Einrichten von Clustern in HDInsight mit Apache Hadoop, Apache Spark, Apache Kafka usw.
Erfahren Sie, wie Sie Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query oder Apache HBase in HDInsight einrichten und konfigurieren. Darüber hinaus lernen Sie Cluster anzupassen und Sicherheit hinzuzufügen, indem Sie sie mit einer Domäne verknüpfen.
Ein Hadoop-Cluster besteht aus mehreren virtuellen Computern (Knoten), die zur verteilten Verarbeitung von Aufgaben verwendet werden. Azure HDInsight verwaltet die Implementierungsdetails der Installation und Konfiguration einzelner Knoten, sodass Sie nur allgemeine Konfigurationsinformationen bereitstellen müssen.
Wichtig
Die Abrechnung für einen HDInsight-Cluster beginnt, sobald der Cluster erstellt wurde, und endet mit dem Löschen des Clusters. Die Gebühren werden anteilig nach Minuten erhoben. Daher sollten Sie Ihren Cluster immer löschen, wenn Sie ihn nicht mehr verwenden. Erfahren Sie, wie Sie einen Cluster löschen.
Bei gemeinsamer Verwendung mehrerer Cluster empfiehlt sich die Erstellung eines virtuellen Netzwerks. Bei Verwendung eines Spark-Clusters sollten Sie den Hive Warehouse Connector verwenden. Weitere Informationen finden Sie unter Planen eines virtuellen Netzwerks für Azure HDInsight sowie unter Integrieren von Apache Spark und Apache Hive per Hive Warehouse Connector.
Methoden für die Clustereinrichtung
Die folgende Tabelle zeigt die verschiedenen Methoden, die Sie zum Einrichten eines HDInsight-Clusters verwenden können.
| Verfahren zur Clustererstellung | Webbrowser | Befehlszeile | REST-API | SDK |
|---|---|---|---|---|
| Azure portal | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Azure-Befehlszeilenschnittstelle | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Azure-Ressourcen-Manager-Vorlagen | ✅ |
Dieser Artikel enthält die Schritte im Azure-Portal zum Erstellen eines HDInsight-Clusters.
Grundlagen
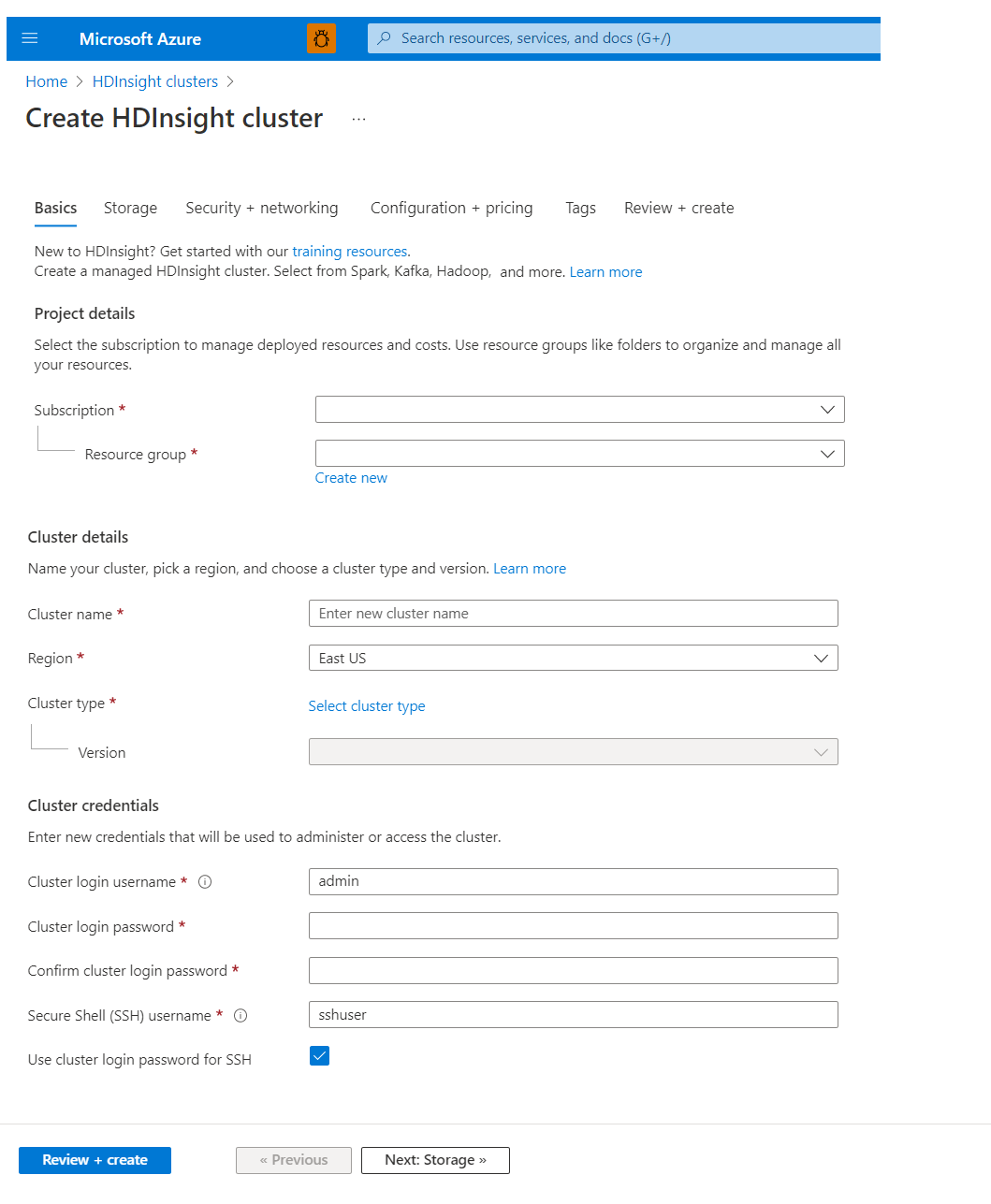
Projektdetails
Mit Azure Resource Manager können Sie mit den Ressourcen in Ihrer Anwendung als Gruppe arbeiten, was als Azure-Ressourcengruppe bezeichnet wird. Sie können alle Ressourcen für Ihre Anwendung in einem einzigen, koordinierten Vorgang bereitstellen, aktualisieren, überwachen oder löschen.
Clusterdetails
Clustername
Für Namen von HDInsight-Clustern gelten folgende Einschränkungen:
- Zulässige Zeichen: a-z, 0–9, A-Z
- Max. Länge: 59
- Reservierte Namen: apps
- Der Benennungsbereich des Clusters gilt überall in Azure und in allen Abonnements. Der Clustername muss somit weltweit eindeutig sein.
- Die ersten sechs Zeichen müssen innerhalb eines virtuellen Netzwerks eindeutig sein.
Region
Sie müssen den Clusterstandort nicht explizit angeben: Der Cluster befindet sich an derselben Position wie der Standardspeicher. Um eine Liste der unterstützten Regionen zu erhalten, wählen Sie in der Dropdownliste Region die Option HDInsight-Preise aus.
Clustertyp
Azure HDInsight bietet derzeit die folgenden Typen von Clustern mit je einer Reihe von Komponenten, um bestimmte Funktionen bereitzustellen.
Wichtig
HDInsight-Cluster sind jeweils für einzelne Workloads oder Technologien in verschiedenen Typen verfügbar. Es ist keine unterstützte Methode zum Erstellen eines Clusters vorhanden, bei der mehrere Typen kombiniert werden, z. B. HBase in einem Cluster. Wenn für Ihre Lösung Technologien erforderlich sind, die auf mehrere HDInsight-Clustertypen verteilt sind, können Sie die erforderlichen Clustertypen über ein virtuelles Azure-Netzwerk miteinander verbinden.
| Clustertyp | Funktionalität |
|---|---|
| Hadoop | Batch-Abfragen und -analysen gespeicherter Daten |
| HBase | Verarbeitung großen Mengen von schemalosen NoSQL-Daten |
| Interactive Query | Interaktive und schnellere Hive-Abfragen durch speicherinternes Caching |
| Kafka | Dies ist eine verteilte Open-Source-Streamingplattform, die zum Erstellen von Datenpipelines und Anwendungen mit Echtzeitstreaming verwendet werden kann. |
| Spark | Arbeitsspeicherinterne Verarbeitung, interaktive Abfragen, Microbatch-Datenstromverarbeitung |
Version
Wählen Sie die Version von HDInsight für diesen Cluster aus. Weitere Informationen finden Sie unter Unterstützte HDInsight-Versionen.
Clusteranmeldeinformationen
Während der Clustererstellung ermöglichen die HDInsight-Cluster Ihnen das Konfigurieren von zwei Benutzerkonten:
- Benutzername für Clusteranmeldung: Der Standard-Benutzername lautet admin. Für ihn gilt im Azure-Portal die Standardkonfiguration. Er wird manchmal auch als „Clusterbenutzer“ oder „HTTP-Benutzer“ bezeichnet.
- Secure Shell-Benutzername (SSH): Wird verwendet, um die Verbindung mit dem Cluster über SSH herzustellen. Weitere Informationen finden Sie unter Verwenden von SSH mit Linux-basiertem Hadoop in HDInsight unter Linux, Unix oder OS X.
Für den HTTP-Benutzernamen gelten folgende Einschränkungen:
- Zulässige Sonderzeichen:
_und@ - Unzulässige Zeichen:
#;."',/:!*?$(){}[]<>|&--=+%~^space` - Max. Länge: 20
Für den SSH-Benutzernamen gelten folgende Einschränkungen:
- Zulässige Sonderzeichen:
_und@ - Unzulässige Zeichen:
#;."',/:!*?$(){}[]<>|&--=+%~^space` - Max. Länge: 64
- Reservierte Namen: hadoop, users, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a,
actuser, adm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Storage
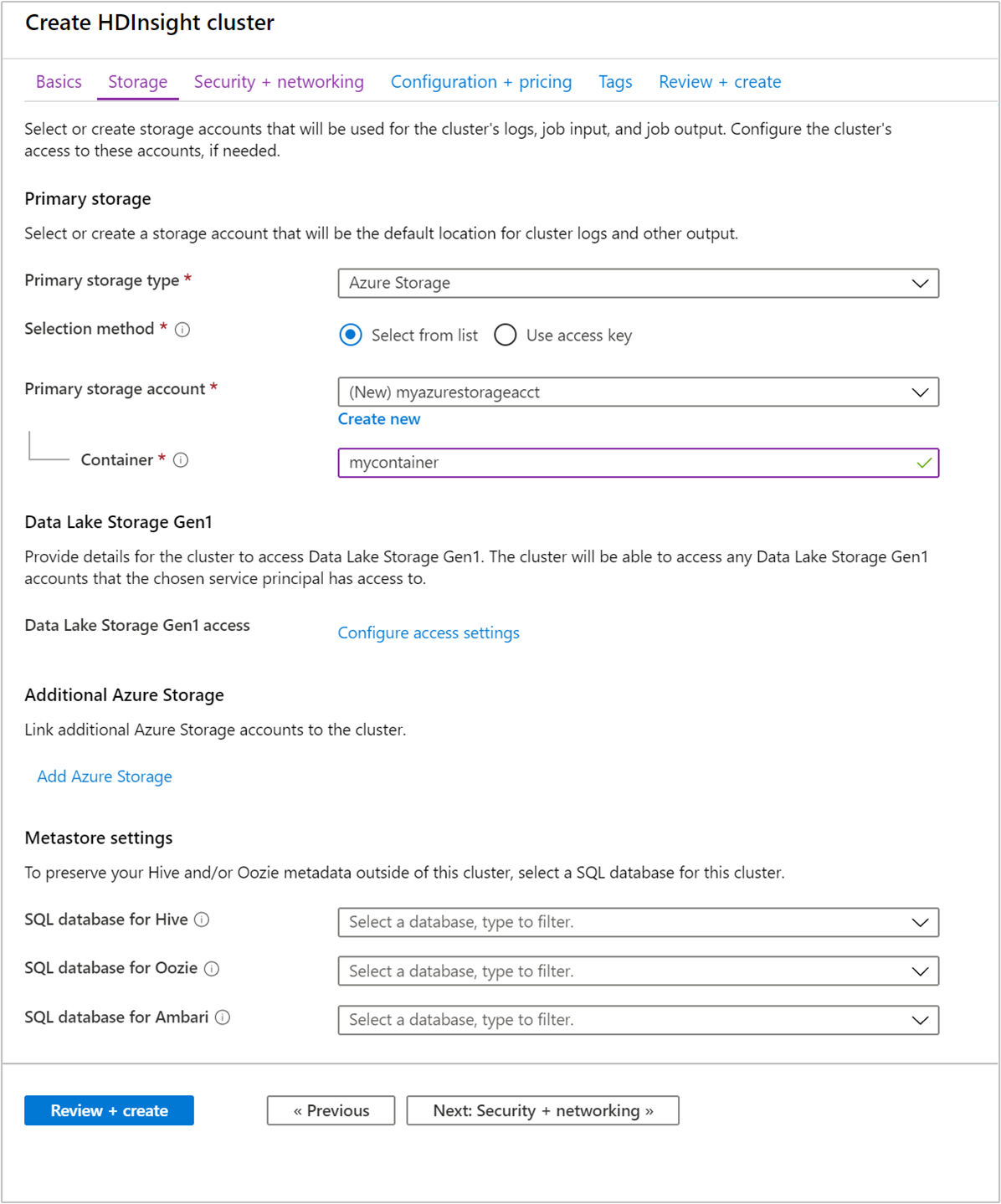
Obwohl eine lokale Installation von Hadoop das Hadoop Distributed File System (HDFS) für die Speicherung im Cluster verwendet, nutzen Sie in der Cloud Speicherendpunkte, die mit dem Cluster verbunden sind. Durch Verwendung von Cloudspeicher können Sie die für Berechnungen verwendeten HDInsight-Cluster sicher löschen und gleichzeitig Ihre Daten beibehalten.
HDInsight-Cluster können die folgenden Speicheroptionen verwenden:
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Azure Storage vom Typ „Allgemein v2“
- Azure Storage vom Typ „Allgemein v1“
- Azure Storage-Blockblob (nur als sekundärer Speicher unterstützt)
Weitere Informationen zu Speicheroptionen mit HDInsight finden Sie unter Vergleich der Speicheroptionen für die Verwendung mit Azure HDInsight-Clustern.
Warnung
Die Verwendung eines zusätzlichen Speicherkontos an einem anderen Ort als dem HDInsight-Cluster wird nicht unterstützt.
Während der Konfiguration geben Sie für den Standardspeicherendpunkt einen Blobcontainer für ein Azure-Speicherkonto oder eine Data Lake Storage-Instanz an. Der Standardspeicher enthält Anwendungs- und Systemprotokolle. Optional können Sie zusätzliche verknüpfte Azure-Speicherkonten und Data Lake Storage-Konten angeben, auf die der Cluster zugreifen kann. Der HDInsight-Cluster und die abhängigen Speicherkonten müssen sich an demselben Azure-Standort befinden.
Hinweis
Das Feature, das eine sichere Übertragung vorschreibt, erzwingt eine sichere Verbindung für alle Anforderungen, die an Ihr Konto gerichtet werden. Dieses Feature wird erst ab HDInsight-Clusterversion 3.6 unterstützt. Weitere Informationen finden Sie unter Erstellen von Apache Hadoop-Clustern mit Speicherkonten mit sicherer Übertragung in Azure HDInsight.
Wichtig
Das Aktivieren der sicheren Speicherübertragung nach dem Erstellen eines Clusters kann zu Fehlern bei der Verwendung Ihres Speicherkontos führen und wird daher nicht empfohlen. Es ist besser, einen neuen Cluster mit einem Speicherkonto zu erstellen, bei dem die sichere Übertragung bereits aktiviert ist.
Hinweis
Azure HDInsight überträgt, verschiebt oder kopiert Ihre in Azure Storage gespeicherten Daten nicht automatisch zwischen Regionen.
Metastore-Einstellungen
Sie können optionale Hive- oder Apache Oozie Metastores erstellen. Allerdings unterstützen nicht alle Clustertypen Metastores, und Azure Synapse Analytics ist nicht mit Metastores kompatibel.
Weitere Informationen finden Sie unter Verwenden von externen Metadatenspeichern in Azure HDInsight.
Wichtig
Verwenden Sie beim Erstellen eines benutzerdefinierten Metastores keinen Datenbanknamen, der Gedankenstriche, Bindestriche oder Leerzeichen enthält. Dies kann dazu führen, dass der Clustererstellungsprozess fehlschlägt.
SQL-Datenbank für Hive
Verwenden Sie einen benutzerdefinierten Metastore, wenn Sie nach dem Löschen des HDInsight-Clusters Ihre Hive-Tabellen beibehalten möchten. Sie können diesen Metastore anschließend an einen anderen HDInsight-Cluster anfügen.
Ein HDInsight-Metastore, der für eine HDInsight-Clusterversion erstellt wurde, kann nicht über verschiedene HDInsight-Clusterversionen freigegeben werden. Eine Liste mit den HDInsight-Versionen finden Sie unter Unterstützte HDInsight-Versionen.
Wichtig
Der Standardmetastore stellt eine Azure SQL-Datenbank mit einem Basic-Tarif mit einer Begrenzung auf fünf DTUs (nicht aktualisierbar) bereit. Er eignet sich für grundlegende Testzwecke. Bei großen Workloads bzw. Produktionsworkloads empfiehlt sich die Migration zu einem externen Metastore.
SQL-Datenbank für Oozie
Verwenden Sie zur Erhöhung der Leistung bei Verwendung von Oozie einen benutzerdefinierten Metastore. Ein Metastore kann auch Zugriff auf Oozie-Auftragsdaten bieten, nachdem Sie Ihren Cluster gelöscht haben.
SQL-Datenbank für Ambari
Ambari wird zum Überwachen von HDinsight-Clustern, Vornehmen von Konfigurationsänderungen und Speichern von Informationen zur Clusterverwaltung sowie zum Auftragsverlauf verwendet. Mit der Funktion der benutzerdefinierten Ambari-Datenbank können Sie einen neuen Cluster bereitstellen und Ambari in einer externen Datenbank einrichten, die Sie verwalten. Weitere Informationen finden Sie unter Einrichten von HDInsight-Clustern mit einer benutzerdefinierten Ambari-Datenbank.
Wichtig
Ein benutzerdefinierter Oozie-Metastore kann nicht wiederverwendet werden. Wenn Sie einen benutzerdefinierten Oozie-Metastore verwenden möchten, müssen Sie beim Erstellen des HDInsight-Clusters eine leere Azure SQL-Datenbank bereitstellen.
Sicherheit + Netzwerkbetrieb

Sicherheitspaket für Unternehmen
Für Cluster der Typen Hadoop, Spark, HBase, Kafka und Interactive Query können Sie das Enterprise-Sicherheitspaket aktivieren. Dieses Paket bietet die Möglichkeit, mithilfe von Apache Ranger und der Integration in Microsoft Entra ID eine sicherere Clustereinrichtung zu erreichen. Weitere Informationen finden Sie unter Übersicht über die Unternehmenssicherheit in Azure HDInsight.
Mit dem Sicherheitspaket für Unternehmen können Sie HDInsight mit Active Directory und Apache Ranger integrieren. Mithilfe des Enterprise-Sicherheitspakets können mehrere Benutzer erstellt werden.
Weitere Informationen zum Erstellen eines in eine Domäne eingebundenen HDInsight-Clusters finden Sie unter Erstellen einer in eine Domäne eingebundenen HDInsight-Sandboxumgebung.
TLS
Weitere Informationen finden Sie unter Transport Layer Security.
Virtuelles Netzwerk
Wenn für Ihre Lösung Technologien erforderlich sind, die auf mehrere HDInsight-Clustertypen verteilt sind, können Sie die erforderlichen Clustertypen über ein virtuelles Azure-Netzwerk miteinander verbinden. Durch diese Konfiguration können die Cluster und der gesamte Code, den Sie dafür bereitstellen, direkt miteinander kommunizieren.
Weitere Informationen zur Verwendung eines virtuellen Azure-Netzwerks mit HDInsight finden Sie unter Planen eines virtuellen Netzwerks für HDInsight.
Ein Beispiel für die Verwendung von zwei Clustertypen in einem virtuellen Azure-Netzwerk finden Sie unter Verwenden von strukturiertem Apache Spark-Streaming mit Apache Kafka. Weitere Informationen zur Verwendung von HDInsight mit einem virtuellen Netzwerk, einschließlich spezifischer Konfigurationsanforderungen für das virtuelle Netzwerk, finden Sie unter Planen eines virtuellen Netzwerks für HDInsight.
Datenträgerverschlüsselungs-Einstellung
Weitere Informationen finden Sie unter Datenträgerverschlüsselung mit kundenseitig verwalteten Schlüsseln.
Kafka-REST-Proxy
Diese Einstellung ist nur für den Clustertyp Kafka verfügbar. Weitere Informationen finden Sie unter Interagieren mit Apache Kafka-Clustern in Azure HDInsight mithilfe eines REST-Proxys.
Identity
Weitere Informationen finden Sie unter Verwaltete Identitäten in Azure HDInsight.
Konfiguration + Preise
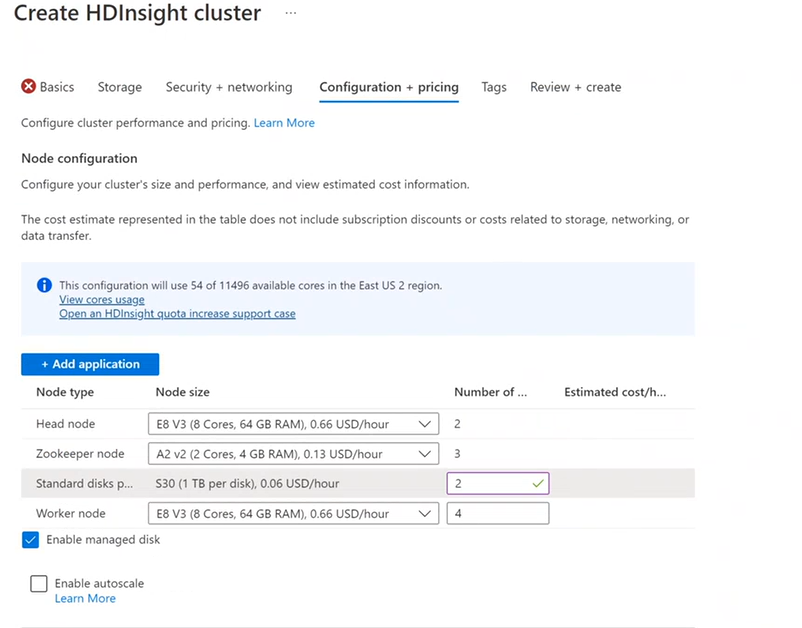
Die Verwendung der Knoten wird so lange abgerechnet, wie der Cluster vorhanden ist. Die Abrechnung beginnt, sobald ein Cluster erstellt wurde, und sie endet, wenn der Cluster gelöscht wird. Bei Clustern ist kein Aufheben der Zuweisung oder ein Anhalten möglich.
Knotenkonfiguration
Jeder Clustertyp verfügt über eine eigene Anzahl von Knoten, Terminologie für Knoten und eine VM-Standardgröße. In der folgenden Tabelle ist die Anzahl von Knoten für jeden Knotentyp jeweils in Klammern angegeben.
| type | Nodes | Diagramm |
|---|---|---|
| Hadoop | Hauptknoten (2), Workerknoten (1+) | 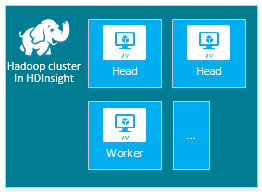
|
| hbase | Hauptserver (2), Regionsserver (1+), Master-/Zookeeper-Knoten (3) | 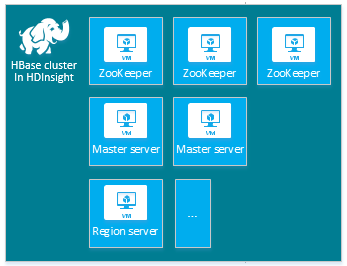
|
| Spark | Hauptknoten (2), Workerknoten (1+), ZooKeeper-Knoten (3) (kostenlos für ZooKeeper-VMs der Größe A1) | 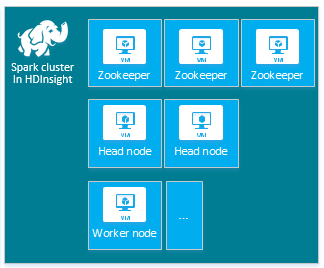
|
Weitere Informationen finden Sie unter Standardknotenkonfiguration und VM-Größen für Cluster in „Welche Hadoop-Komponenten und -Versionen gibt es in HDInsight?“.
Die Kosten von HDInsight-Clustern ergeben sich aus der Anzahl der Knoten und aus der Größe der virtuellen Computer für die Knoten.
Unterschiedliche Clustertypen weisen verschiedene Knotentypen, eine unterschiedliche Anzahl von Knoten sowie verschiedene Knotengrößen auf:
- Hadoop-Standardclustertyp:
Zwei Hauptknoten
Vier Workerknoten
Wenn Sie HDInsight gerade erst testen, sollten Sie nur einen einzigen Workerknoten verwenden. Weitere Informationen zu den Preisen von HDInsight finden Sie unter HDInsight – Preise.
Hinweis
Die Begrenzung der Clustergröße variiert je nach Azure-Abonnement. Wenden Sie sich an den Azure-Abrechnungssupport, um diese Begrenzung zu erhöhen.
Wenn Sie das Azure-Portal zum Konfigurieren des Clusters verwenden, ist die Knotengröße über die Registerkarte Configuration + Pricing (Konfiguration + Preise) verfügbar. Außerdem werden im Portal die Kosten angezeigt, die den unterschiedlichen Knotengrößen zugeordnet sind.
Größen virtueller Computer
Wählen Sie bei der Bereitstellung von Clustern die Computeressourcen basierend auf der Lösung aus, die Sie bereitstellen möchten. Für HDInsight-Cluster werden die folgenden virtuellen Computer verwendet:
- VMs der Serien A und D1–4: Größen universeller Linux-VMs
- VMs der Serien D11–14: Größen speicheroptimierter Linux-VMs
Wenn Sie wissen möchten, welchen Wert Sie beim Erstellen eines Clusters mithilfe unterschiedlicher SDKs oder von Azure PowerShell als VM-Größe angeben sollten, lesen Sie unter VM-Größen für HDInsight-Cluster nach. Verwenden Sie im verknüpften Artikel in den Tabellen den Wert in der Spalte Größe.
Wichtig
Wenn Sie mehr als 32 Workerknoten in einem Cluster benötigen, müssen Sie eine Hauptknotengröße von mindestens 8 Kernen und 14 GB Arbeitsspeicher (RAM) auswählen.
Weitere Informationen finden Sie unter Größen für virtuelle Computer. Informationen zu den Preisen der unterschiedlichen Größen finden Sie unter HDInsight-Preise.
Anhängen von Datenträgern
Hinweis
Die hinzugefügten Datenträger werden nur für lokale Knotenmanagerverzeichnisse und nicht für Datenknotenverzeichnisse konfiguriert
Ein HDInsight-Cluster weist einen vordefinierten SKU-basierenden Speicherplatz auf. Das Ausführen einiger großer Anwendungen kann zu unzureichendem Speicherplatz mit einer Fehlermeldung „Voller Datenträger“ – LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE und Auftragsfehlern führen.
Weitere Datenträger können dem Cluster mithilfe des lokalen Verzeichnisses des neuen Features NodeManager (Knoten-Manager) hinzugefügt werden. Zum Zeitpunkt der Erstellung des Hive- und Spark-Clusters kann die Anzahl der Datenträger ausgewählt und den Workerknoten hinzugefügt werden. Der ausgewählte Datenträger, der jeweils 1 TB groß ist, wäre dann Teil der lokalen Verzeichnisse von NodeManager.
- Gehen Sie auf der Registerkarte Konfiguration + Preise folgendermaßen vor:
- Wählen Sie die Option Verwaltete Datenträger aktivieren aus.
- Geben Sie unter Standarddatenträger die Anzahl der Datenträger ein.
- Wählen Sie Ihren Workerknoten aus.
Sie können die Anzahl der Datenträger auf der Registerkarte Überprüfen + Erstellen unter Clusterkonfiguration überprüfen.
Anwendung hinzufügen
Eine HDInsight-Anwendung ist eine Anwendung, die von Benutzern in einem Linux-basierten HDInsight-Cluster installiert werden kann. Sie können Anwendungen von Microsoft, Anwendungen von Drittanbietern oder selbst entwickelte Anwendungen verwenden. Weitere Informationen finden Sie unter Installieren von Apache Hadoop-Anwendungen von Drittanbietern in Azure HDInsight.
Die meisten HDInsight-Anwendungen werden auf einem leeren Edgeknoten installiert. Ein leerer Edgeknoten ist ein virtueller Linux-Computer, auf dem die gleichen Clienttools installiert und konfiguriert sind wie im Hauptknoten. Sie können den Edgeknoten zum Zugreifen auf den Cluster sowie zum Testen und Hosten Ihrer Clientanwendungen verwenden. Weitere Informationen finden Sie unter Use empty edge nodes in HDInsight(Verwenden leerer Edgeknoten in HDInsight).
Skriptaktionen
Sie können zusätzliche Komponenten installieren oder die Clusterkonfiguration mithilfe von Skripts während der Erstellung anpassen. Diese Skripts werden mithilfe der Konfigurationsoption Skriptaktionaufgerufen, die vom Azure-Verwaltungsportal, von HDInsight Windows PowerShell-Cmdlets oder dem HDInsight .NET SDK verwendet werden kann. Weitere Informationen finden Sie unter Anpassen eines HDInsight-Clusters mithilfe von Skriptaktionen.
Einige systemeigene Java-Komponenten wie Apache Mahout und Cascading können auf dem Cluster als JAR-Dateien (Java Archive) ausgeführt werden. Diese JAR-Dateien können an Azure Storage verteilt und mit den Verfahren zur Übermittlung von Hadoop-Aufträgen an HDInsight-Cluster gesendet werden. Weitere Informationen finden Sie unter Programmgesteuerte Übermittlung von Apache Hadoop-Aufträgen.
Hinweis
Wenn bei der Bereitstellung von JAR-Dateien für HDInsight-Cluster oder beim Aufrufen von JAR-Dateien für HDInsight-Cluster Probleme auftreten, wenden Sie sich an den Microsoft-Support.
Cascading wird von HDInsight nicht unterstützt, und es steht kein Microsoft-Support dafür zur Verfügung. Listen der unterstützten Komponenten finden Sie unter Neuheiten in den von HDInsight bereitgestellten Clusterversionen.
Es kann vorkommen, dass Sie die folgenden Konfigurationsdateien während des Erstellungsprozesses bearbeiten möchten:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Weitere Informationen finden Sie unter Anpassen von HDInsight-Clustern mithilfe von Bootstrap.