Copy data from the HDFS server using Azure Data Factory or Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to copy data from the Hadoop Distributed File System (HDFS) server. To learn more, read the introductory articles for Azure Data Factory and Synapse Analytics.
Supported capabilities
This HDFS connector is supported for the following capabilities:
| Supported capabilities | IR |
|---|---|
| Copy activity (source/-) | ① ② |
| Lookup activity | ① ② |
| Delete activity | ① ② |
① Azure integration runtime ② Self-hosted integration runtime
Specifically, the HDFS connector supports:
- Copying files by using Windows (Kerberos) or Anonymous authentication.
- Copying files by using the webhdfs protocol or built-in DistCp support.
- Copying files as is or by parsing or generating files with the supported file formats and compression codecs.
Prerequisites
If your data store is located inside an on-premises network, an Azure virtual network, or Amazon Virtual Private Cloud, you need to configure a self-hosted integration runtime to connect to it.
If your data store is a managed cloud data service, you can use the Azure Integration Runtime. If the access is restricted to IPs that are approved in the firewall rules, you can add Azure Integration Runtime IPs to the allow list.
You can also use the managed virtual network integration runtime feature in Azure Data Factory to access the on-premises network without installing and configuring a self-hosted integration runtime.
For more information about the network security mechanisms and options supported by Data Factory, see Data access strategies.
Note
Make sure that the integration runtime can access all the [name node server]:[name node port] and [data node servers]:[data node port] of the Hadoop cluster. The default [name node port] is 50070, and the default [data node port] is 50075.
Get started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create a linked service to HDFS using UI
Use the following steps to create a linked service to HDFS in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for HDFS and select the HDFS connector.
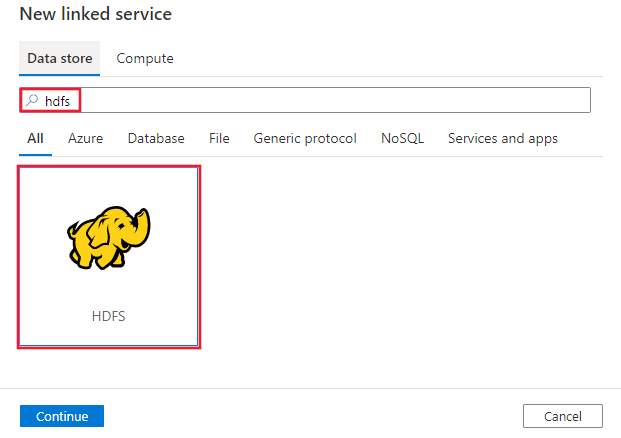
Configure the service details, test the connection, and create the new linked service.
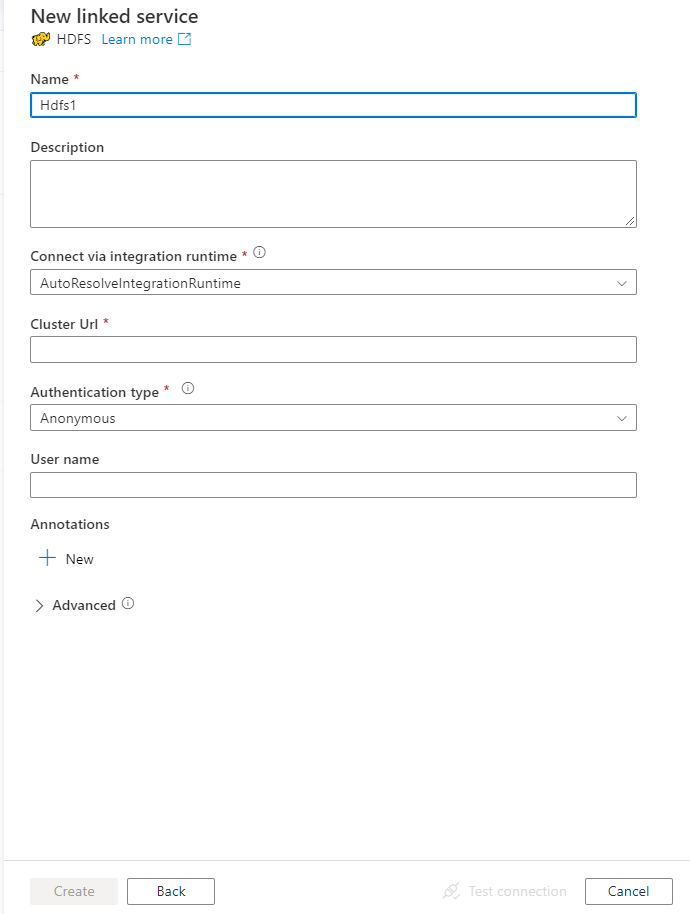

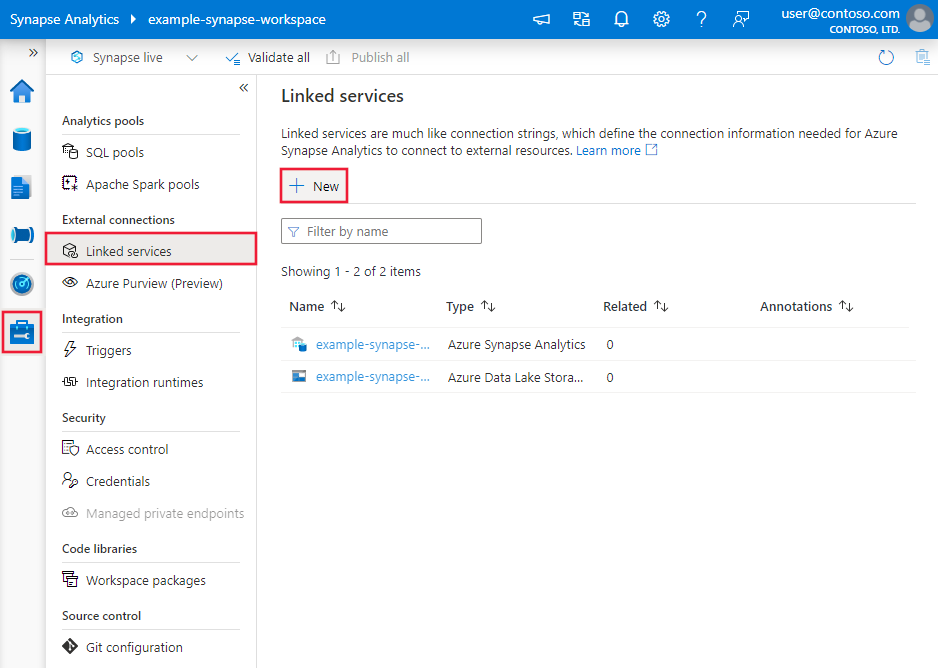
Connector configuration details
The following sections provide details about properties that are used to define Data Factory entities specific to HDFS.
Linked service properties
The following properties are supported for the HDFS linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to Hdfs. | Yes |
| url | The URL to the HDFS | Yes |
| authenticationType | The allowed values are Anonymous or Windows. To set up your on-premises environment, see the Use Kerberos authentication for the HDFS connector section. |
Yes |
| userName | The username for Windows authentication. For Kerberos authentication, specify <username>@<domain>.com. | Yes (for Windows authentication) |
| password | The password for Windows authentication. Mark this field as a SecureString to store it securely, or reference a secret stored in an Azure key vault. | Yes (for Windows Authentication) |
| connectVia | The integration runtime to be used to connect to the data store. To learn more, see the Prerequisites section. If the integration runtime isn't specified, the service uses the default Azure Integration Runtime. | No |
Example: using Anonymous authentication
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Anonymous",
"userName": "hadoop"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Example: using Windows authentication
{
"name": "HDFSLinkedService",
"properties": {
"type": "Hdfs",
"typeProperties": {
"url" : "http://<machine>:50070/webhdfs/v1/",
"authenticationType": "Windows",
"userName": "<username>@<domain>.com (for Kerberos auth)",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Dataset properties
For a full list of sections and properties that are available for defining datasets, see Datasets.
Azure Data Factory supports the following file formats. Refer to each article for format-based settings.
- Avro format
- Binary format
- Delimited text format
- Excel format
- JSON format
- ORC format
- Parquet format
- XML format
The following properties are supported for HDFS under location settings in the format-based dataset:
| Property | Description | Required |
|---|---|---|
| type | The type property under location in the dataset must be set to HdfsLocation. |
Yes |
| folderPath | The path to the folder. If you want to use a wildcard to filter the folder, skip this setting and specify the path in activity source settings. | No |
| fileName | The file name under the specified folderPath. If you want to use a wildcard to filter files, skip this setting and specify the file name in activity source settings. | No |
Example:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "HdfsLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Copy activity properties
For a full list of sections and properties that are available for defining activities, see Pipelines and activities. This section provides a list of properties that are supported by the HDFS source.
HDFS as source
Azure Data Factory supports the following file formats. Refer to each article for format-based settings.
- Avro format
- Binary format
- Delimited text format
- Excel format
- JSON format
- ORC format
- Parquet format
- XML format
The following properties are supported for HDFS under storeSettings settings in the format-based Copy source:
| Property | Description | Required |
|---|---|---|
| type | The type property under storeSettings must be set to HdfsReadSettings. |
Yes |
| Locate the files to copy | ||
| OPTION 1: static path |
Copy from the folder or file path that's specified in the dataset. If you want to copy all files from a folder, additionally specify wildcardFileName as *. |
|
| OPTION 2: wildcard - wildcardFolderPath |
The folder path with wildcard characters to filter source folders. Allowed wildcards are: * (matches zero or more characters) and ? (matches zero or single character). Use ^ to escape if your actual folder name has a wildcard or this escape character inside. For more examples, see Folder and file filter examples. |
No |
| OPTION 2: wildcard - wildcardFileName |
The file name with wildcard characters under the specified folderPath/wildcardFolderPath to filter source files. Allowed wildcards are: * (matches zero or more characters) and ? (matches zero or single character); use ^ to escape if your actual file name has a wildcard or this escape character inside. For more examples, see Folder and file filter examples. |
Yes |
| OPTION 3: a list of files - fileListPath |
Indicates to copy a specified file set. Point to a text file that includes a list of files you want to copy (one file per line, with the relative path to the path configured in the dataset). When you use this option, do not specify file name in the dataset. For more examples, see File list examples. |
No |
| Additional settings | ||
| recursive | Indicates whether the data is read recursively from the subfolders or only from the specified folder. When recursive is set to true and the sink is a file-based store, an empty folder or subfolder isn't copied or created at the sink. Allowed values are true (default) and false. This property doesn't apply when you configure fileListPath. |
No |
| deleteFilesAfterCompletion | Indicates whether the binary files will be deleted from source store after successfully moving to the destination store. The file deletion is per file, so when copy activity fails, you will see some files have already been copied to the destination and deleted from source, while others are still remaining on source store. This property is only valid in binary files copy scenario. The default value: false. |
No |
| modifiedDatetimeStart | Files are filtered based on the attribute Last Modified. The files are selected if their last modified time is greater than or equal to modifiedDatetimeStart and less than modifiedDatetimeEnd. The time is applied to the UTC time zone in the format of 2018-12-01T05:00:00Z. The properties can be NULL, which means that no file attribute filter is applied to the dataset. When modifiedDatetimeStart has a datetime value but modifiedDatetimeEnd is NULL, it means that the files whose last modified attribute is greater than or equal to the datetime value are selected. When modifiedDatetimeEnd has a datetime value but modifiedDatetimeStart is NULL, it means that the files whose last modified attribute is less than the datetime value are selected.This property doesn't apply when you configure fileListPath. |
No |
| modifiedDatetimeEnd | Same as above. | |
| enablePartitionDiscovery | For files that are partitioned, specify whether to parse the partitions from the file path and add them as additional source columns. Allowed values are false (default) and true. |
No |
| partitionRootPath | When partition discovery is enabled, specify the absolute root path in order to read partitioned folders as data columns. If it is not specified, by default, - When you use file path in dataset or list of files on source, partition root path is the path configured in dataset. - When you use wildcard folder filter, partition root path is the sub-path before the first wildcard. For example, assuming you configure the path in dataset as "root/folder/year=2020/month=08/day=27": - If you specify partition root path as "root/folder/year=2020", copy activity will generate two more columns month and day with value "08" and "27" respectively, in addition to the columns inside the files.- If partition root path is not specified, no extra column will be generated. |
No |
| maxConcurrentConnections | The upper limit of concurrent connections established to the data store during the activity run. Specify a value only when you want to limit concurrent connections. | No |
| DistCp settings | ||
| distcpSettings | The property group to use when you use HDFS DistCp. | No |
| resourceManagerEndpoint | The YARN (Yet Another Resource Negotiator) endpoint | Yes, if using DistCp |
| tempScriptPath | A folder path that's used to store the temp DistCp command script. The script file is generated and will be removed after the Copy job is finished. | Yes, if using DistCp |
| distcpOptions | Additional options provided to DistCp command. | No |
Example:
"activities":[
{
"name": "CopyFromHDFS",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "HdfsReadSettings",
"recursive": true,
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Folder and file filter examples
This section describes the resulting behavior if you use a wildcard filter with the folder path and file name.
| folderPath | fileName | recursive | Source folder structure and filter result (files in bold are retrieved) |
|---|---|---|---|
Folder* |
(empty, use default) | false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(empty, use default) | true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
File list examples
This section describes the behavior that results from using a file list path in the Copy activity source. It assumes that you have the following source folder structure and want to copy the files that are in bold type:
| Sample source structure | Content in FileListToCopy.txt | Configuration |
|---|---|---|
| root FolderA File1.csv File2.json Subfolder1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
In the dataset: - Folder path: root/FolderAIn the Copy activity source: - File list path: root/Metadata/FileListToCopy.txt The file list path points to a text file in the same data store that includes a list of files you want to copy (one file per line, with the relative path to the path configured in the dataset). |
Use DistCp to copy data from HDFS
DistCp is a Hadoop native command-line tool for doing a distributed copy in a Hadoop cluster. When you run a command in DistCp, it first lists all the files to be copied and then creates several Map jobs in the Hadoop cluster. Each Map job does a binary copy from the source to the sink.
The Copy activity supports using DistCp to copy files as is into Azure Blob storage (including staged copy) or an Azure data lake store. In this case, DistCp can take advantage of your cluster's power instead of running on the self-hosted integration runtime. Using DistCp provides better copy throughput, especially if your cluster is very powerful. Based on the configuration, the Copy activity automatically constructs a DistCp command, submits it to your Hadoop cluster, and monitors the copy status.
Prerequisites
To use DistCp to copy files as is from HDFS to Azure Blob storage (including staged copy) or the Azure data lake store, make sure that your Hadoop cluster meets the following requirements:
The MapReduce and YARN services are enabled.
YARN version is 2.5 or later.
The HDFS server is integrated with your target data store: Azure Blob storage or Azure Data Lake Store (ADLS Gen1):
- Azure Blob FileSystem is natively supported since Hadoop 2.7. You need only to specify the JAR path in the Hadoop environment configuration.
- Azure Data Lake Store FileSystem is packaged starting from Hadoop 3.0.0-alpha1. If your Hadoop cluster version is earlier than that version, you need to manually import Azure Data Lake Store-related JAR packages (azure-datalake-store.jar) into the cluster from here, and specify the JAR file path in the Hadoop environment configuration.
Prepare a temp folder in HDFS. This temp folder is used to store a DistCp shell script, so it will occupy KB-level space.
Make sure that the user account that's provided in the HDFS linked service has permission to:
- Submit an application in YARN.
- Create a subfolder and read/write files under the temp folder.
Configurations
For DistCp-related configurations and examples, go to the HDFS as source section.
Use Kerberos authentication for the HDFS connector
There are two options for setting up the on-premises environment to use Kerberos authentication for the HDFS connector. You can choose the one that better fits your situation.
- Option 1: Join a self-hosted integration runtime machine in the Kerberos realm
- Option 2: Enable mutual trust between the Windows domain and the Kerberos realm
For either option, make sure you turn on webhdfs for Hadoop cluster:
Create the HTTP principal and keytab for webhdfs.
Important
The HTTP Kerberos principal must start with "HTTP/" according to Kerberos HTTP SPNEGO specification. Learn more from here.
Kadmin> addprinc -randkey HTTP/<namenode hostname>@<REALM.COM> Kadmin> ktadd -k /etc/security/keytab/spnego.service.keytab HTTP/<namenode hostname>@<REALM.COM>HDFS configuration options: add the following three properties in
hdfs-site.xml.<property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.web.authentication.kerberos.principal</name> <value>HTTP/_HOST@<REALM.COM></value> </property> <property> <name>dfs.web.authentication.kerberos.keytab</name> <value>/etc/security/keytab/spnego.service.keytab</value> </property>
Option 1: Join a self-hosted integration runtime machine in the Kerberos realm
Requirements
- The self-hosted integration runtime machine needs to join the Kerberos realm and can’t join any Windows domain.
How to configure
On the KDC server:
Create a principal, and specify the password.
Important
The username should not contain the hostname.
Kadmin> addprinc <username>@<REALM.COM>
On the self-hosted integration runtime machine:
Run the Ksetup utility to configure the Kerberos Key Distribution Center (KDC) server and realm.
The machine must be configured as a member of a workgroup, because a Kerberos realm is different from a Windows domain. You can achieve this configuration by setting the Kerberos realm and adding a KDC server by running the following commands. Replace REALM.COM with your own realm name.
C:> Ksetup /setdomain REALM.COM C:> Ksetup /addkdc REALM.COM <your_kdc_server_address>After you run these commands, restart the machine.
Verify the configuration with the
Ksetupcommand. The output should be like:C:> Ksetup default realm = REALM.COM (external) REALM.com: kdc = <your_kdc_server_address>
In your data factory or Synapse workspace:
- Configure the HDFS connector by using Windows authentication together with your Kerberos principal name and password to connect to the HDFS data source. For configuration details, check the HDFS linked service properties section.
Option 2: Enable mutual trust between the Windows domain and the Kerberos realm
Requirements
- The self-hosted integration runtime machine must join a Windows domain.
- You need permission to update the domain controller's settings.
How to configure
Note
Replace REALM.COM and AD.COM in the following tutorial with your own realm name and domain controller.
On the KDC server:
Edit the KDC configuration in the krb5.conf file to let KDC trust the Windows domain by referring to the following configuration template. By default, the configuration is located at /etc/krb5.conf.
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = REALM.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] REALM.COM = { kdc = node.REALM.COM admin_server = node.REALM.COM } AD.COM = { kdc = windc.ad.com admin_server = windc.ad.com } [domain_realm] .REALM.COM = REALM.COM REALM.COM = REALM.COM .ad.com = AD.COM ad.com = AD.COM [capaths] AD.COM = { REALM.COM = . }After you configure the file, restart the KDC service.
Prepare a principal named krbtgt/REALM.COM@AD.COM in the KDC server with the following command:
Kadmin> addprinc krbtgt/REALM.COM@AD.COMIn the hadoop.security.auth_to_local HDFS service configuration file, add
RULE:[1:$1@$0](.*\@AD.COM)s/\@.*//.
On the domain controller:
Run the following
Ksetupcommands to add a realm entry:C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COMEstablish trust from the Windows domain to the Kerberos realm. [password] is the password for the principal krbtgt/REALM.COM@AD.COM.
C:> netdom trust REALM.COM /Domain: AD.COM /add /realm /password:[password]Select the encryption algorithm that's used in Kerberos.
a. Select Server Manager > Group Policy Management > Domain > Group Policy Objects > Default or Active Domain Policy, and then select Edit.
b. On the Group Policy Management Editor pane, select Computer Configuration > Policies > Windows Settings > Security Settings > Local Policies > Security Options, and then configure Network security: Configure Encryption types allowed for Kerberos.
c. Select the encryption algorithm you want to use when you connect to the KDC server. You can select all the options.
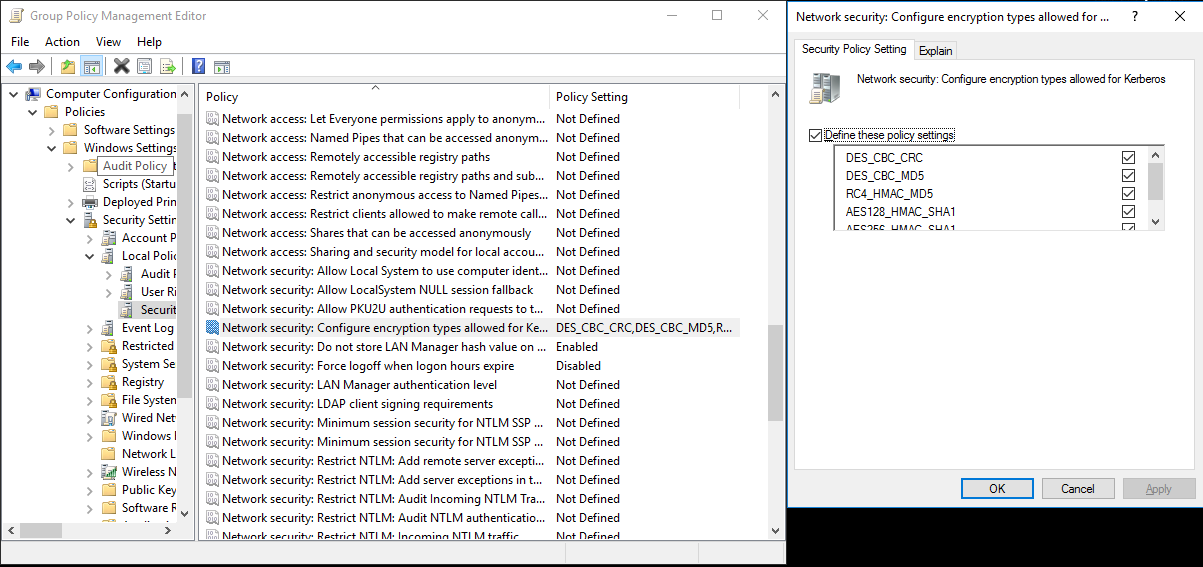
d. Use the
Ksetupcommand to specify the encryption algorithm to be used on the specified realm.C:> ksetup /SetEncTypeAttr REALM.COM DES-CBC-CRC DES-CBC-MD5 RC4-HMAC-MD5 AES128-CTS-HMAC-SHA1-96 AES256-CTS-HMAC-SHA1-96Create the mapping between the domain account and the Kerberos principal, so that you can use the Kerberos principal in the Windows domain.
a. Select Administrative tools > Active Directory Users and Computers.
b. Configure advanced features by selecting View > Advanced Features.
c. On the Advanced Features pane, right-click the account to which you want to create mappings and, on the Name Mappings pane, select the Kerberos Names tab.
d. Add a principal from the realm.
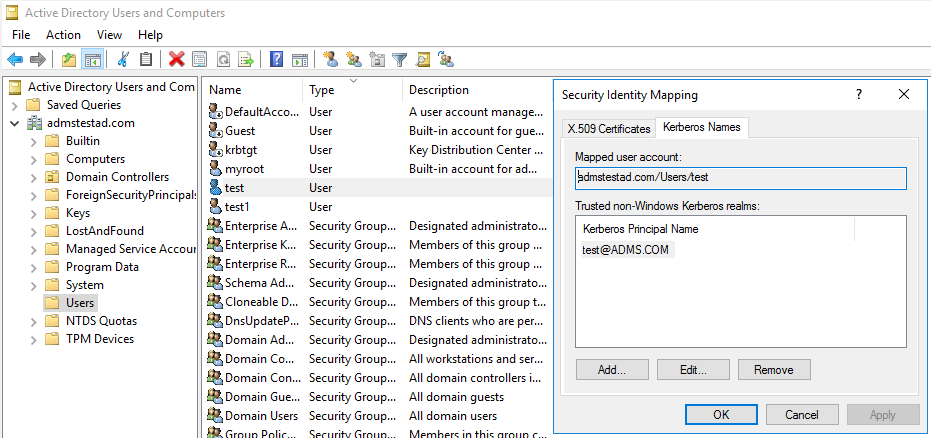
On the self-hosted integration runtime machine:
Run the following
Ksetupcommands to add a realm entry.C:> Ksetup /addkdc REALM.COM <your_kdc_server_address> C:> ksetup /addhosttorealmmap HDFS-service-FQDN REALM.COM
In your data factory or Synapse workspace:
- Configure the HDFS connector by using Windows authentication together with either your domain account or Kerberos principal to connect to the HDFS data source. For configuration details, see the HDFS linked service properties section.
Lookup activity properties
For information about Lookup activity properties, see Lookup activity.
Delete activity properties
For information about Delete activity properties, see Delete activity.
Legacy models
Note
The following models are still supported as is for backward compatibility. We recommend that you use the previously discussed new model, because the authoring UI has switched to generating the new model.
Legacy dataset model
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to FileShare | Yes |
| folderPath | The path to the folder. A wildcard filter is supported. Allowed wildcards are * (matches zero or more characters) and ? (matches zero or a single character); use ^ to escape if your actual file name has a wildcard or this escape character inside. Examples: rootfolder/subfolder/, see more examples in Folder and file filter examples. |
Yes |
| fileName | The name or wildcard filter for the files under the specified "folderPath". If you don't specify a value for this property, the dataset points to all files in the folder. For filter, allowed wildcards are * (matches zero or more characters) and ? (matches zero or a single character).- Example 1: "fileName": "*.csv"- Example 2: "fileName": "???20180427.txt"Use ^ to escape if your actual folder name has a wildcard or this escape character inside. |
No |
| modifiedDatetimeStart | Files are filtered based on the attribute Last Modified. The files are selected if their last modified time is greater than or equal to modifiedDatetimeStart and less than modifiedDatetimeEnd. The time is applied to the UTC time zone in the format 2018-12-01T05:00:00Z. Be aware that the overall performance of data movement will be affected by enabling this setting when you want to apply a file filter to large numbers of files. The properties can be NULL, which means that no file attribute filter is applied to the dataset. When modifiedDatetimeStart has a datetime value but modifiedDatetimeEnd is NULL, it means that the files whose last modified attribute is greater than or equal to the datetime value are selected. When modifiedDatetimeEnd has a datetime value but modifiedDatetimeStart is NULL, it means that the files whose last modified attribute is less than the datetime value are selected. |
No |
| modifiedDatetimeEnd | Files are filtered based on the attribute Last Modified. The files are selected if their last modified time is greater than or equal to modifiedDatetimeStart and less than modifiedDatetimeEnd. The time is applied to the UTC time zone in the format 2018-12-01T05:00:00Z. Be aware that the overall performance of data movement will be affected by enabling this setting when you want to apply a file filter to large numbers of files. The properties can be NULL, which means that no file attribute filter is applied to the dataset. When modifiedDatetimeStart has a datetime value but modifiedDatetimeEnd is NULL, it means that the files whose last modified attribute is greater than or equal to the datetime value are selected. When modifiedDatetimeEnd has a datetime value but modifiedDatetimeStart is NULL, it means that the files whose last modified attribute is less than the datetime value are selected. |
No |
| format | If you want to copy files as is between file-based stores (binary copy), skip the format section in both the input and output dataset definitions. If you want to parse files with a specific format, the following file format types are supported: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Set the type property under format to one of these values. For more information, see the Text format, JSON format, Avro format, ORC format, and Parquet format sections. |
No (only for binary copy scenario) |
| compression | Specify the type and level of compression for the data. For more information, see Supported file formats and compression codecs. Supported types are: Gzip, Deflate, Bzip2, and ZipDeflate. Supported levels are: Optimal and Fastest. |
No |
Tip
To copy all files under a folder, specify folderPath only.
To copy a single file with a specified name, specify folderPath with folder part and fileName with file name.
To copy a subset of files under a folder, specify folderPath with folder part and fileName with wildcard filter.
Example:
{
"name": "HDFSDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<HDFS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Legacy Copy activity source model
| Property | Description | Required |
|---|---|---|
| type | The type property of the Copy activity source must be set to HdfsSource. | Yes |
| recursive | Indicates whether the data is read recursively from the subfolders or only from the specified folder. When recursive is set to true and the sink is a file-based store, an empty folder or subfolder will not be copied or created at the sink. Allowed values are true (default) and false. |
No |
| distcpSettings | The property group when you're using HDFS DistCp. | No |
| resourceManagerEndpoint | The YARN Resource Manager endpoint | Yes, if using DistCp |
| tempScriptPath | A folder path that's used to store the temp DistCp command script. The script file is generated and will be removed after the Copy job is finished. | Yes, if using DistCp |
| distcpOptions | Additional options are provided to DistCp command. | No |
| maxConcurrentConnections | The upper limit of concurrent connections established to the data store during the activity run. Specify a value only when you want to limit concurrent connections. | No |
Example: HDFS source in Copy activity using DistCp
"source": {
"type": "HdfsSource",
"distcpSettings": {
"resourceManagerEndpoint": "resourcemanagerendpoint:8088",
"tempScriptPath": "/usr/hadoop/tempscript",
"distcpOptions": "-m 100"
}
}
Related content
For a list of data stores that are supported as sources and sinks by the Copy activity, see supported data stores.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for