Dataprodukter för analys i molnskala i Azure
Dataprodukter är data som hanteras som produkter och beräknas, sparas och hanteras av flerspråkiga beständighetstjänster, vilket kan krävas av vissa användningsfall. Processen för att skapa och betjäna en dataprodukt kan kräva tjänster och tekniker som inte ingår i kärntjänsterna i datalandningszonen . Ett exempel på detta är rapportering med nischkrav, till exempel efterlevnad och skatterapportering.
Designöverväganden
En datalandningszon kan betjänas med flera dataprodukter som skapats genom att mata in data från samma datalandningszon eller från flera datalandningszoner. Detta visas i följande diagram.
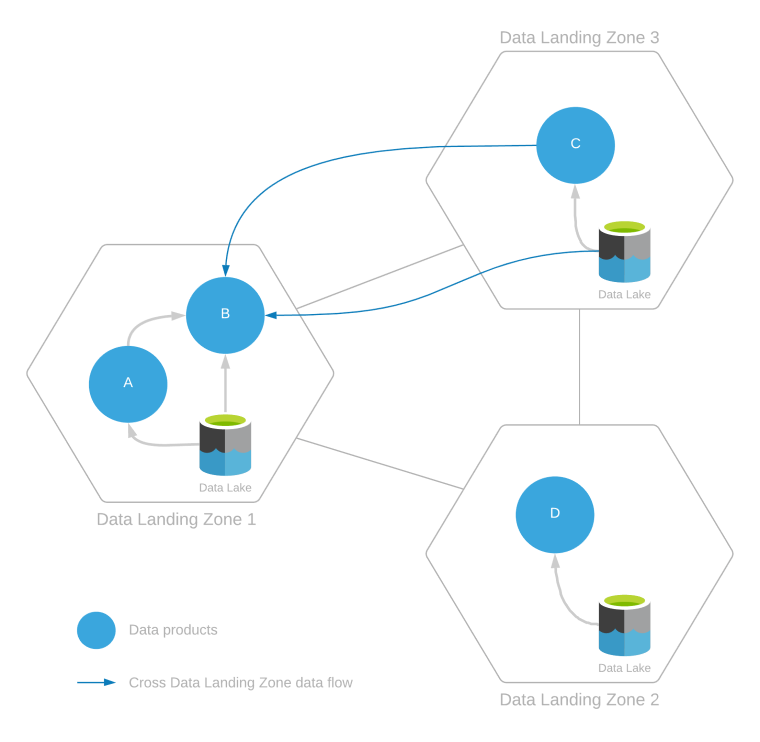
Exemplet ovan visar:
- Förbrukning av intrazondata:
- Dataprodukt B förbrukar data från dataprodukt A och andra data eller dataprodukter som finns i datasjön inom sin egen landningszon.
- Dataprodukterna C och D använder endast data från sina egna respektive datalandningszoner.
- Dataförbrukning mellan zoner:
- Dataprodukt B förbrukar också data från dataprodukt C och data i datasjön i landningszon 3.
Viktigt
När det gäller förbrukning av interzondata, eftersom dataprodukt B skapas genom läsning från datalandningszon 3, kräver den här läsåtkomsten godkännande från datalandningszonens drifts - och integreringsåtgärder i datalandningszon 3.
Viktigt
Dataprodukt B förbrukar data från dataprodukterna A och C. Innan detta kan inträffa måste dataprodukt B registrera sin förbrukning av dataprodukter via datadelningsavtal. Det här datadelningsavtalet bör uppdatera ursprunget från dataprodukt A till dataprodukt B och från dataprodukt C till dataprodukt B.
Resursgruppen för en dataprodukt innehåller alla tjänster som krävs för att skapa och underhålla den. Vi kan kalla den här resursgruppen för ett dataprogram. Exempel på tjänster som kan ingå i ett dataprogram är Azure Functions, Azure App Service, Logic Apps, Azure Analysis Services, Azure Cognitive Services, Azure Machine Learning, Azure SQL Database Azure Database for MySQLoch Azure Cosmos DB. Mer information finns i dataprogramexempel.
Dataprodukter har data från READ-datakällor som har tillämpat vissa datatransformeringar. Exempel kan vara en nyligen granskad datauppsättning eller en BI-rapport.
Designrekommendationer
Skapa dataprodukter i din datalandningszon genom att följa designprinciper som gör att du kan skala med datastyrning. Följande avsnitt innehåller designrekommendationer som hjälper dig när du planerar ditt dataprograms ekosystem.
Distribuera flera resursgrupper
Varje dataprogram är en resursgrupp. Eftersom dataprogram är beräkningstjänster, flerspråkiga beständighetstjänster eller båda kan de bara krävas beroende på vissa användningsfall. Därför anses de vara en valfri komponent för datalandningszoner. Om du behöver dataprogram kan du skapa flera resursgrupper efter dataprogram, vilket visas i följande diagram.

Ange skyddsräcken
Azure Policy styr standardkonfigurationen av tjänster i en datalandningszon. Tänk på driftanalys som flera resursgrupper som ditt dataproduktteam kan begära från en standardtjänstkatalog. Med hjälp av Azure Policy kan du konfigurera säkerhetsgränsen och den nödvändiga funktionsuppsättningen.
Viktigt
Konfigurera en Azure Policy för varje dataprogram för att skapa konsekvens.
Använda data från flera platser
Dataprogram hanterar, organiserar och förstår data från flera datatillgångar och visar alla insikter som vunnits. En dataprodukt är resultatet av data från ett eller flera dataprogram i datalandningszoner. Ge dina dataprogram åtkomst till data från flera och olika källor vid behov.
Skala efter behov
Tjänster som utgör dataprogram är inkrementella distributioner till datalandningszonen. Skala dina dataprogram efter behov.
Aktivera dataidentifiering
Registrera dina dataprodukter automatiskt i en datakatalog, till exempel Azure Purview , för att tillåta datagenomsökning.
Identifiera dina dataprodukter
När du börjar planera en datalandningszon kan du identifiera så många dataprodukter (och de dataprogram som matar ut och underhåller dem) efter behov för att hjälpa till att driva din dataproduktprogramarkitektur. Överensstämmelse med implementerad plattformsstyrning bör spela den största rollen i dina beslut.
Fokusera på hur dina dataprogram är dataproducenter och konsumenter för andra. Anta till exempel att du har identifierat en uppsättning dataprodukter (A, B, C och D) som produceras och används. Du behöver dataprodukterna A och D som källor för data i dataprogram B för dataprodukt B. Dataprodukt B skapas från de data som dataprogram B förbrukar från dataprodukterna A och D. Dataprogram B fungerar som själva dataproducenten och genererar även data för dataprodukt C.
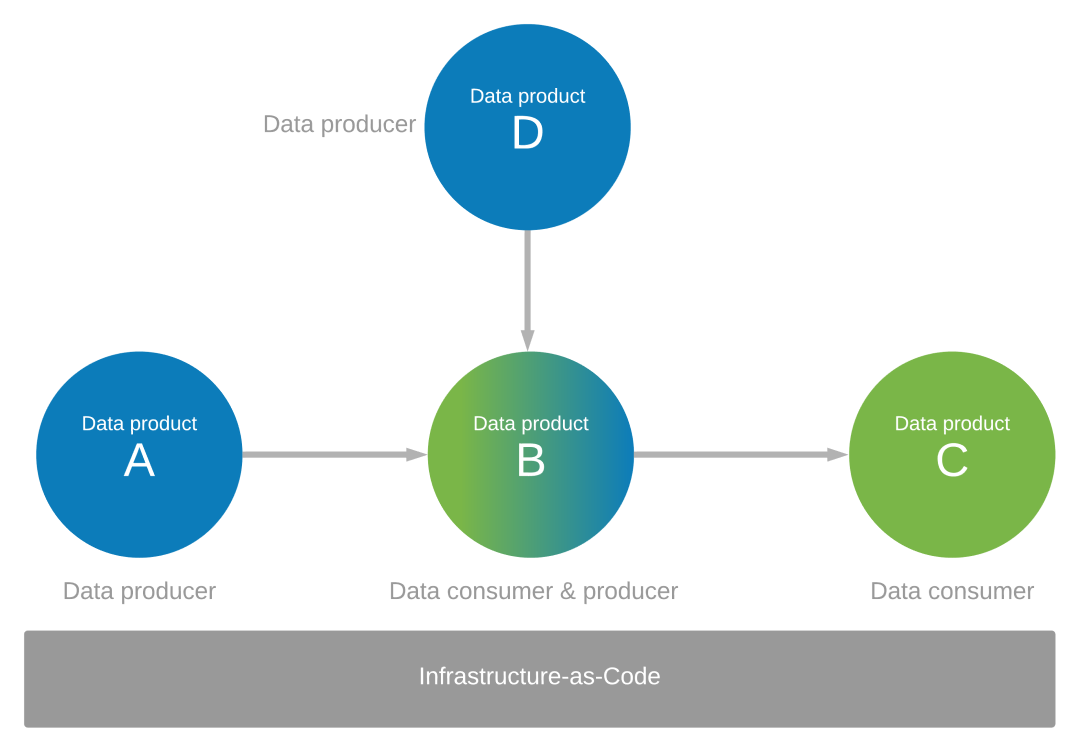
Kontrollera dataprogrammiljön med infrastruktur som kod
Styrning och infrastruktur som kod bör styra dataprogrammiljön i ekosystemet för dina dataprodukter, som du ser i föregående diagram.
Publicera datamodeller
Dina dataproduktteam bör publicera sina datamodeller på en modelllagringsplats.
Ange förväntningar för dataproduktanvändare
Uppdatera dina avtal för datadelning med serviceavtal och certifieringar för dina dataprodukter så att du kan förmedla korrekta förväntningar till potentiella användare av dataprodukten.
Avbilda ursprung
Om dataprodukt B skapas från data som kommer från dataprodukterna A och D måste ursprunget samlas in från A och D till B. Ytterligare ursprung bör också samlas in för dataprodukt C, eftersom den skapas med data från dataprodukt B. Uppdaterad härkomst bör samlas in i ett data härkomstprogram före varje utgåva av din dataprodukt.
Anteckning
Med Hjälp av Azure Pipelines kan du skapa godkännandegrindar och anropa funktioner som kan se till att metadata, ursprung och serviceavtal registreras i rätt styrningstjänst.
Definiera arkitektur för dataprogram
Du måste skapa en detaljerad arkitektur för varje dataprodukt som helt definierar dess relation till andra dataprodukter, dess beroenden och dess åtkomstkrav.
Exempel på designscenario
För att förstå arkitekturdefinitionsprocessen kan du utforska följande exempel på ett finansinstitut och dess kreditövervakningsdataprodukt.
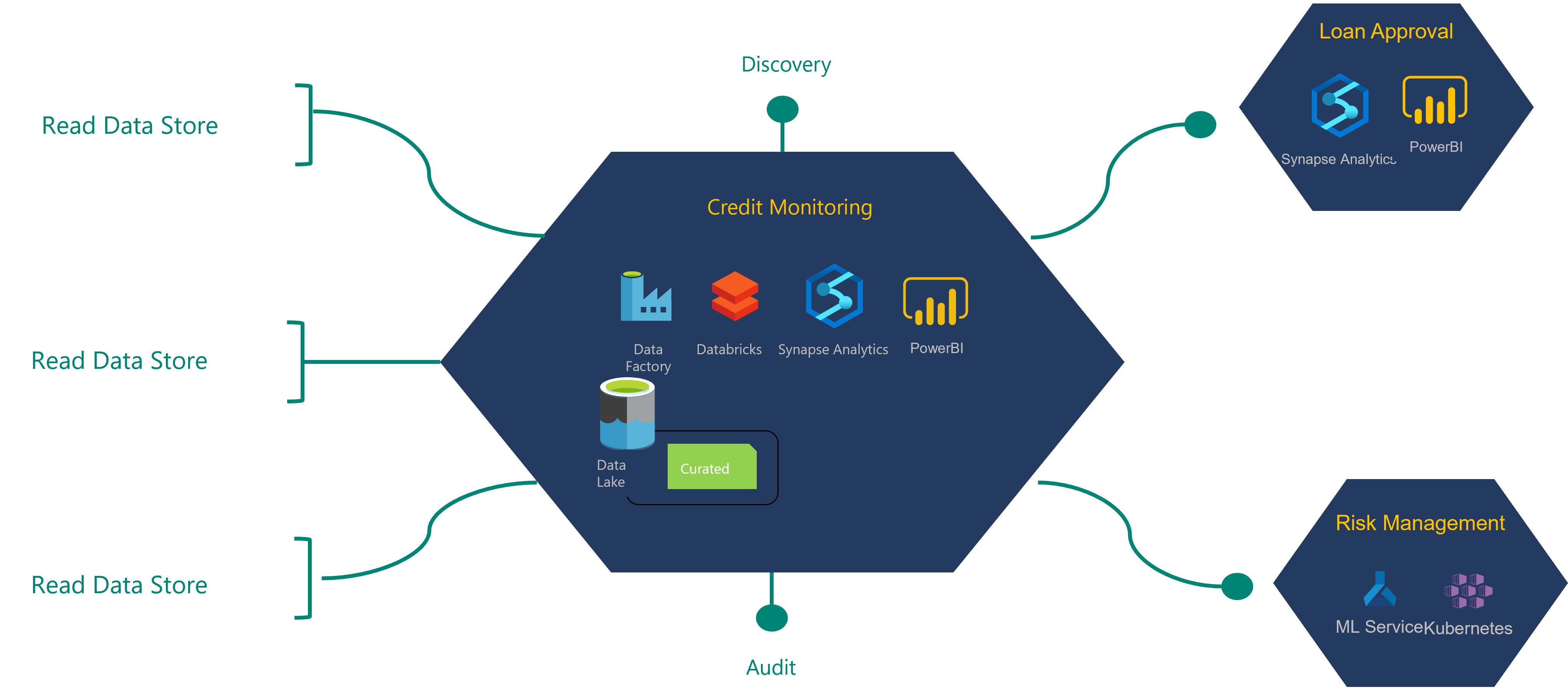
Kreditövervakningsdataprodukten som visas i det här diagrammet förbrukar data från ett läsdatalager som har matats in av integrationsåtgärderna. Den producerar dataprodukter som också används av två andra dataprodukter.
Anteckning
En läsdatakälla eller ett arkiv kallas även för en golden record-källa. Dessa datakällor har rensats men inga transformeringar har tillämpats på dem.
Produktteamet för kreditövervakningsdata begär läsåtkomst för att läsa datalager som de behöver för att skapa dataprodukter. Deras begäranden dirigeras till ägarna av data för godkännande. När de har fått godkännande kan produktteamet börja skapa sitt dataprogram.
Data från den lästa datakällan omvandlas till kreditövervakningsdataprodukterna. Alla nya dataprodukter lagras i datasjöns organiserade lager. Dessa nya dataprodukter och det nya data härstamningen bör registreras som en del av DevOps-distributionsprocessen. En funktion kan kontrollera registrerade metadata med datatillgångens fysiska struktur. Den bör registrera beroendet av datatillgångarna och dataprodukterna för läsdatakällan.
Produktteamet för godkännande av lån är beroende av några av kreditövervakningsdataprodukterna. De lånar godkännandeteamet kan begära läsåtkomst till de kreditövervakningsdataprodukter som de behöver för sina dataprodukter. När de släpper sin produkt för godkännande av lån och dess dataprogram bör alla dataprodukttillgångar, ursprung och modeller registreras i relevanta styrningstjänster.
Exempeldataprogram
Följande avsnitt innehåller exempeldataprogram för att ytterligare illustrera scenarier för dataprogram.
Dataanalys och data science-dataprogram
Ett program för dataanalys och datavetenskap kan innehålla de tjänster som visas i exempeldataprogrammet product-analytics-rg.

Anteckning
Dataprogrammet ovan är tillgängligt som en mall, som distribuerar en uppsättning tjänster som du kan använda för dataanalys och datavetenskap. Precis som alla våra mallar är den här dataproduktprogrammallen en skiss som du kan använda för att snabbt skapa miljöer för tvärfunktionella team. Alla tjänster som du inte behöver måste uttryckligen inaktiveras.
Dataproduktanalysmallen innehåller alla mallar för att distribuera en dataprodukt för analys och datavetenskap i en datalandningszon i molnskala.
Distributionen och kodartefakterna innehåller följande tjänster:
- Machine Learning
- Key Vault
- Application Insights
- Storage
- Container Registry
- Cognitive Services (valfritt)
- Data Factory (välj mellan Data Factory och Synapse)
- Synapse-arbetsyta (välj mellan Data Factory och Synapse)
- Azure Search (valfritt)
- SQL-pool (valfritt)
- BigData-pool (valfritt)
Batch-dataprogram
Batch Data Application-mallen innehåller alla mallar för att distribuera en dataprodukt för batchdatabearbetning i en datalandningszon för analysscenario i molnskala.
Distributionen och kodartefakterna innehåller följande tjänster:

- Key Vault
- Data Factory (välj mellan Data Factory och Synapse)
- Azure Cosmos DB (valfritt)
- Synapse-arbetsyta (välj mellan Data Factory och Synapse)
- MySQL-databas (valfritt)
- Azure SQL Database (valfritt)
- PostgreSQL-databas (valfritt)
- MariaDB-databas (valfritt)
- SQL-pool (valfritt)
- SQL Server (valfritt)
- Elastisk SQL-pool (valfritt)
- BigData-pool
Strömmande dataprogram
Mallen Strömmande dataprogram innehåller alla mallar för att distribuera en dataprodukt för databearbetning i realtid i en datalandningszon för analysscenario i molnskala
Distributionen och kodartefakterna innehåller följande tjänster:

- Key Vault
- Event Hubs
- IoT Hub
- Stream Analytics (valfritt)
- Azure Cosmos DB (valfritt)
- Synapse-arbetsyta
- Azure SQL Database (valfritt)
- SQL-pool (valfritt)
- SQL Server (valfritt)
- Elastisk SQL-pool (valfritt)
- BigData-pool
- Data Explorer (valfritt)
Information om hur du hittar de lagringsplatser som innehåller de tidigare nämnda distributionsmallarna finns i distributionsmallar för analys i molnskala