také přidat počítané sloupce pro všechny obchodní metriky, které můžou být silnými prediktory pro výsledek, který se pokoušíte předpovědět. Podrobnosti o konfiguraci toku dat najdete v tématu Konfigurace a využití toku dat.
AutoML má specifické požadavky na data pro trénování modelu strojového učení. Tyto požadavky jsou popsány v následujících částech na základě příslušných typů modelů.
Konfigurace vstupů modelu ML
Pokud chcete vytvořit model AutoML, vyberte ikonu ML ve sloupci Akce tabulky toku dat a vyberte Přidat model strojového učení.

Spustí se zjednodušené prostředí, které se skládá z průvodce, který vás provede procesem vytvoření modelu ML. Průvodce obsahuje následující jednoduché kroky.
1. Vyberte tabulku s historickými daty a zvolte sloupec výsledku, pro který chcete predikci.
Sloupec výsledku identifikuje atribut popisku pro trénování modelu ML, jak je znázorněno na následujícím obrázku.
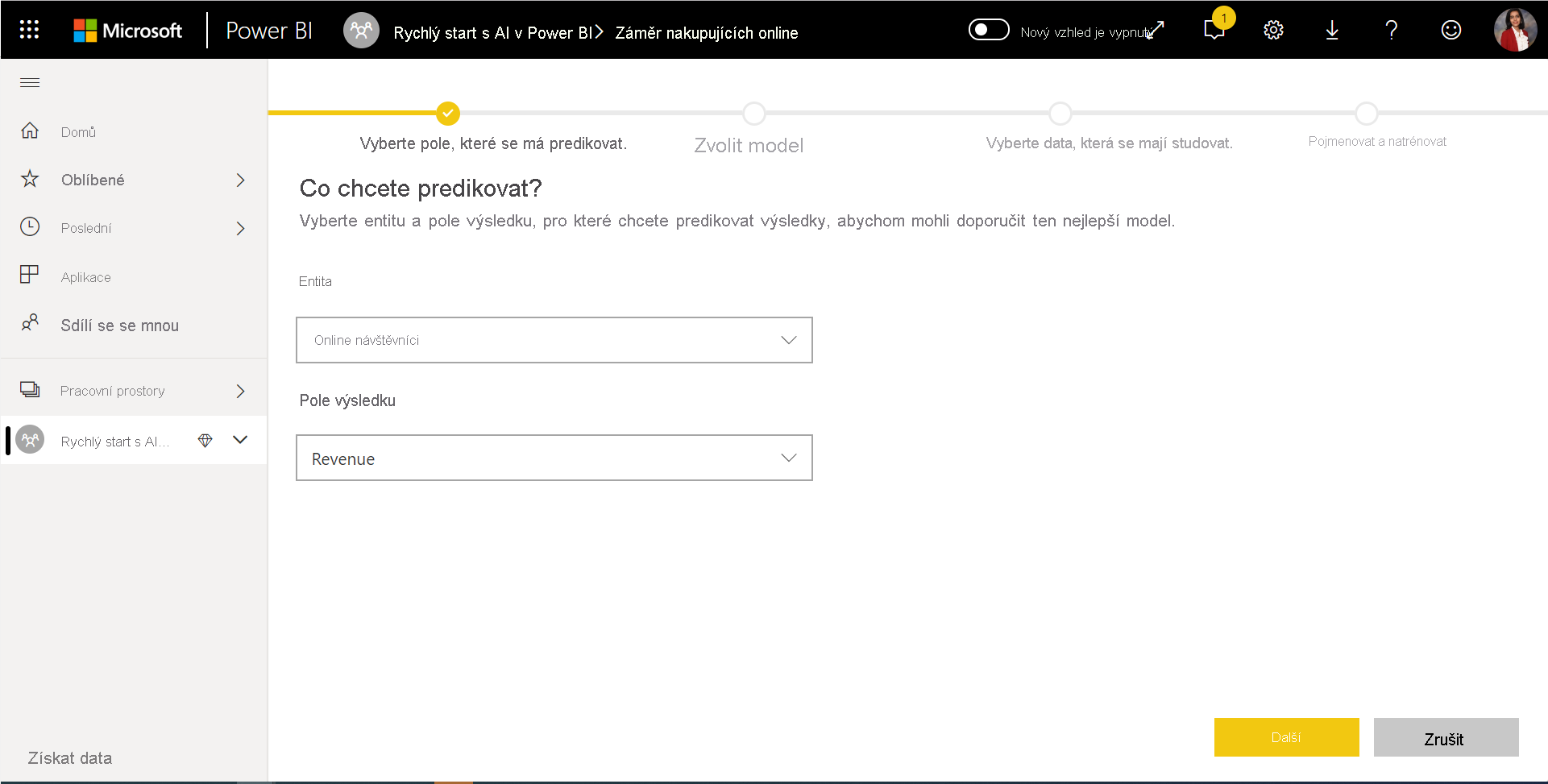
2. Volba typu modelu
Když zadáte sloupec výsledku, AutoML analyzuje data popisků a doporučí nejpravděpodobnější typ modelu ML, který je možné vytrénovat. Můžete vybrat jiný typ modelu, jak je znázorněno na následujícím obrázku, kliknutím na Vybrat model.
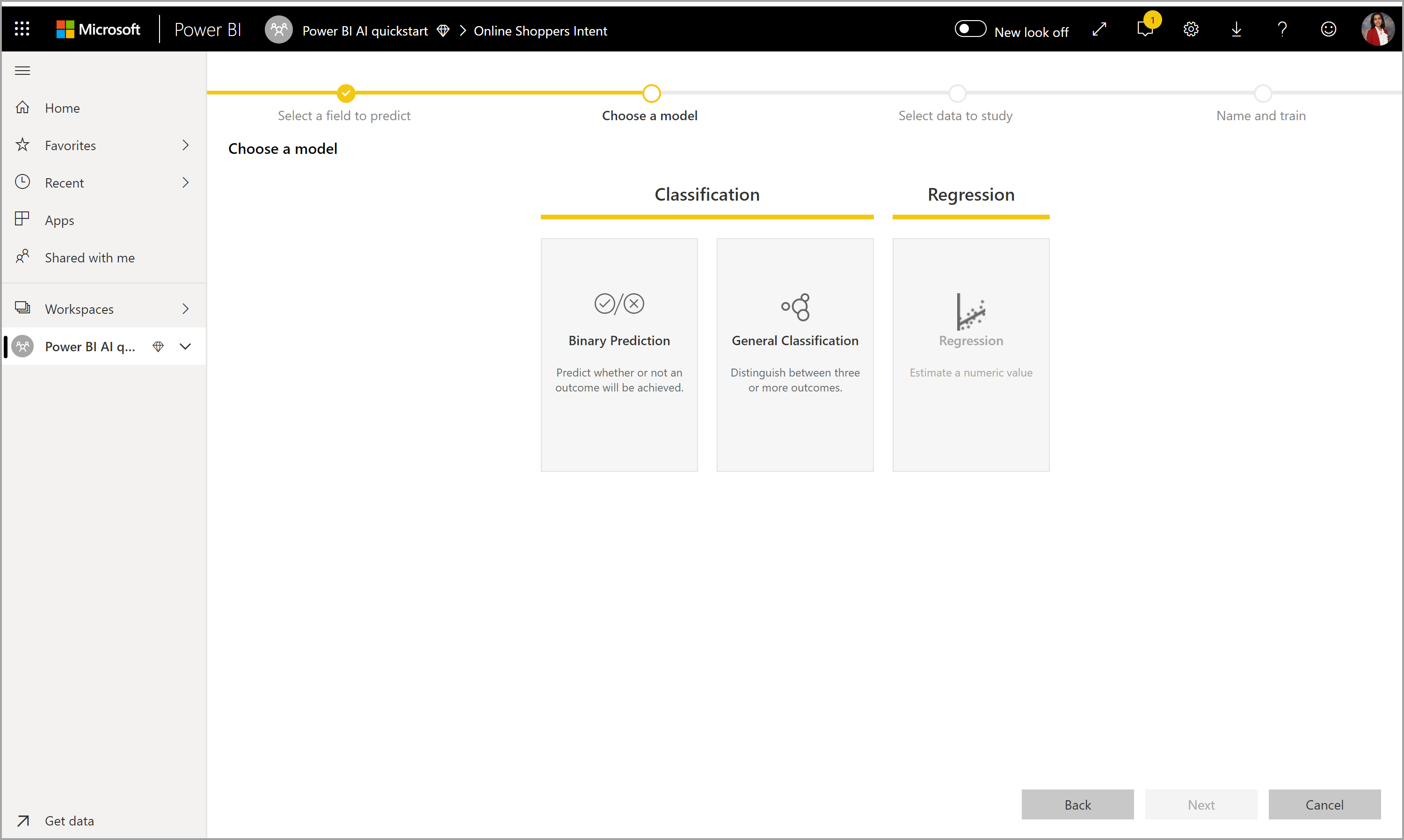
Poznámka:
Některé typy modelů nemusí být podporovány pro vybraná data, a proto by byly zakázané. V předchozím příkladu je regrese zakázána, protože textový sloupec je vybrán jako sloupec výsledku.
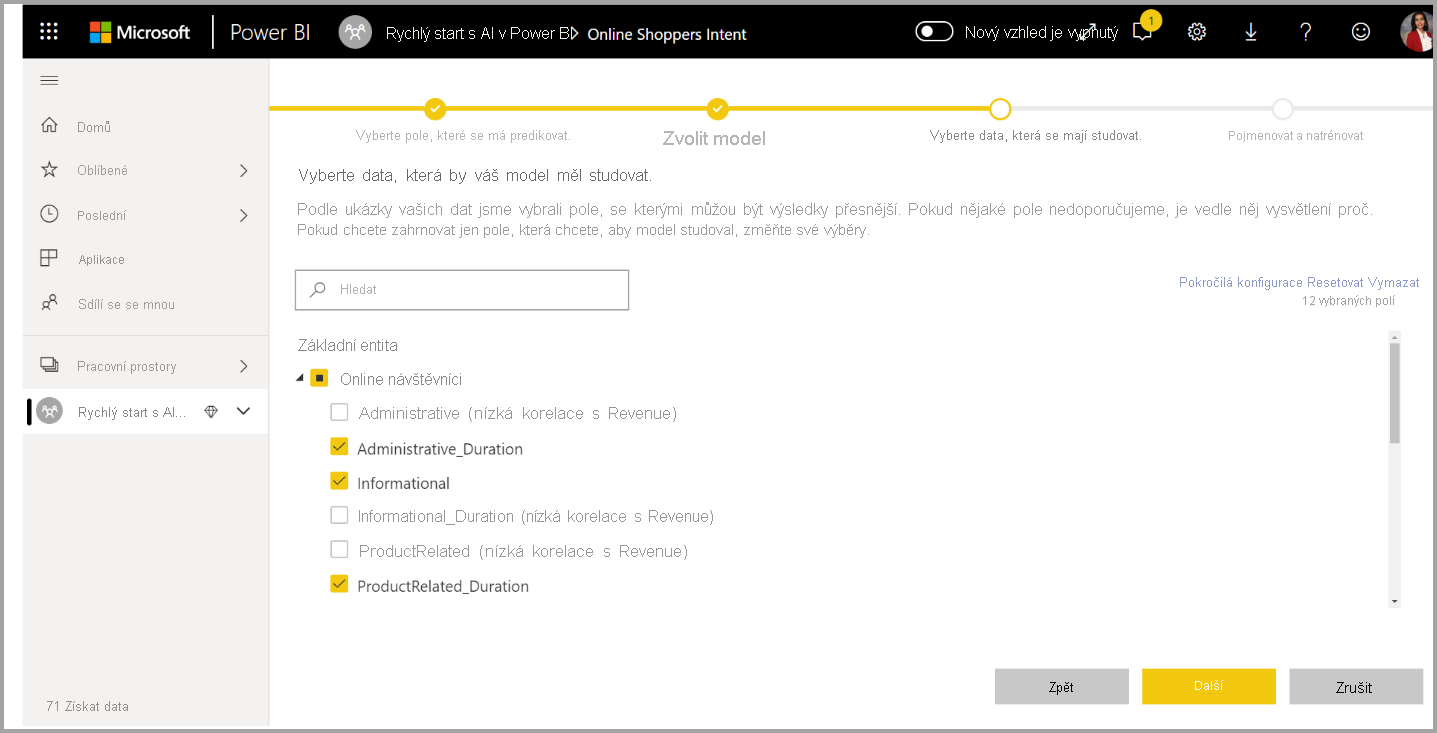
3. Vyberte vstupy, které má model používat jako prediktivní signály.
AutoML analyzuje vzorek vybrané tabulky a navrhne vstupy, které je možné použít pro trénování modelu ML. Vysvětlení jsou k dispozici vedle sloupců, které nejsou vybrané. Pokud má určitý sloupec příliš mnoho jedinečných hodnot nebo pouze jednu hodnotu, nebo nízkou nebo vysokou korelaci s výstupním sloupcem, nedoporučuje se.
Všechny vstupy, které jsou závislé na sloupci výsledku (nebo sloupci popisku), by se neměly používat pro trénování modelu ML, protože ovlivňují jeho výkon. Takové sloupce jsou označeny jako "podezřele vysoká korelace s výstupním sloupcem". Zavedení těchto sloupců do trénovacích dat způsobí únik popisků, kdy model funguje dobře s ověřovacími nebo testovacími daty, ale nemůže tento výkon odpovídat výkonu při použití v produkčním prostředí pro bodování. Únik štítků může být v modelech AutoML možný, pokud je výkon trénovacího modelu příliš dobrý, aby byl pravdivý.
Toto doporučení funkce vychází z ukázky dat, takže byste měli zkontrolovat použité vstupy. Výběry můžete změnit tak, aby zahrnovaly jenom sloupce, které má model studovat. Můžete také vybrat všechny sloupce zaškrtnutím políčka vedle názvu tabulky.
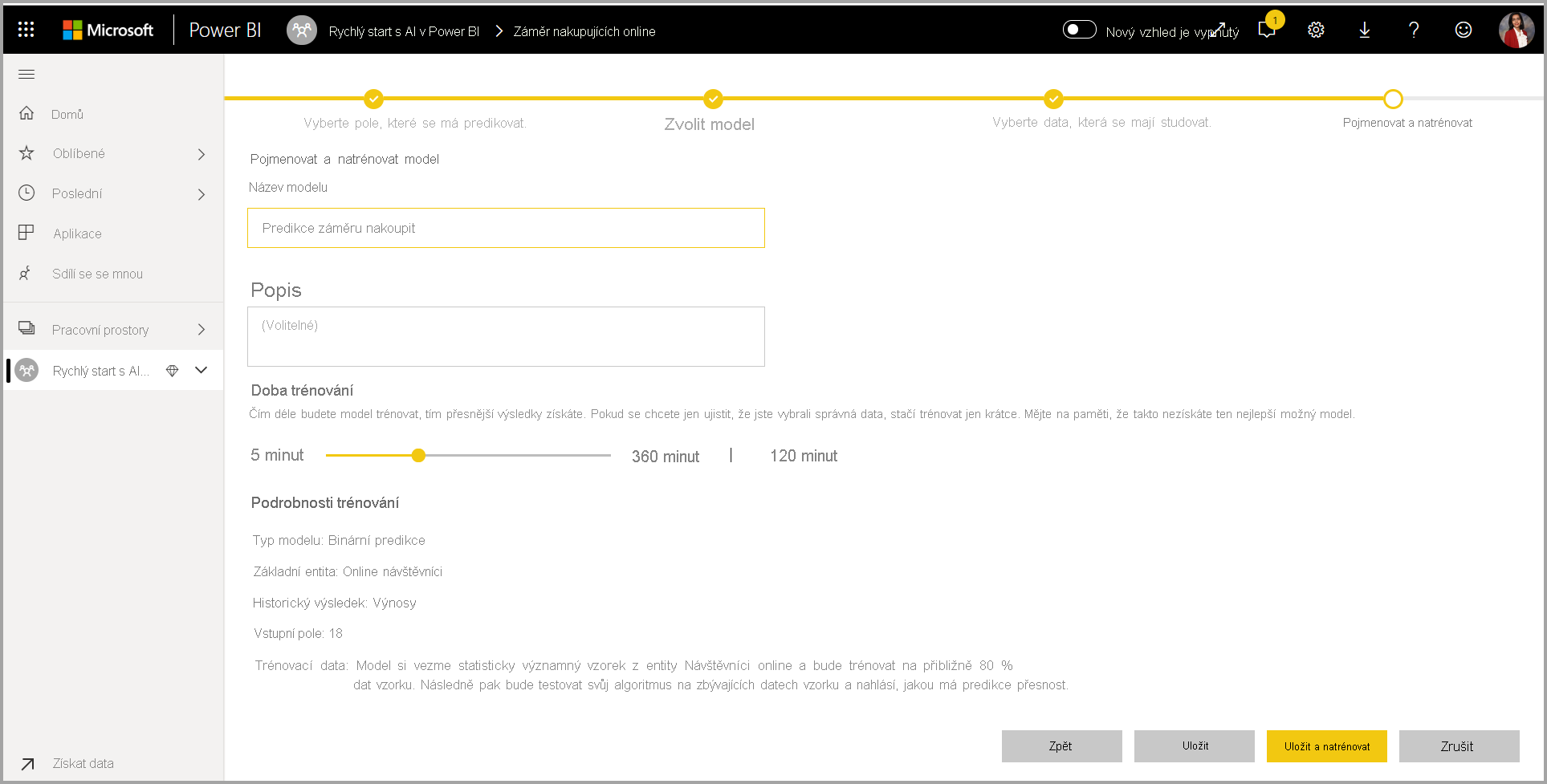
4. Pojmenujte model a uložte konfiguraci.
V posledním kroku můžete model pojmenovat, vybrat Uložit a zvolit, který zahájí trénování modelu ML. Můžete se rozhodnout zkrátit dobu trénování, abyste viděli rychlé výsledky, nebo zvýšit dobu strávenou v trénování, abyste získali nejlepší model.
Trénování modelu ML
Trénování modelů AutoML je součástí aktualizace toku dat. AutoML nejprve připraví vaše data na trénování. AutoML rozdělí historická data, která poskytujete, na sémantické modely trénování a testování. Testovací sémantický model je sada blokování, která se používá k ověření výkonu modelu po trénování. Tyto sady jsou realizovány jako trénovací a testovací tabulky v toku dat. AutoML používá pro ověření modelu křížové ověření.
Dále se analyzuje každý vstupní sloupec a použije se imputace, která nahradí chybějící hodnoty nahrazenými hodnotami. AutoML používá několik různých strategií imputace. U vstupních atributů, které jsou považovány za číselné funkce, se pro imputaci používá průměr hodnot sloupců. U vstupních atributů, které jsou považovány za kategorické funkce, používá AutoML režim hodnot sloupců pro imputaci. Architektura AutoML vypočítá střední hodnotu a režim hodnot použitých pro imputaci u podsamplového trénovacího sémantického modelu.
Potom se vzorkování a normalizace použijí na vaše data podle potřeby. U klasifikačních modelů autoML spouští vstupní data prostřednictvím stratifikovaného vzorkování a vyrovnává třídy, aby se zajistilo, že počet řádků je pro všechny stejný.
AutoML použije u každého vybraného vstupního sloupce několik transformací na základě jeho datového typu a statistických vlastností. AutoML pomocí těchto transformací extrahuje funkce pro trénování modelu ML.
Proces trénování pro modely AutoML se skládá z až 50 iterací s různými algoritmy modelování a nastavením hyperparametrů, aby bylo možné najít model s nejlepším výkonem. Trénování může končit brzy s menšími iteracemi, pokud AutoML zjistí, že není pozorováno žádné zlepšení výkonu. AutoML vyhodnocuje výkon každého z těchto modelů ověřením pomocí sémantického sémantického testu blokování. Během tohoto trénovacího kroku autoML vytvoří několik kanálů pro trénování a ověření těchto iterací. Proces vyhodnocení výkonu modelů může trvat od několika minut do několika hodin až po dobu trénování nakonfigurovanou v průvodci. Doba potřebná závisí na velikosti sémantického modelu a dostupných prostředcích kapacity.
V některýchpřípadechch
Vysvětlitelnost modelu AutoML
Po vytrénování modelu AutoML analyzuje vztah mezi vstupními funkcemi a výstupem modelu. Posuzuje velikost změny výstupu modelu pro sémantický sémantický model blokování testu pro každou vstupní funkci. Tento vztah se označuje jako důležitost funkce. K této analýze dochází v rámci aktualizace po dokončení trénování. Aktualizace proto může trvat déle, než je čas trénování nakonfigurovaný v průvodci.
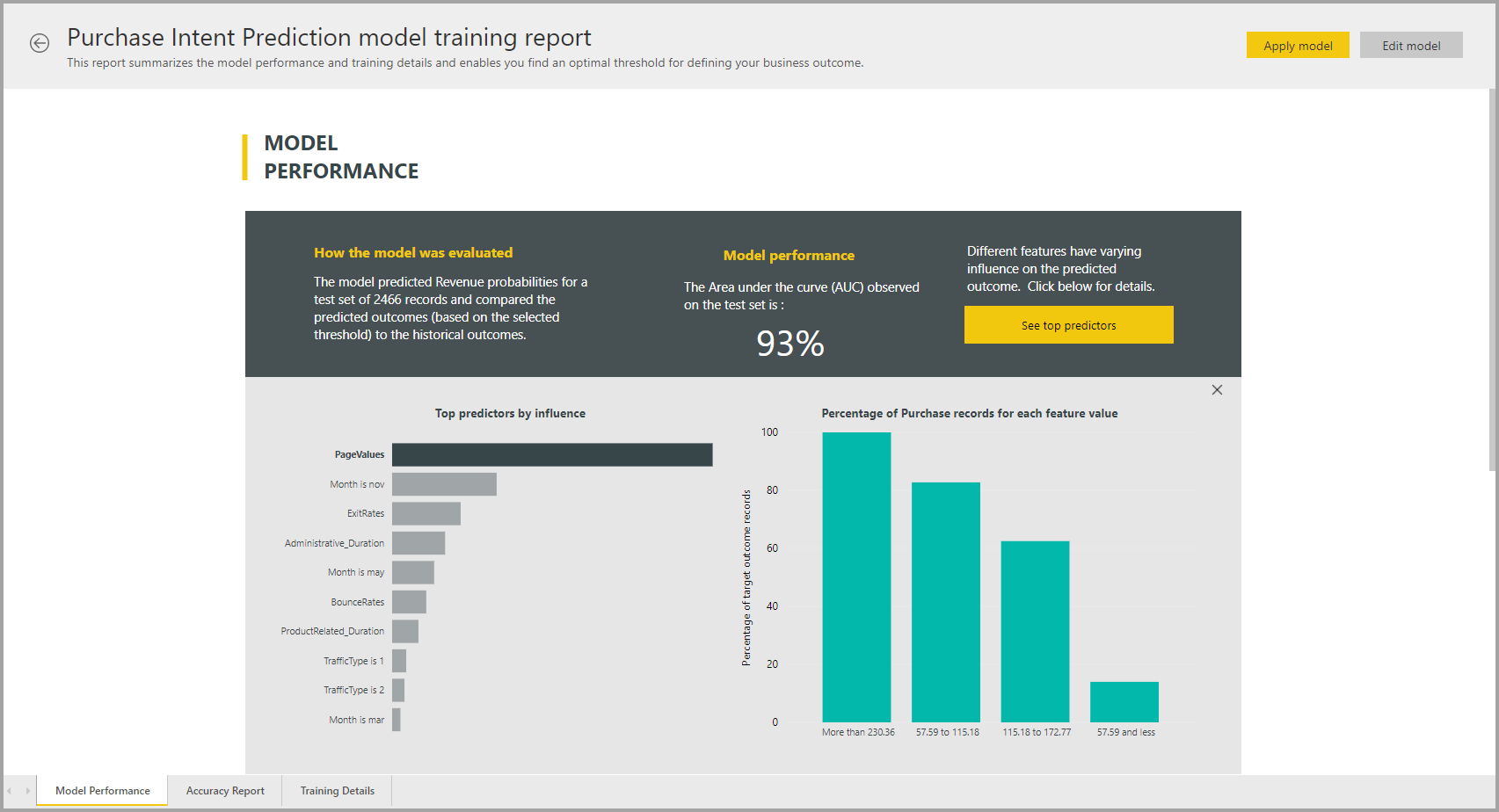
Sestava modelu AutoML
AutoML vygeneruje sestavu Power BI, která shrnuje výkon modelu během ověřování spolu s globální důležitostí funkcí. Tato sestava je přístupná z karty Machine Učení Models (Modely) po úspěšné aktualizaci toku dat. Sestava shrnuje výsledky použití modelu ML na testovací data blokování a porovnávání předpovědí se známými hodnotami výsledků.
Můžete si projít sestavu modelu, abyste pochopili její výkon. Můžete také ověřit, že klíčové vlivové faktory modelu odpovídají obchodním přehledům o známých výsledcích.
Grafy a míry použité k popisu výkonu modelu v sestavě závisí na typu modelu. Tyto grafy výkonu a míry jsou popsány v následujících částech.
Další stránky v sestavě můžou popisovat statistické míry modelu z hlediska datových věd. Například sestava binární předpovědi obsahuje graf získání a křivku ROC pro model.
Sestavy obsahují také stránku s podrobnostmi o trénování, která obsahuje popis způsobu trénování modelu a graf popisující výkon modelu při každém spuštění iterací.
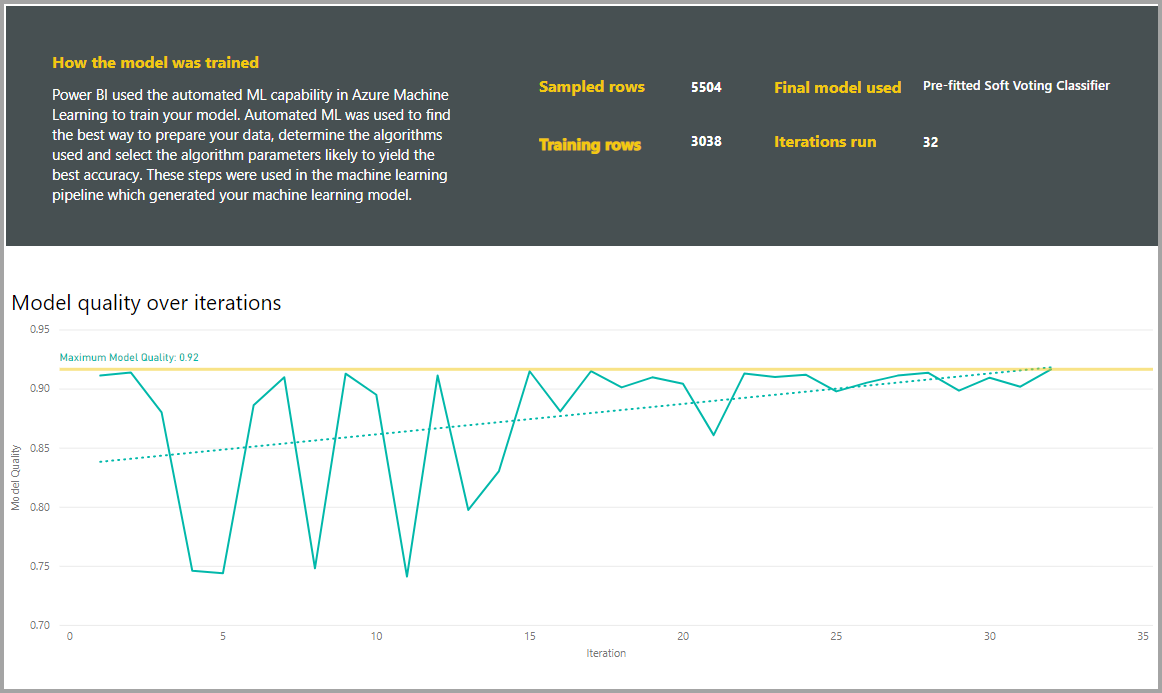
Další část na této stránce popisuje zjištěný typ vstupního sloupce a metody imputace použité k vyplnění chybějících hodnot. Zahrnuje také parametry používané konečným modelem.
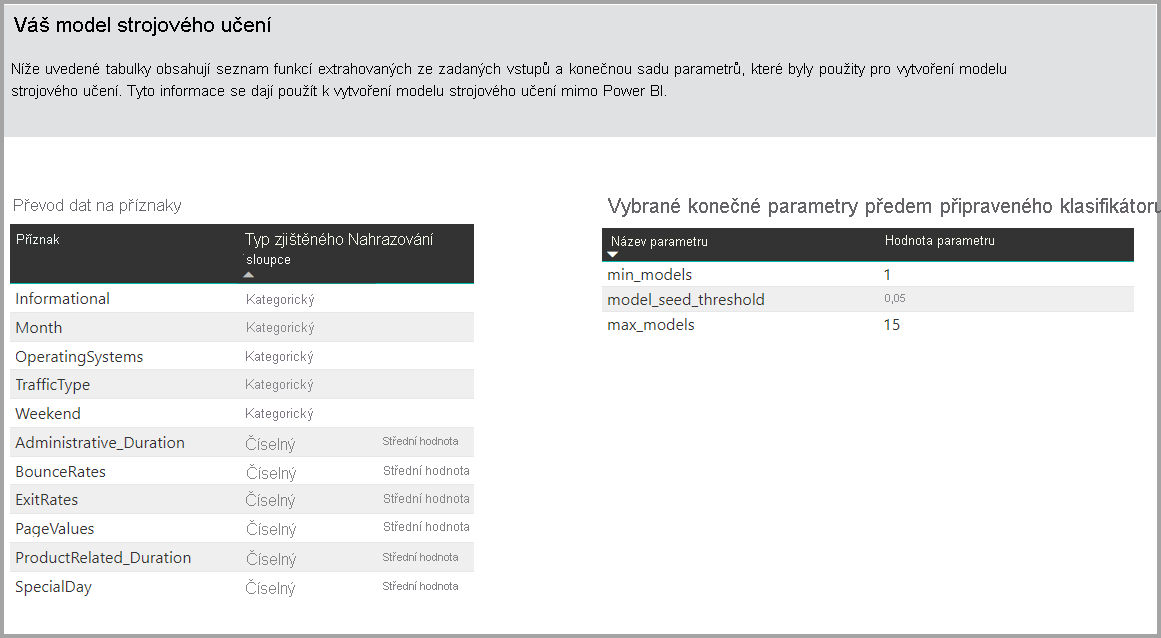
Pokud vytvořený model používá souborové učení, stránka Podrobnosti trénování obsahuje také graf zobrazující váhu každého základního modelu v souboru a jeho parametry.

Použití modelu AutoML
Pokud jste spokojení s výkonem vytvořeného modelu ML, můžete ho použít na nová nebo aktualizovaná data při aktualizaci toku dat. V sestavě modelu vyberte tlačítko Použít v pravém horním rohu nebo tlačítko Použít model ML v části Akce na kartě Stroj Učení Modely.
Pokud chcete použít model ML, musíte zadat název tabulky, na kterou se musí použít, a předponu pro sloupce, které se přidají do této tabulky pro výstup modelu. Výchozí předponou pro názvy sloupců je název modelu. Funkce Apply může obsahovat více parametrů specifických pro typ modelu.
Použití modelu ML vytvoří dvě nové tabulky toku dat, které obsahují předpovědi a individualizované vysvětlení pro každý řádek, který v tabulce výstupu skóre. Pokud například použijete model PurchaseIntent na tabulku OnlineShoppers , výstup vygeneruje rozšířené tabulky vysvětlení PurchaseIntent a OnlineShoppers rozšířené tabulky vysvětlení PurchaseIntent. Pro každý řádek v rozšířené tabulce se vysvětlení rozdělí do několika řádků v tabulce rozšířeného vysvětlení na základě vstupní funkce. An ExplanationIndex pomáhá mapovat řádky z rozšířené tabulky vysvětlení na řádek v rozšířené tabulce.
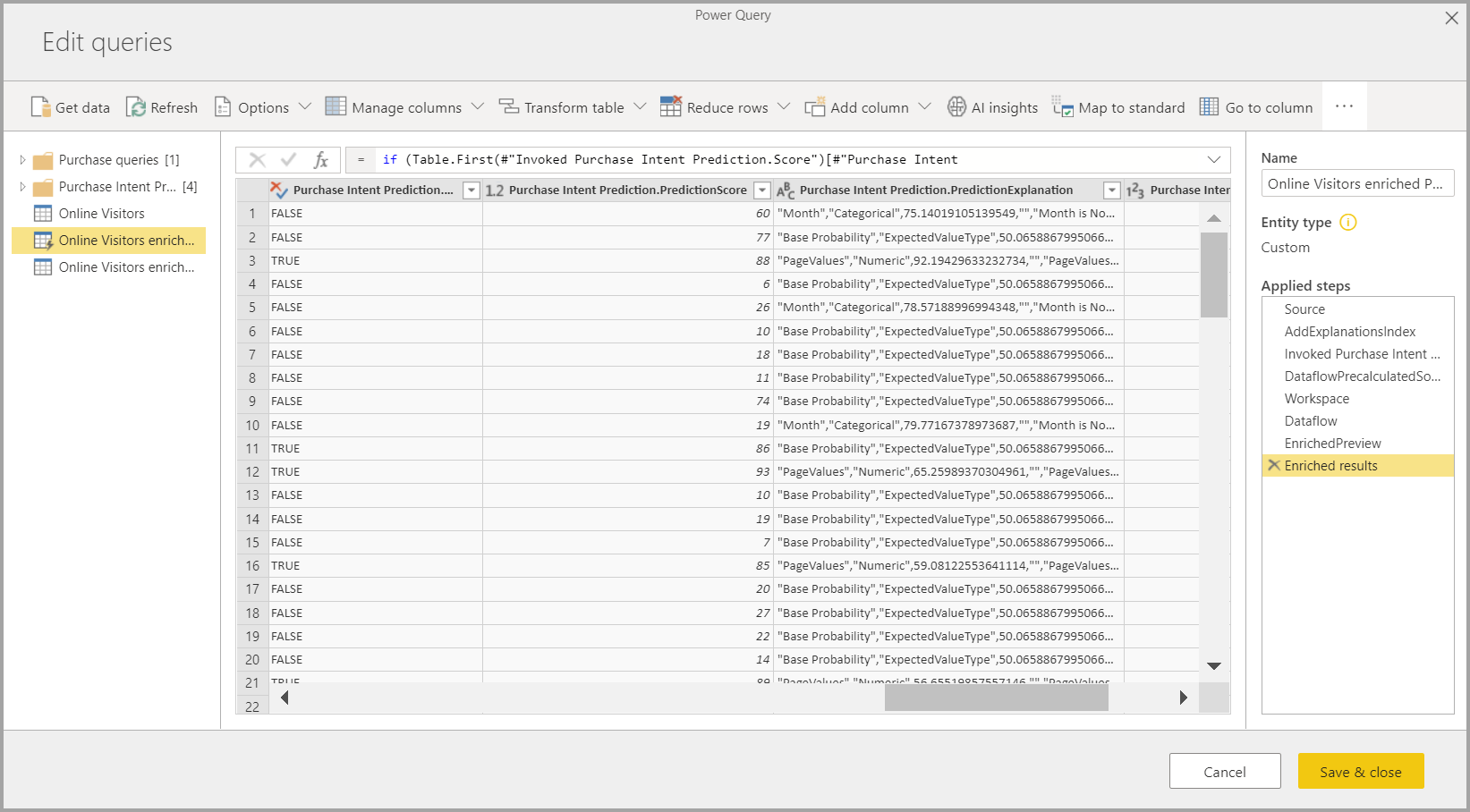
Libovolný model Power BI AutoML můžete použít také u tabulek v libovolném toku dat ve stejném pracovním prostoru pomocí Přehledy AI v prohlížeči funkcí PQO. Tímto způsobem můžete použít modely vytvořené ostatními ve stejném pracovním prostoru, aniž byste museli být vlastníkem toku dat, který má model. Power Query zjistí všechny modely Power BI ML v pracovním prostoru a zpřístupní je jako dynamické funkce Power Query. Tyto funkce můžete vyvolat tak, že k nim přistupujete z pásu karet v Editor Power Query nebo přímo vyvoláním funkce M. Tato funkce se v současné době podporuje jenom pro toky dat Power BI a pro Power Query Online v služba Power BI. Tento proces se liší od použití modelů ML v rámci toku dat pomocí průvodce AutoML. Pomocí této metody se nevytvořila žádná tabulka vysvětlení. Pokud nejste vlastníkem toku dat, nemůžete získat přístup k trénovacím sestavám modelu ani model znovu vytrénovat. Pokud je zdrojový model upraven přidáním nebo odebráním vstupních sloupců nebo odstraněním toku dat modelu nebo zdroje dat, tento závislý tok dat by se přerušil.
Jakmile model použijete, AutoML vždy udržuje predikce aktuální, kdykoli se tok dat aktualizuje.
Pokud chcete použít přehledy a předpovědi z modelu ML v sestavě Power BI, můžete se připojit k výstupní tabulce z Power BI Desktopu pomocí konektoru toků dat.
Binární prediktivní modely
Binární prediktivní modely, formálně označované jako binární klasifikační modely, se používají ke klasifikaci sémantického modelu do dvou skupin. Používají se k predikci událostí, které můžou mít binární výsledek. Například zda prodejní příležitost bude převedena, zda účet bude četnost změn, zda faktura bude zaplacena včas, zda transakce je podvodná atd.
Výstupem modelu binární předpovědi je skóre pravděpodobnosti, které identifikuje pravděpodobnost, že bude dosaženo cílového výsledku.
Trénování modelu binární předpovědi
Požadavky:
- Pro každou třídu výsledků se vyžaduje minimálně 20 řádků historických dat.
Proces vytvoření binárního prediktivního modelu se řídí stejným postupem jako u jiných modelů AutoML popsaných v předchozí části Konfigurace vstupů modelu ML. Jediným rozdílem je v kroku Zvolit model , kde můžete vybrat cílovou hodnotu výsledku, kterou vás nejvíce zajímá. Můžete také poskytnout popisky výsledků, které se mají použít v automaticky generované sestavě, která shrnuje výsledky ověření modelu.
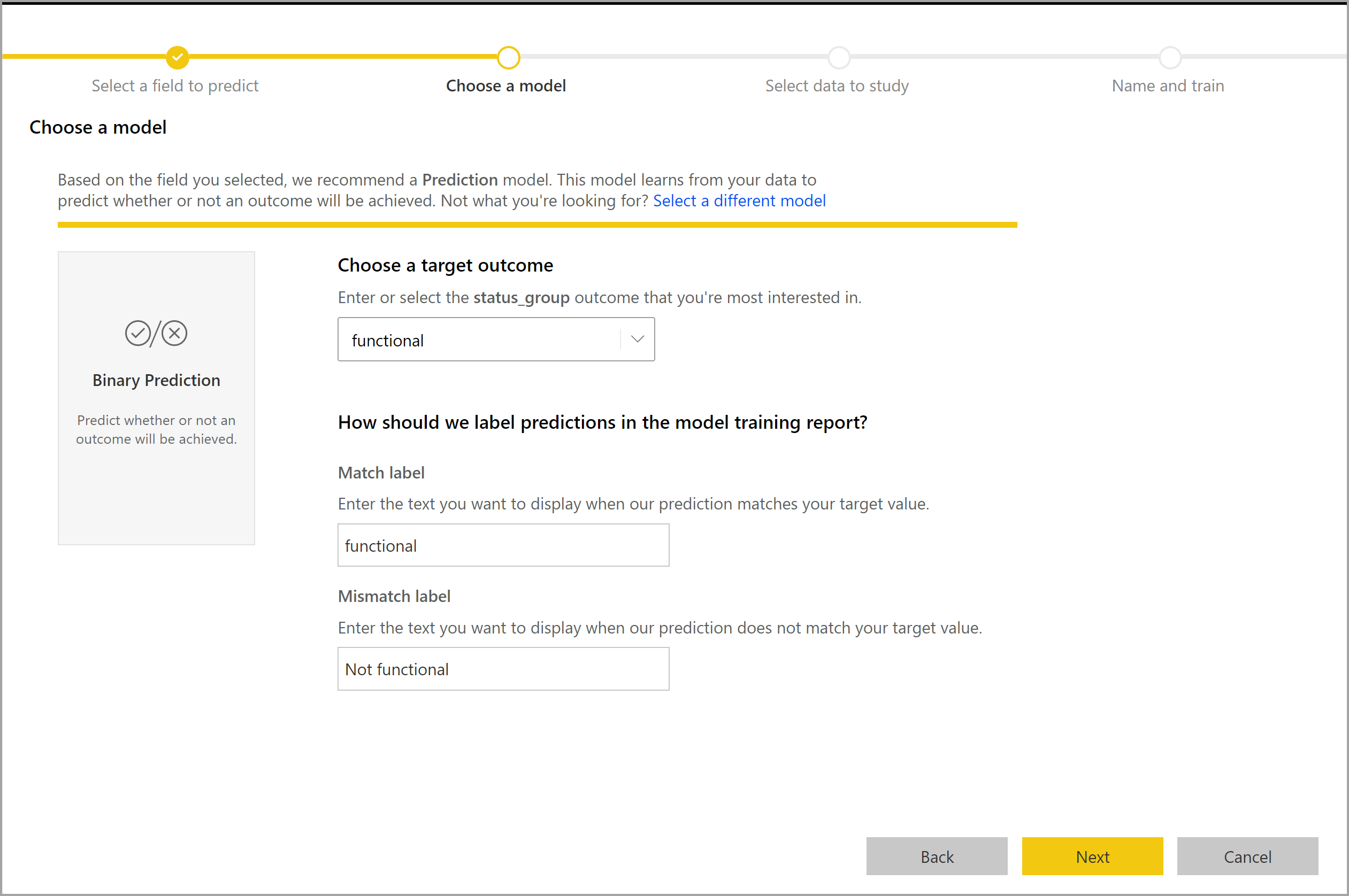
Sestava binárního prediktivního modelu
Model binární předpovědi vytvoří jako výstup pravděpodobnost, že řádek dosáhne cílového výsledku. Sestava obsahuje průřez prahové hodnoty pravděpodobnosti, který ovlivňuje, jak se interpretují skóre větší a menší než prahová hodnota pravděpodobnosti.
Sestava popisuje výkon modelu z hlediska pravdivě pozitivních výsledků, falešně pozitivních výsledků, pravdivě negativních výsledků a falešně negativních výsledků. Pravdivě pozitivní a pravdivě negativní výsledky jsou správně predikované výsledky pro dvě třídy v datech výsledku. Falešně pozitivní výsledky jsou řádky, které byly předpovězeny tak, aby měly cílový výsledek, ale ve skutečnosti ne. Naopak falešně negativní hodnoty jsou řádky, které měly cílové výsledky, ale byly předpovězeny jako ne.
Míry, jako je přesnost a úplnost, popisují účinek prahové hodnoty pravděpodobnosti na predikované výsledky. Průřez prahové hodnoty pravděpodobnosti můžete použít k výběru prahové hodnoty, která dosahuje vyváženého kompromisu mezi přesností a úplností.

Sestava obsahuje také nástroj pro analýzu nákladů a přínosů, který pomáhá identifikovat podmnožinu populace, která by měla být zaměřena na dosažení nejvyššího zisku. Při odhadovaných jednotkových nákladech na cílení a výhodu jednotky z dosažení cílového výsledku se analýza nákladů a přínosů pokusí maximalizovat zisk. Tento nástroj můžete použít k výběru prahové hodnoty pravděpodobnosti na základě maximálního bodu v grafu za účelem maximalizace zisku. Graf můžete použít také k výpočtu zisku nebo nákladů pro vaši volbu prahové hodnoty pravděpodobnosti.
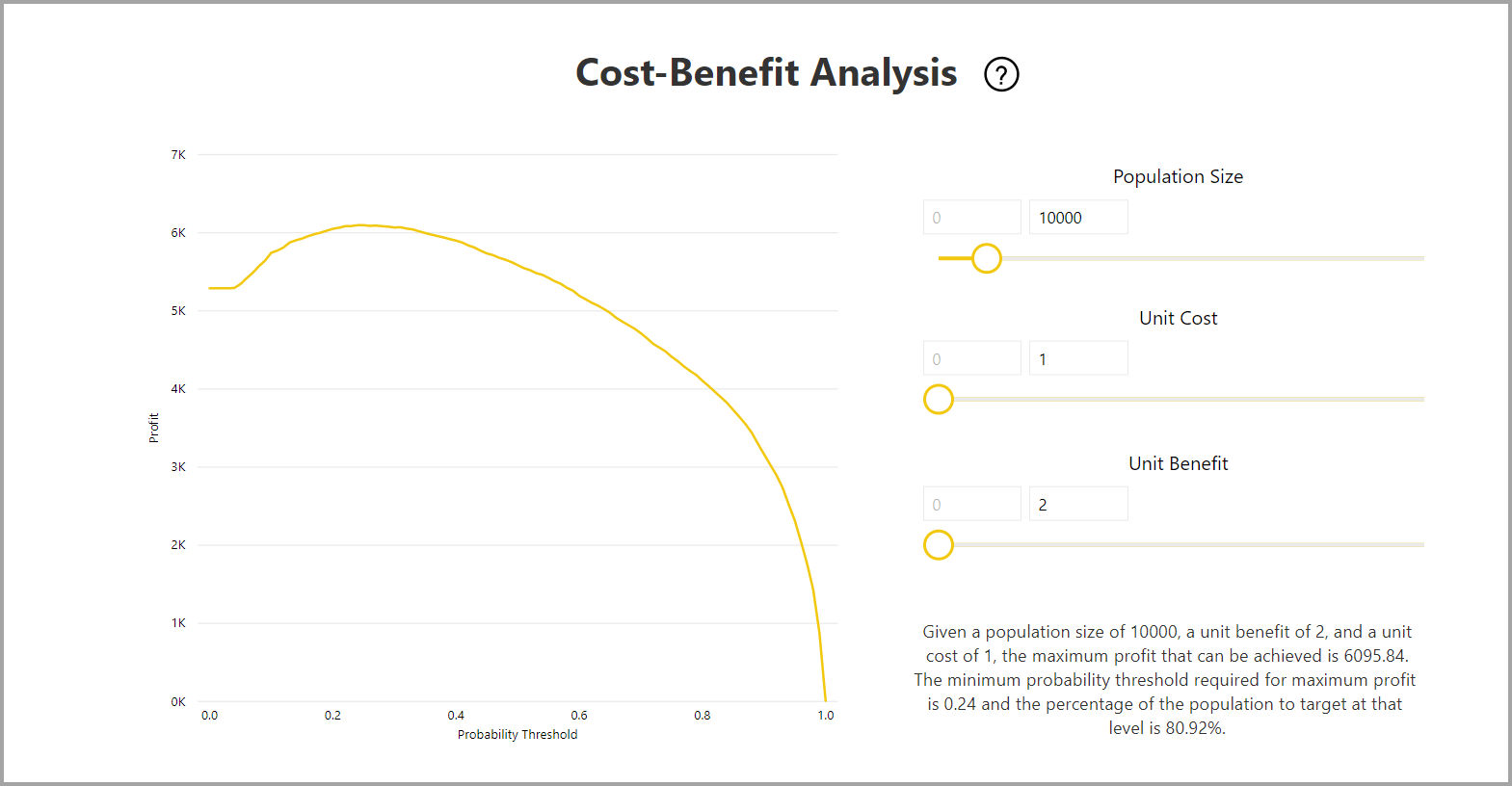
Stránka Sestava přesnosti sestavy modelu obsahuje graf Kumulativní zisky a křivku ROC modelu. Tato data poskytují statistické míry výkonu modelu. Sestavy obsahují popisy zobrazených grafů.

Použití modelu binární předpovědi
Chcete-li použít model binární předpovědi, je nutné zadat tabulku s daty, u kterých chcete použít předpovědi z modelu ML. Mezi další parametry patří předpona názvu výstupního sloupce a prahová hodnota pravděpodobnosti pro klasifikaci předpovězeného výsledku.
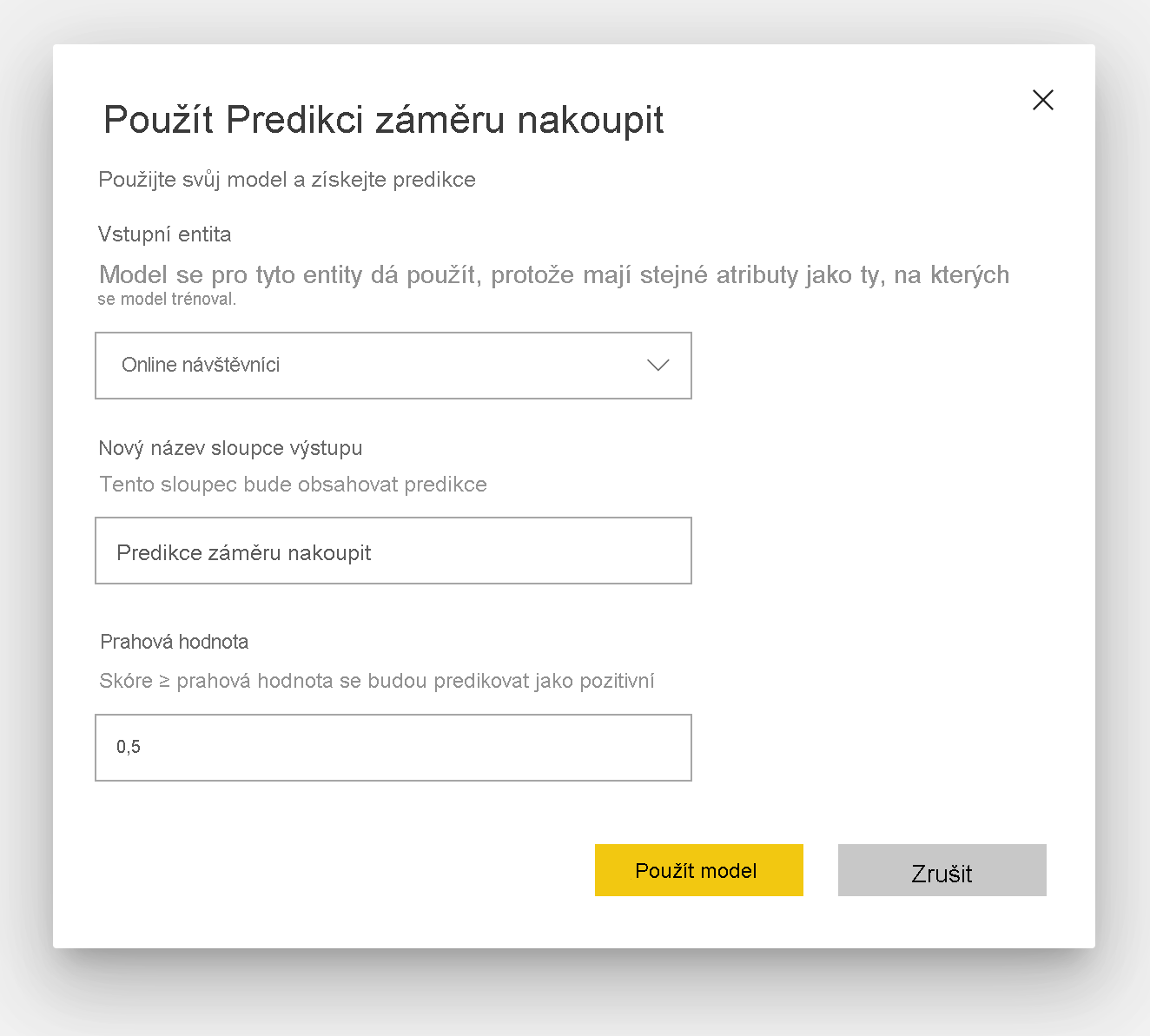
Při použití modelu binární předpovědi přidá do rozšířené výstupní tabulky čtyři výstupní sloupce: Outcome, PredictionScore, PredictionExplanation a ExplanationIndex. Názvy sloupců v tabulce mají předponu zadanou při použití modelu.
PredictionScore je procentuální pravděpodobnost, která identifikuje pravděpodobnost, že se dosáhne cílového výsledku.
Sloupec Výsledek obsahuje popisek předpovězeného výsledku. Záznamy s pravděpodobnostmi překračujícími prahovou hodnotu se předpovídají tak pravděpodobné, že dosáhne cílového výsledku a označí se jako True. Záznamy menší než prahová hodnota jsou předpovězeny tak, že pravděpodobně nedosáhne výsledku a jsou označeny jako False.
Sloupec PredictionExplanation obsahuje vysvětlení s konkrétním vlivem, který vstupní funkce měly na PredictionScore.
Modely klasifikace
Klasifikační modely se používají ke klasifikaci sémantického modelu do více skupin nebo tříd. Používají se k predikci událostí, které můžou mít jeden z více možných výsledků. Například jestli má zákazník pravděpodobně vysokou, střední nebo nízkou hodnotu životnosti. Můžou také předpovědět, jestli je riziko výchozího nastavení vysoké, střední, nízké atd.
Výstup klasifikačního modelu je skóre pravděpodobnosti, které identifikuje pravděpodobnost, že řádek dosáhne kritérií pro danou třídu.
Trénování klasifikačního modelu
Vstupní tabulka obsahující trénovací data pro klasifikační model musí mít jako sloupec výsledku řetězec nebo celý číselný sloupec, který identifikuje minulé známé výsledky.
Požadavky:
- Pro každou třídu výsledků se vyžaduje minimálně 20 řádků historických dat.
Proces vytvoření klasifikačního modelu se řídí stejným postupem jako jiné modely AutoML popsané v předchozí části Konfigurace vstupů modelu ML.
Sestava klasifikačního modelu
Power BI vytvoří sestavu klasifikačního modelu použitím modelu ML na testovací data blokování. Potom porovná předpovězenou třídu pro řádek se skutečnou známou třídou.
Sestava modelu obsahuje graf, který obsahuje rozpis správně a nesprávně klasifikovaných řádků pro každou známou třídu.
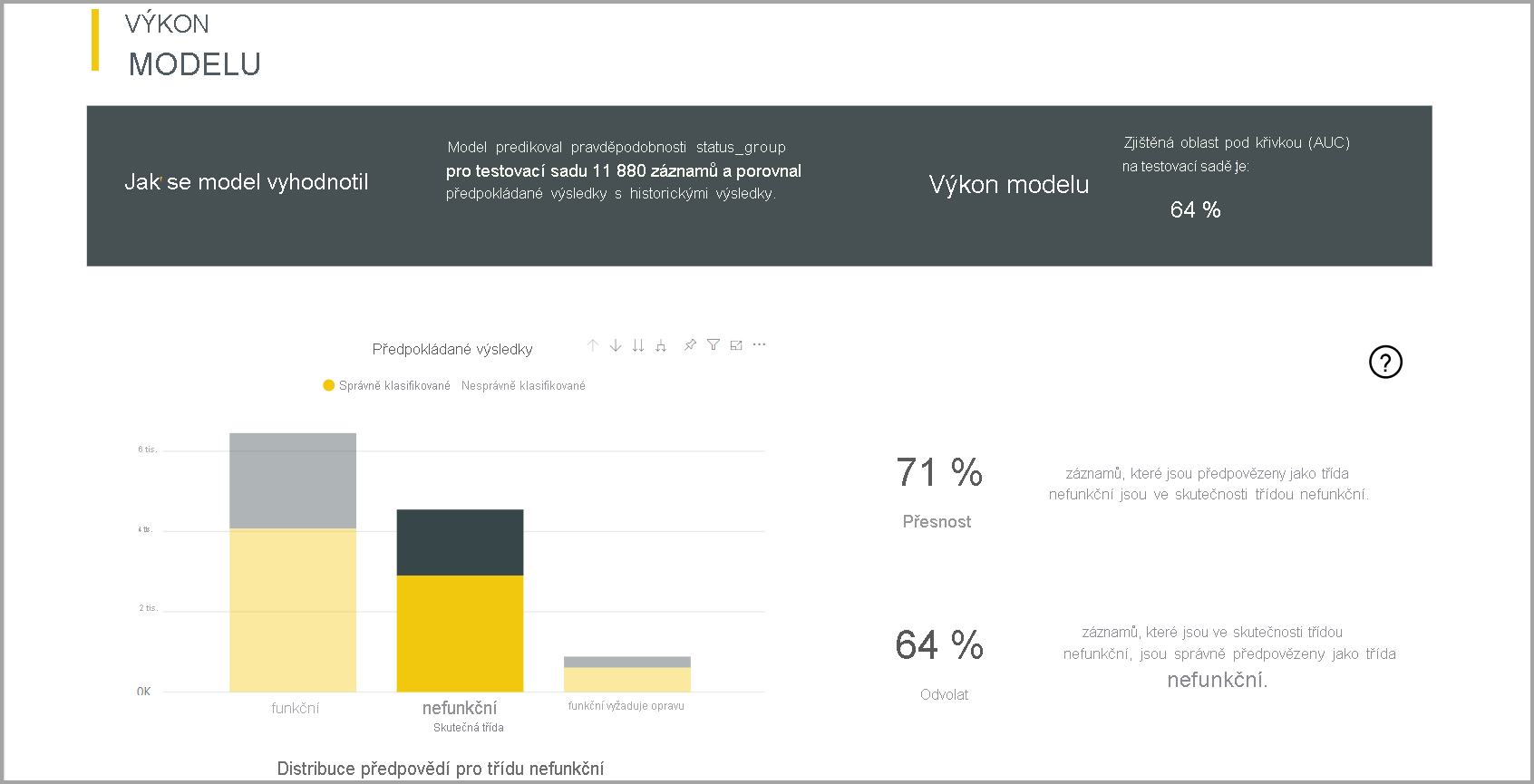
Další akce přechodu k podrobnostem specifická pro jednotlivé třídy umožňuje analýzu způsobu distribuce předpovědí pro známou třídu. Tato analýza ukazuje další třídy, ve kterých jsou řádky této známé třídy pravděpodobně chybně klasifikované.
Vysvětlení modelu v sestavě zahrnuje také hlavní prediktory pro každou třídu.
Sestava klasifikačního modelu obsahuje také stránku s podrobnostmi trénování, která se podobá stránkám jiných typů modelů, jak je popsáno výše v sestavě modelu AutoML.
Použití klasifikačního modelu
Pokud chcete použít klasifikační model ML, musíte zadat tabulku se vstupními daty a předponou názvu výstupního sloupce.
Při použití klasifikačního modelu přidá do rozšířené výstupní tabulky pět výstupních sloupců: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities a ExplanationIndex. Názvy sloupců v tabulce mají předponu zadanou při použití modelu.
Sloupec ClassProbabilities obsahuje seznam skóre pravděpodobnosti pro řádek pro každou možnou třídu.
ClassificationScore je procentuální pravděpodobnost, která identifikuje pravděpodobnost, že řádek dosáhne kritérií pro danou třídu.
Sloupec ClassificationResult obsahuje nejpravděpodobnější predikovanou třídu řádku.
Sloupec ClassificationExplanation obsahuje vysvětlení s konkrétním vlivem, který vstupní funkce měly na ClassificationScore.
Regresní modely
Regresní modely se používají k predikci číselné hodnoty a lze ji použít ve scénářích, jako je určení:
- Výnosy pravděpodobně budou realizovány z prodejní dohody.
- Hodnota životnosti účtu.
- Částka pohledávkové faktury, která bude pravděpodobně zaplacena
- Datum, kdy může být faktura zaplacena atd.
Výstupem regresního modelu je predikovaná hodnota.
Trénování regresního modelu
Vstupní tabulka obsahující trénovací data pro regresní model musí mít jako sloupec výsledku číselný sloupec, který identifikuje známé hodnoty výsledku.
Požadavky:
- Pro regresní model se vyžaduje minimálně 100 řádků historických dat.
Proces vytvoření regresního modelu se řídí stejným postupem jako u ostatních modelů AutoML popsaných v předchozí části Konfigurace vstupů modelu ML.
Sestava regresního modelu
Stejně jako ostatní sestavy modelu AutoML je regresní sestava založená na výsledcích použití modelu na data testu blokování.
Sestava modelu obsahuje graf, který porovnává predikované hodnoty se skutečnými hodnotami. V tomto grafu vzdálenost od úhlopříčky označuje chybu v predikci.
Graf zbytkových chyb zobrazuje rozdělení procenta průměrné chyby pro různé hodnoty v sémantickém modelu testu blokování. Vodorovná osa představuje střední hodnotu skutečné hodnoty pro skupinu. Velikost bubliny zobrazuje frekvenci nebo počet hodnot v daném rozsahu. Svislá osa je průměrná reziduální chyba.
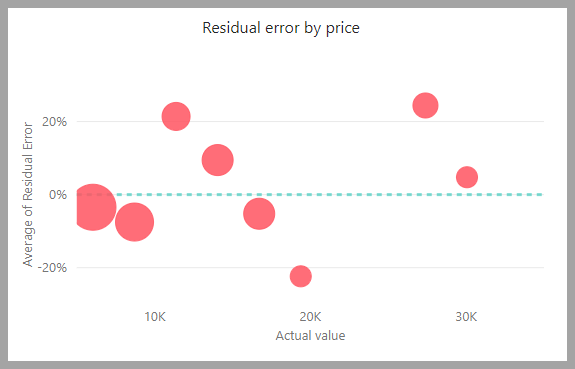
Sestava regresního modelu obsahuje také stránku s podrobnostmi trénování, jako jsou sestavy pro jiné typy modelů, jak je popsáno v předchozí části Sestava modelu AutoML.
Použití regresního modelu
Pokud chcete použít regresní model ML, musíte zadat tabulku se vstupními daty a předponou názvu výstupního sloupce.
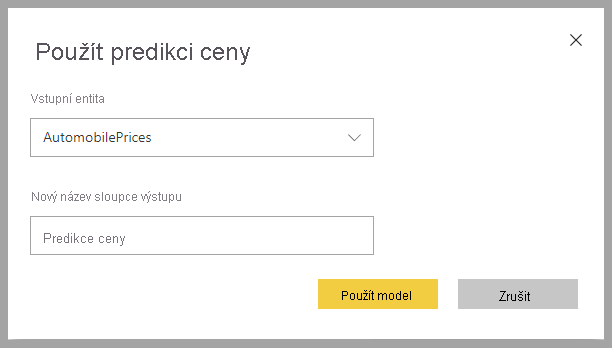
Při použití regresního modelu přidá do rozšířené výstupní tabulky tři výstupní sloupce: RegressionResult, RegressionExplanation a ExplanationIndex. Názvy sloupců v tabulce mají předponu zadanou při použití modelu.
Sloupec RegressionResult obsahuje predikovanou hodnotu řádku na základě vstupních sloupců. Sloupec RegressionExplanation obsahuje vysvětlení s konkrétním vlivem, že vstupní funkce měly na RegressionResult.
Integrace služby Azure Machine Učení v Power BI
Řada organizací používá modely strojového učení k lepšímu přehledu a předpovědím o své firmě. Tyto přehledy můžete získat pomocí strojového učení se sestavami, řídicími panely a dalšími analýzami. Schopnost vizualizovat a vyvolat přehledy z těchto modelů může pomoct rozšířit tyto přehledy podnikovým uživatelům, kteří je potřebují nejvíce. Power BI teď umožňuje jednoduše začlenit přehledy z modelů hostovaných na Učení Azure Machine pomocí jednoduchých gest typu point-and-click.
Pokud chcete tuto funkci použít, může datový vědec udělit přístup k modelu azure Machine Učení analytikům BI pomocí webu Azure Portal. Na začátku každé relace Pak Power Query zjistí všechny modely azure machine Učení, ke kterým má uživatel přístup, a zpřístupní je jako dynamické funkce Power Query. Uživatel pak může tyto funkce vyvolat tak, že k nim přistupuje z pásu karet v Editor Power Query nebo přímo vyvoláním funkce M. Power BI také automaticky dávková žádosti o přístup při vyvolání modelu azure Machine Učení pro sadu řádků, aby dosáhla lepšího výkonu.
Tato funkce se v současné době podporuje jenom pro toky dat Power BI a pro Power Query online v služba Power BI.
Další informace o tocích dat najdete v tématu Úvod k tokům dat a samoobslužné přípravě dat.
Další informace o službě Azure Machine Učení najdete tady:
- Přehled: Co je Azure Machine Učení?
- Rychlé starty a kurzy pro službu Azure Machine Učení: Dokumentace ke službě Azure Machine Učení
Udělení přístupu k modelu Azure Machine Učení uživateli Power BI
Aby mohl uživatel přistupovat k modelu Učení Azure Machine Učení z Power BI, musí mít přístup pro čtení k předplatnému Azure a pracovnímu prostoru Učení počítače.
Kroky v tomto článku popisují, jak uživateli Power BI udělit přístup k modelu hostovaného ve službě Azure Machine Učení pro přístup k tomuto modelu jako funkci Power Query. Další informace viz Přiřazení rolí Azure pomocí webu Azure Portal.
Přihlaste se k portálu Azure.
Přejděte na stránku Předplatná . Stránku Předplatná najdete v seznamu Všechny služby v nabídce navigačního podokna webu Azure Portal.

Vyberte své předplatné.
Vyberte Řízení přístupu (IAM) a pak zvolte tlačítko Přidat .
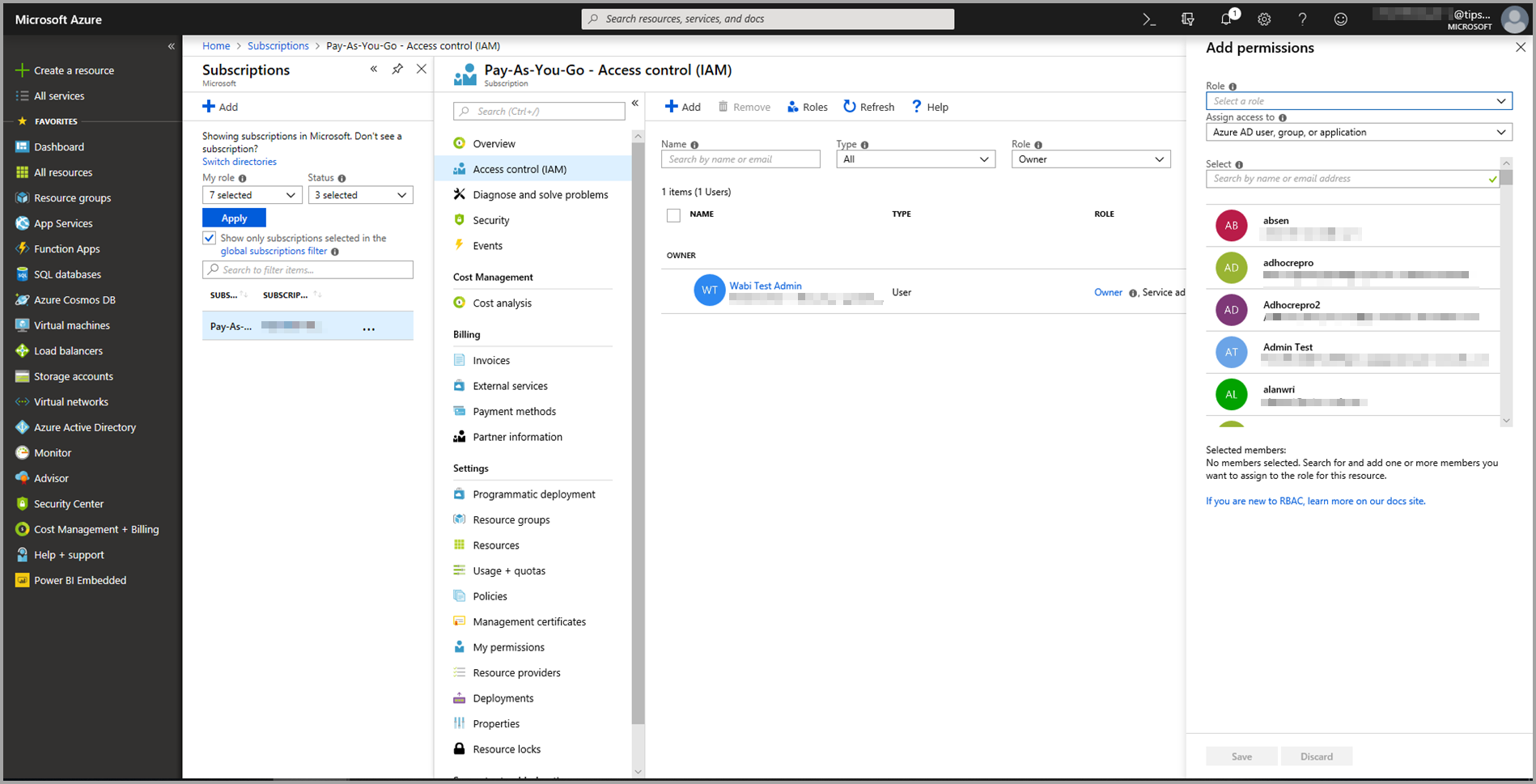
Jako roli vyberte čtenáře . Pak zvolte uživatele Power BI, kterému chcete udělit přístup k modelu Učení Azure Machine.

Zvolte Uložit.
Opakováním kroků 3 až šesti udělte uživateli přístup čtenáře pro konkrétní pracovní prostor strojového učení, který je hostitelem modelu.




Zjišťování schémat pro modely strojového učení
Datoví vědci primárně používají Python k vývoji a nasazení svých modelů strojového učení pro strojové učení. Datový vědec musí explicitně vygenerovat soubor schématu pomocí Pythonu.
Tento soubor schématu musí být součástí nasazené webové služby pro modely strojového učení. Pokud chcete automaticky vygenerovat schéma pro webovou službu, musíte zadat v vstupním skriptu pro nasazený model ukázku vstupu a výstupu. Další informace najdete v tématu Nasazení a určení skóre modelu strojového učení pomocí online koncového bodu. Odkaz obsahuje ukázkový vstupní skript s příkazy pro generování schématu.
Konkrétně funkce @input_schema a @output_schema ve vstupním skriptu odkazují na vstupní a výstupní ukázkové formáty v input_sample a output_sample proměnných. Tyto ukázky používají k vygenerování specifikace OpenAPI (Swagger) pro webovou službu během nasazování.
Tyto pokyny pro generování schématu aktualizací vstupního skriptu je nutné použít také u modelů vytvořených pomocí experimentů automatizovaného strojového učení se sadou Azure Machine Učení SDK.
Poznámka:
Modely vytvořené pomocí vizuálního rozhraní Azure Machine Učení v současné době nepodporují generování schématu, ale v dalších verzích.
Vyvolání modelu Azure Machine Učení v Power BI
Můžete vyvolat libovolný model Učení Azure, ke kterému máte udělený přístup, přímo z Editor Power Query v toku dat. Pokud chcete získat přístup k modelům Azure Machine Učení, vyberte tlačítko Upravit tabulku pro tabulku, kterou chcete rozšířit o přehledy z modelu Učení azure machine, jak je znázorněno na následujícím obrázku.

Výběrem tlačítka Upravit tabulku se otevře Editor Power Query pro tabulky v toku dat.

Na pásu karet vyberte tlačítko Přehledy AI a pak v nabídce navigačního podokna vyberte složku Azure Machine Učení Models. Všechny modely azure machine Učení, ke kterým máte přístup, jsou tady uvedené jako funkce Power Query. Vstupní parametry pro model Učení Azure Machine se také automaticky mapují jako parametry odpovídající funkce Power Query.
Pokud chcete vyvolat model Učení Azure Machine, můžete zadat libovolný ze sloupců vybrané tabulky jako vstup z rozevíracího seznamu. Můžete také zadat konstantní hodnotu, kterou chcete použít jako vstup přepnutím ikony sloupce nalevo od vstupního dialogového okna.

Výběrem možnosti Vyvolat zobrazíte náhled výstupu modelu Učení Azure jako nový sloupec v tabulce. Vyvolání modelu se zobrazí jako použitý krok dotazu.

Pokud model vrátí více výstupních parametrů, jsou seskupené jako řádek ve výstupním sloupci. Sloupec můžete rozbalit a vytvořit jednotlivé výstupní parametry v samostatných sloupcích.

Po uložení toku dat se model automaticky vyvolá při aktualizaci toku dat pro všechny nové nebo aktualizované řádky v tabulce.
Úvahy a omezení
- Toky dat Gen2 se v současné době neintegrují s automatizovaným strojovém učením.
- Přehledy AI (modely služeb Cognitive Services a Azure Machine Učení) se na počítačích s nastavením ověřování proxy nepodporují.
- Azure Machine Učení modely nejsou podporované pro uživatele typu host.
- Existují některé známé problémy s používáním brány s AutoML a Cognitive Services. Pokud potřebujete použít bránu, doporučujeme nejprve vytvořit tok dat, který importuje potřebná data přes bránu. Pak vytvořte další tok dat, který odkazuje na první tok dat a vytvoří nebo použije tyto modely a funkce AI.
- Pokud vaše práce s toky dat selže, možná budete muset povolit funkci Fast Combine při použití AI s toky dat. Po importu tabulky a před tím, než začnete přidávat funkce AI, vyberte na pásu karet Domů možnosti a v okně, které se zobrazí, zaškrtněte políčko Povolit kombinování dat z více zdrojů , abyste tuto funkci povolili, a pak výběrem ok výběr uložte. Potom můžete do toku dat přidat funkce AI.
Související obsah
Tento článek poskytuje přehled automatizovaných Učení počítačů pro toky dat v služba Power BI. Můžou být užitečné i následující články.
Následující články obsahují další informace o tocích dat a Power BI:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro