Copy-Aktivität in Azure Data Factory und Azure Synapse Analytics
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In Azure Data Factory- und Synapse-Pipelines können Sie mithilfe der Copy-Aktivität Daten zwischen lokalen Datenspeichern und Clouddatenspeichern kopieren. Nach dem Kopieren können Sie andere Aktivitäten verwenden, um die Daten weiter zu transformieren und zu analysieren. Sie können die Kopieraktivität auch zum Veröffentlichen von Transformations- und Analyseergebnissen verwenden, um sie für Business Intelligence (BI) und Anwendungen zu nutzen.
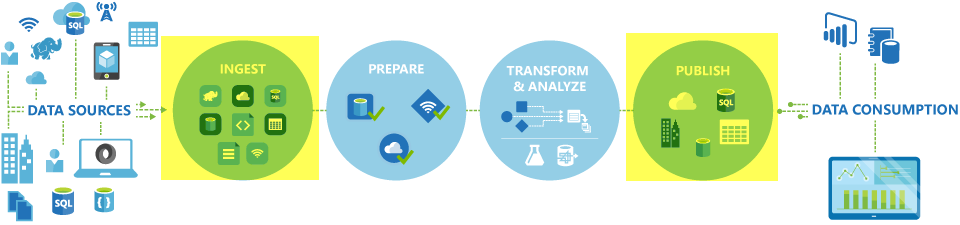
Die Kopieraktivität wird in einer Integration Runtime ausgeführt. Sie können unterschiedliche Integration Runtime-Typen für unterschiedliche Datenkopierszenarien verwenden:
- Beim Kopieren von Daten zwischen zwei Datenspeichern, die über das Internet von einer beliebigen IP-Adresse aus öffentlich zugänglich sind, können Sie die Azure Integration Runtime für die Kopieraktivität verwenden. Diese Integration Runtime ist sicher, zuverlässig, skalierbar und weltweit verfügbar.
- Beim Kopieren von Daten zwischen lokalen Datenspeichern oder Datenspeichern in einem Netzwerk mit Zugriffssteuerung (z. B. Azure Virtual Network) müssen Sie eine selbstgehostete Integration Runtime einrichten.
Eine Integration Runtime muss mit jedem Quell- und Senkendatenspeicher verknüpft werden. Informationen dazu, wie die zu verwendende Integration Runtime von der Kopieraktivität bestimmt wird, finden Sie unter Bestimmen der zu verwendenden IR.
Um Daten aus einer Quelle in eine Senke zu kopieren, führt der Dienst, der die Kopieraktivität ausführt, folgende Schritte durch:
- Er liest Daten aus einem Quelldatenspeicher.
- Er führt die Serialisierung/Deserialisierung, Komprimierung/Dekomprimierung, Spaltenzuordnung usw. durch. Diese Vorgänge erfolgen basierend auf den Konfigurationen von Eingabedataset, Ausgabedataset und Kopieraktivität.
- Er schreibt Daten in den Senken-/Zieldatenspeicher.

Hinweis
Wenn eine selbstgehostete Integration Runtime entweder im Quell- oder Senkendatenspeicher innerhalb einer Copy-Aktivität verwendet wird, muss sowohl die Quelle als auch die Senke über den Server zugänglich sein, auf dem die Integration Runtime gehostet wird, damit die Copy-Aktivität erfolgreich ist.
Unterstützte Datenspeicher und Formate
Hinweis
Sie können jeden Connector, der als Vorschauversion gekennzeichnet ist, ausprobieren und uns anschließend Feedback dazu senden. Wenden Sie sich an den Azure-Support, wenn Sie in Ihrer Lösung eine Abhängigkeit von Connectors verwenden möchten, die sich in der Vorschauphase befinden.
Unterstützte Dateiformate
Azure Data Factory unterstützt die folgenden Dateiformate. Informationen zu formatbasierten Einstellungen finden Sie in den jeweiligen Artikeln.
- Avro-Format
- Binärformat
- Textformat mit Trennzeichen
- Excel-Format
- JSON-Format
- ORC-Format
- Parquet-Format
- XML-Format
Sie können die Kopieraktivität verwenden, um Dateien unverändert zwischen zwei dateibasierten Datenspeichern zu kopieren. In diesem Fall werden die Daten effizient ohne Serialisierung oder Deserialisierung kopiert. Darüber hinaus können Sie Dateien eines bestimmten Formats analysieren oder generieren. Sie können beispielsweise folgende Vorgänge durchführen:
- Kopieren von Daten aus einer SQL Server-Datenbank und Schreiben in Azure Data Lake Storage Gen2 im Parquet-Format
- Kopieren von Dateien im Textformat (CSV) aus einem lokalen Dateisystem und Schreiben in Azure Blob Storage im Avro-Format
- Kopieren von ZIP-Dateien aus einem lokalen Dateisystem, direktes Dekomprimieren und Schreiben der extrahierten Dateien in Azure Data Lake Storage Gen2
- Kopieren von Daten im Gzip-komprimierten Textformat (CSV) aus Azure Blob Storage und Schreiben in Azure SQL-Datenbank
- Viele weitere Aktivitäten, die eine Serialisierung/Deserialisierung oder Komprimierung/Dekomprimierung erfordern
Unterstützte Regionen
Der Dienst, der die Kopieraktivität unterstützt, ist weltweit in den Regionen und Ländern verfügbar, die unter Standorte der Azure Integration Runtime aufgeführt sind. Die global verfügbare Topologie gewährleistet effiziente Datenverschiebungen, die regionsübergreifende Hops in der Regel vermeiden. Unter Produkte nach Region können Sie die Verfügbarkeit von Data Factory, Synapse-Arbeitsbereichen und der Datenverschiebung in einer bestimmten Region überprüfen.
Konfiguration
Sie können eines der folgenden Tools oder SDKs verwenden, um die Kopieraktivität mit einer Pipeline zu verwenden:
- Das Tool „Daten kopieren“
- Azure-Portal
- Das .NET SDK
- Das Python SDK
- Azure PowerShell
- Die REST-API
- Die Azure Resource Manager-Vorlage
Wenn Sie die Copy-Aktivität in Azure Data Factory- oder Synapse-Pipelines verwenden möchten, müssen Sie generell folgende Schritte ausführen:
- Erstellen Sie verknüpfte Dienste für den Quell- und Senkendatenspeicher. Sie finden die Liste der unterstützten Connectors im Abschnitt Unterstützte Datenspeicher und Formate dieses Artikels. Im Abschnitt „Eigenschaften des verknüpften Diensts“ im Connectorartikel finden Sie Informationen zur Konfiguration und zu unterstützten Eigenschaften.
- Erstellen Sie Datasets für die Quelle und die Senke. In den Abschnitten zu Dataset-Eigenschaften in den Artikeln zu Quell- und Senkenconnectors finden Sie Informationen zur Konfiguration und zu unterstützten Eigenschaften.
- Erstellen Sie eine Pipeline mit der Kopieraktivität. Der nächste Abschnitt enthält ein Beispiel.
Syntax
Die folgende Vorlage einer Kopieraktivität enthält eine vollständige Liste unterstützter Eigenschaften. Geben Sie diejenigen an, die zu Ihrem Szenario passen.
"activities":[
{
"name": "CopyActivityTemplate",
"type": "Copy",
"inputs": [
{
"referenceName": "<source dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<sink dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>",
<properties>
},
"sink": {
"type": "<sink type>"
<properties>
},
"translator":
{
"type": "TabularTranslator",
"columnMappings": "<column mapping>"
},
"dataIntegrationUnits": <number>,
"parallelCopies": <number>,
"enableStaging": true/false,
"stagingSettings": {
<properties>
},
"enableSkipIncompatibleRow": true/false,
"redirectIncompatibleRowSettings": {
<properties>
}
}
}
]
Syntaxdetails
| Eigenschaft | BESCHREIBUNG | Erforderlich? |
|---|---|---|
| type | Legen Sie für eine Kopieraktivität Copy fest. |
Ja |
| inputs | Geben Sie das Dataset an, das Sie erstellt haben und das auf die Quelldaten verweist. Die Kopieraktivität unterstützt nur eine einzelne Eingabe. | Ja |
| outputs | Geben Sie das Dataset an, das Sie erstellt haben und das auf die Senkendaten verweist. Die Kopieraktivität unterstützt nur eine einzelne Ausgabe. | Ja |
| typeProperties | Geben Sie Eigenschaften zum Konfigurieren der Kopieraktivität an. | Ja |
| source | Geben Sie den Quelltyp für den Kopiervorgang und die zugehörigen Eigenschaften zum Abrufen von Daten an. Weitere Informationen finden Sie im Abschnitt „Eigenschaften der Kopieraktivität“ im Connectorartikel unter Unterstützte Datenspeicher und Formate. |
Ja |
| sink | Geben Sie den Senkentyp für den Kopiervorgang und die zugehörigen Eigenschaften zum Schreiben von Daten an. Weitere Informationen finden Sie im Abschnitt „Eigenschaften der Kopieraktivität“ im Connectorartikel unter Unterstützte Datenspeicher und Formate. |
Ja |
| translator | Geben Sie explizite Spaltenzuordnungen von der Quelle zur Senke an. Diese Eigenschaft wird angewendet, wenn das standardmäßige Kopierverhalten nicht Ihren Anforderungen entspricht. Weitere Informationen finden Sie unter Schemazuordnung in Kopieraktivität. |
Nein |
| dataIntegrationUnits | Geben Sie eine Maßeinheit an, die festlegt, wie viel Leistung der Azure Integration Runtime für das Kopieren von Daten zur Verfügung steht. Diese Einheiten wurden früher als Einheiten für Clouddatenverschiebungen bezeichnet. Weitere Informationen finden Sie unter Datenintegrationseinheiten. |
Nein |
| parallelCopies | Geben Sie die Parallelität an, die die Kopieraktivität beim Lesen von Daten aus der Quelle und beim Schreiben von Daten in die Senke verwenden soll. Weitere Informationen finden Sie unter Paralleles Kopieren. |
Nein |
| Reservat | Legen Sie fest, ob Metadaten/Zugriffssteuerungsliste beim Kopieren von Daten beibehalten werden sollen. Weitere Informationen finden Sie unter Beibehalten von Metadaten. |
Nein |
| enableStaging stagingSettings |
Geben Sie an, ob die vorläufigen Daten im Blob Storage bereitgestellt werden, anstatt sie direkt aus der Quelle in die Senke zu kopieren. Informationen zu nützlichen Szenarien und Konfigurationsdetails finden Sie unter Gestaffeltes Kopieren. |
Nein |
| enableSkipIncompatibleRow redirectIncompatibleRowSettings |
Wählen Sie aus, wie nicht kompatible Zeilen beim Kopieren von Daten aus der Quelle in die Senke behandelt werden sollen. Weitere Informationen finden Sie unter Fehlertoleranz. |
Nein |
Überwachung
Sie können die Ausführung der Copy-Aktivität in Azure Data Factory- und Synapse-Pipelines sowohl visuell als auch programmgesteuert überwachen. Einzelheiten dazu finden Sie unter Überwachen der Kopieraktivität.
Inkrementelles Kopieren
Data Factory- und Synpase-Pipelines unterstützen das inkrementelle Kopieren von Deltadaten von einem Quelldatenspeicher in einen Senkendatenspeicher. Weitere Informationen finden Sie unter Tutorial: Inkrementelles Kopieren von Daten.
Leistung und Optimierung
In der Benutzeroberfläche zur Überwachung der Kopieraktivität werden Ihnen die Statistiken zur Kopierleistung für jede Ihrer Aktivitätsausführungen angezeigt. Im Leitfaden zur Leistung und Skalierbarkeit der Copy-Aktivität werden wichtige Faktoren beschrieben, die sich auf die Leistung der Copy-Aktivität beim Verschieben von Daten auswirken. Außerdem finden Sie dort in Tests ermittelte Leistungswerte und Möglichkeiten, die Leistung der Kopieraktivität zu optimieren.
Fortsetzen ab der letzten fehlgeschlagenen Ausführung
Die Kopieraktivität unterstützt das Fortsetzen ab der letzten fehlgeschlagenen Ausführung, wenn Sie große Dateien unverändert im Binärformat zwischen dateibasierten Speichern kopieren und sich dafür entscheiden, die Ordner-/Dateistruktur beim Kopieren von der Quelle zur Senke beizubehalten, z. B. beim Migrieren von Daten aus Amazon S3 zu Azure Data Lake Storage Gen2. Sie gilt für die folgenden dateibasierten Konnektoren: Amazon S3, Amazon S3 Compatible StorageAzure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, Oracle Cloud Storage und SFTP.
Sie können die zwei folgenden Methoden zum Fortsetzen der Kopieraktivität nutzen:
Wiederholung auf Aktivitätsebene: Sie können eine Wiederholungsanzahl für Kopieraktivitäten festlegen. Wenn die Ausführung der Kopieraktivität während der Pipelineausführung fehlschlägt, beginnt der nächste automatische Wiederholungsversuch ab dem Fehlerpunkt des letzten Versuchs.
Erneute Ausführung ab fehlgeschlagener Aktivität: Nach Abschluss der Pipelineausführung können Sie eine erneute Ausführung ab der fehlgeschlagenen Aktivität auch über die Überwachungsansicht der ADF-Benutzeroberfläche oder programmgesteuert auslösen. Wenn es sich bei der fehlerhaften Aktivität um eine Kopieraktivität handelt, wird die Pipeline nicht nur ab dieser Aktivität noch mal ausgeführt, sie wird auch ab dem Fehlerpunkt der vorherigen Ausführung fortgesetzt.
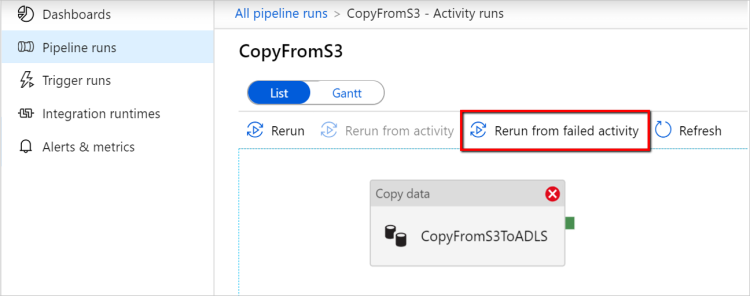
Beachten Sie Folgendes:
- Die Fortsetzung erfolgt auf Dateiebene. Wenn die Kopieraktivität beim Kopieren einer Datei fehlschlägt, wird diese Datei bei der nächsten Ausführung erneut kopiert.
- Ändern Sie die Einstellungen der Kopieraktivität zwischen wiederholten Ausführungen nicht, damit die Fortsetzung ordnungsgemäß funktioniert.
- Beim Kopieren von Daten aus Amazon S3, Azure Blob Storage, Azure Data Lake Storage Gen2 und Google Cloud Storage kann die Kopieraktivität ab einer beliebigen Anzahl kopierter Dateien fortgesetzt werden. Die Kopieraktivität unterstützt die Fortsetzung bei Verwendung der restlichen dateibasierten Connectors als Quelle zwar bis zu einer begrenzten Anzahl von Dateien, jedoch handelt es sich dabei meist um Zehntausende Dateien, je nachdem, wie lang die Dateipfade sind. Dateien ab diesem Schwellenwert werden bei wiederholten Ausführungen erneut kopiert.
Bei anderen Szenarios als beim Kopieren von Binärdateien beginnt die erneute Ausführung der Kopieraktivität von Anfang an.
Beibehalten von Metadaten zusammen mit Daten
Beim Kopieren von Daten aus einer Quelle in eine Senke können Sie in Szenarios wie der Data Lake-Migration festlegen, dass Metadaten und Zugriffssteuerungslisten bei der Kopieraktivität mit den Daten beibehalten werden sollen. Ausführliche Informationen hierzu finden Sie unter Beibehalten von Metadaten.
Hinzufügen von Metadatentags zu einer dateibasierten Senke
Wenn die Senke auf Azure Storage basiert (Azure Data Lake Storage oder Azure Blob Storage), können Sie den Dateien Metadaten hinzufügen. Diese Metadaten werden als Teil der Dateieigenschaften als Schlüssel-Wert-Paare angezeigt. Sie können für alle Typen von dateibasierten Senken Metadaten hinzufügen, die dynamische Inhalte umfassen, indem Sie die Pipelineparameter, Systemvariablen, Funktionen und Variablen verwenden. Darüber hinaus haben Sie bei binärdateibasierten Senken die Möglichkeit, der Senkendatei mit dem Schlüsselwort $$LASTMODIFIED einen datetime-Wert für den Zeitpunkt der letzten Änderung (der Quelldatei) sowie benutzerdefinierte Werte als Metadaten hinzuzufügen.
Schema- und Datentypzuordnung
Informationen dazu, wie die Quelldaten von der Kopieraktivität der Senke zugeordnet werden, finden Sie unter Schema- und Datentypzuordnung.
Hinzufügen zusätzlicher Spalten während des Kopiervorgangs
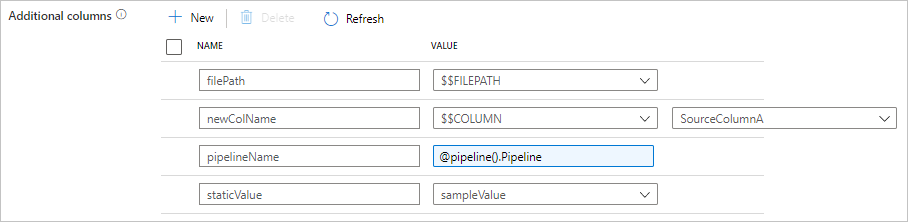
Über das Kopieren von Daten aus dem Quelldatenspeicher in die Senke hinaus können Sie auch so konfigurieren, dass zusätzliche Datenspalten zum Kopieren in die Senke hinzugefügt werden. Beispiel:
- Beim Kopieren aus einer dateibasierten Quelle speichern Sie den relativen Dateipfad als zusätzliche Spalte, in der Sie verfolgen können, aus welcher Datei die Daten stammen.
- Duplizieren Sie die angegebene Quellspalte als eine andere Spalte.
- Fügen Sie eine Spalte mit ADF-Ausdruck hinzu, um ADF-Systemvariablen wie „pipeline name/pipeline ID“ anzufügen oder einen anderen dynamischen Wert aus der Ausgabe der Upstreamaktivität zu speichern.
- Fügen Sie eine Spalte mit statischem Wert hinzu, um Ihren Bedarf an Downstreamnutzung zu erfüllen.
Auf der Registerkarte „Quelle der Kopieraktivität“ finden Sie die folgende Konfiguration. Sie können diese zusätzlichen Spalten auch wie gewohnt in der Schemazuordnung der Kopieraktivität zuordnen, indem Sie die definierten Spaltennamen verwenden.
Tipp
Dieses Feature funktioniert nur beim neuesten Datasetmodell. Wenn diese Option auf der Benutzeroberfläche nicht angezeigt wird, versuchen Sie, ein neues Dataset zu erstellen.
Wenn es programmgesteuert konfiguriert werden soll, fügen Sie in Ihrer Quelle für die Kopieraktivität die Eigenschaft additionalColumns hinzu:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| additionalColumns | Fügen Sie zusätzliche Datenspalten zum Kopieren in die Senke hinzu. Jedes Objekt unter dem Array additionalColumns stellt eine zusätzliche Spalte dar. name definiert den Spaltennamen, und value gibt den Datenwert dieser Spalte an.Zulässige Datenwerte sind: - $$FILEPATH – eine reservierte Variable, die angibt, dass der relative Pfad der Quelldateien in dem im Dataset angegebenen Ordnerpfad gespeichert werden soll. Auf dateibasierte Quelle anwenden.- $$COLUMN:<source_column_name> – ein reserviertes Variablenmuster gibt an, dass die angegebene Quellspalte als eine andere Spalte dupliziert wird.- Ausdruck - Statischer Wert |
Nein |
Beispiel:
"activities":[
{
"name": "CopyWithAdditionalColumns",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "<source type>",
"additionalColumns": [
{
"name": "filePath",
"value": "$$FILEPATH"
},
{
"name": "newColName",
"value": "$$COLUMN:SourceColumnA"
},
{
"name": "pipelineName",
"value": {
"value": "@pipeline().Pipeline",
"type": "Expression"
}
},
{
"name": "staticValue",
"value": "sampleValue"
}
],
...
},
"sink": {
"type": "<sink type>"
}
}
}
]
Tipp
Nachdem Sie zusätzliche Spalten konfiguriert haben, müssen Sie sie auf der Registerkarte „Zuordnung“ der Zielsenke zuordnen.
Automatisches Erstellen von Senkentabellen
Wenn beim Kopieren von Daten in SQL-Datenbank/Azure Synapse Analytics die Zieltabelle nicht vorhanden ist, unterstützt die Copy-Aktivität ihre automatische Erstellung basierend auf den Quelldaten. Das soll Ihnen helfen, schnell mit dem Laden der Daten und dem Evaluieren von SQL-Datenbank/Azure Synapse Analytics zu beginnen. Nach der Datenerfassung können Sie das Schema der Senkentabelle überprüfen und Ihren Anforderungen entsprechend anpassen.
Diese Funktion wird unterstützt, wenn Daten aus einer beliebigen Quelle in die folgenden Senkendatenspeicher kopiert werden. Die Option finden Sie unter Benutzeroberfläche für die ADF-Dokumentenerstellung –>Copy activity sink (Senke der Copy-Aktivität) –>Tabellenoption –>Auto create table (Tabelle automatisch erstellen) oder über die Eigenschaft tableOption in der Senkennutzlast der Copy-Aktivität.

Fehlertoleranz
Wenn Datenzeilen in der Quelle und in der Senke nicht kompatibel sind, wird ein Fehler zurückgegeben, und der Kopiervorgang wird von der Kopieraktivität standardmäßig beendet. Damit der Kopiervorgang erfolgreich verläuft, können Sie die Kopieraktivität so konfigurieren, dass nicht kompatible Zeilen übersprungen und protokolliert werden und nur die kompatiblen Daten kopiert werden. Weitere Details finden Sie unter Fehlertoleranz der Kopieraktivität.
Datenkonsistenzprüfung
Wenn Sie Daten aus dem Quell- in den Zielspeicher verschieben, bietet die Copy-Aktivität eine Option, mit der Sie eine zusätzliche Datenkonsistenzprüfung durchführen können. Damit stellen Sie sicher, dass die Daten nicht nur erfolgreich aus dem Quell- in den Zielspeicher kopiert werden, sondern auch dass überprüft wird, ob sie zwischen Quell- und Zielspeicher konsistent sind. Wenn während der Datenverschiebung inkonsistente Dateien gefunden werden, können Sie entweder die Kopieraktivität abbrechen oder auch noch die restlichen Dateien kopieren. Hierzu aktivieren Sie die Einstellung für Fehlertoleranz, damit inkonsistente Daten übersprungen werden. Die Namen der übersprungenen Dateien können Sie durch Aktivieren der Einstellung für das Sitzungsprotokoll in der Kopieraktivität abrufen. Ausführliche Informationen finden Sie unter Datenkonsistenzprüfung in der Kopieraktivität.
Sitzungsprotokoll
Sie können die kopierten Dateinamen protokollieren, um sicherzustellen, dass die Daten nicht nur erfolgreich aus dem Quell- in den Zielspeicher kopiert werden, sondern auch zwischen Quell- und Zielspeicher konsistent sind. Dazu überprüfen Sie die Sitzungsprotokolle der Kopieraktivität. Ausführliche Informationen finden Sie unter Sitzungsprotokoll in einer Copy-Aktivität.
Zugehöriger Inhalt
Weitere Informationen finden Sie in den folgenden Schnellstartanleitungen, Tutorials und Beispielen: